
摘 要: 目前常用的個(gè)性化推薦系統(tǒng)模型通常是基于協(xié)同過濾或者是基于內(nèi)容的,也有部分基于關(guān)聯(lián)規(guī)則的。這些算法沒有考慮事務(wù)間的順序,然而在很多應(yīng)用中這樣的順序很重要。文章提出了一種簡易的基于序列模式的推薦模型,并且考慮到大規(guī)模數(shù)據(jù)的處理,結(jié)合了MapReduce編程模型。這種簡易的推薦模型可以用來輔助通常的個(gè)性化推薦系統(tǒng)。
關(guān)鍵詞: 推薦系統(tǒng);序列規(guī)則;MapReduce
21世紀(jì)以來,隨著互聯(lián)網(wǎng)的飛速發(fā)展,人類已經(jīng)進(jìn)入信息社會的時(shí)代。互聯(lián)網(wǎng)對人們的生活影響越來越大,越來越多的人通過互聯(lián)網(wǎng)發(fā)布和查找信息,網(wǎng)絡(luò)成為了人們生活中必不可少的一部分,也成為信息制造、發(fā)布、處理和加工的主要平臺。現(xiàn)如今,互聯(lián)網(wǎng)已經(jīng)逐漸參與到人們工作、生活、學(xué)習(xí)的各個(gè)方面,成為人們獲取所需信息、進(jìn)行學(xué)習(xí)工作和信息交流的主要場所,并對人們的生活和社會的發(fā)展產(chǎn)生了巨大影響。
個(gè)性化推薦系統(tǒng)是一種以海量數(shù)據(jù)挖掘?yàn)榛A(chǔ)的智能平臺,這個(gè)平臺借助于電子商務(wù)網(wǎng)站來為顧客提供因人而異的個(gè)性化決策支持和信息服務(wù)。個(gè)性化推薦系統(tǒng)逐漸地被應(yīng)用于各種商業(yè)網(wǎng)站,它因人而異地根據(jù)每個(gè)用戶的喜好主動地為其預(yù)測、推薦符合需求的商品,從這一點(diǎn)上彌補(bǔ)了信息系統(tǒng)的不足。隨著個(gè)性化推薦系統(tǒng)的不斷完善,各種算法被深入研究。目前最常用的推薦模型是以協(xié)同過濾為基礎(chǔ)的。盡管基于協(xié)同過濾算法的應(yīng)用比較成熟,但它有著自身固有的缺點(diǎn)[1],這使得它需要與其他方法結(jié)合使用。
本文第1部分介紹了MapReduce編程模型,第2部分描述了一種簡易的基于序列模式的推薦系統(tǒng)的框架,第3部分介紹該框架在MapReduce模型下的實(shí)現(xiàn),最后在總結(jié)部分提出了該框架的不足及需要改進(jìn)的地方。
1 MapReduce編程模型
2004 年,谷歌發(fā)表論文向全世界介紹了GFS[2]和MapReduce[3]等模型,為大規(guī)模并行數(shù)據(jù)的計(jì)算和分析提供了重要的參考。MapReduce編程模型通過顯式的網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)盡力保留網(wǎng)絡(luò)帶寬,并盡量在計(jì)算節(jié)點(diǎn)上存儲數(shù)據(jù),以實(shí)現(xiàn)數(shù)據(jù)的本地快速訪問,從而帶來了良好的整體性能。
MapReduce的設(shè)計(jì)靈感來自于Lisp等函數(shù)式編程語言中的map和reduce原語,相應(yīng)的map和reduce函數(shù)由用戶負(fù)責(zé)編寫,它們通常遵循如下常規(guī)格式:
Map:(K1,V1)→list(K2,V2)
Reduce:(K2,list(V2))→list(K3,V3)
具體的MapReduce操作流程如圖1所示。
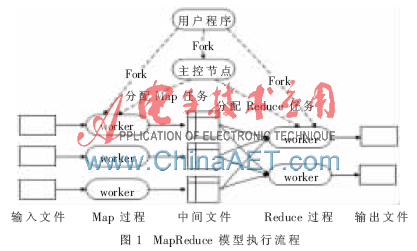
對圖1中的流程可以描述如下:
(1)用戶程序利用MapReduce相關(guān)接口先把輸入文件劃分為若干份,每一份的大小根據(jù)其分布式文件系統(tǒng)的塊的大小進(jìn)行設(shè)定,然后使用fork在系統(tǒng)中創(chuàng)建主控進(jìn)程(master)和工作進(jìn)程(worker)。
(2)主控進(jìn)程負(fù)責(zé)調(diào)度,為空閑worker分配作業(yè)(Map作業(yè)或者Reduce作業(yè))。主控進(jìn)程根據(jù)輸入文件的劃分分配相應(yīng)的Map作業(yè),同時(shí),主控進(jìn)程還將分配若干個(gè)Reduce作業(yè)。
(3)被分配了Map作業(yè)的worker,開始讀取對應(yīng)分片的輸入數(shù)據(jù),Map作業(yè)數(shù)量由輸入文件的劃分決定,與split一一對應(yīng);Map作業(yè)從輸入數(shù)據(jù)中抽取出鍵值對,每一個(gè)鍵值對都作為參數(shù)傳遞給map函數(shù),map函數(shù)產(chǎn)生的中間鍵值對被緩存在內(nèi)存中。
(4)緩存的中間鍵值對會定期寫入本地磁盤,而且被分為R個(gè)區(qū),R的大小由用戶定義,將來每個(gè)區(qū)會對應(yīng)一個(gè)Reduce作業(yè);這些中間鍵值對的位置會通報(bào)給master,master負(fù)責(zé)將信息轉(zhuǎn)發(fā)給Reduce worker。
(5)主控節(jié)點(diǎn)通知分配了Reduce作業(yè)的worker它負(fù)責(zé)的分區(qū)在什么位置,當(dāng)Reduce worker把所有負(fù)責(zé)的中間鍵值對都讀過來后,先對它們進(jìn)行排序,使得相同鍵的鍵值對聚集在一起。因?yàn)椴煌逆I可能會映射到同一個(gè)分區(qū)也就是同一個(gè)Reduce作業(yè),所以排序是必須的。
(6)Reduce worker遍歷排序后的中間鍵值對,對于每個(gè)唯一的鍵,都將鍵與關(guān)聯(lián)的值傳遞給reduce函數(shù),reduce函數(shù)產(chǎn)生的輸出會添加到這個(gè)分區(qū)的輸出文件中。
(7)當(dāng)所有的Map和Reduce作業(yè)都完成了,master將會喚醒用戶程序,用戶程序?qū)apReduce平臺的調(diào)用由此返回。
MapReduce是一個(gè)簡便的編程模型,編程人員只需要實(shí)現(xiàn)其中的Map函數(shù)和Reduce函數(shù)即可。
2 框架描述
序列模式挖掘[4]是指找出所有滿足用戶指定的最小支持讀的序列,每個(gè)這樣的序列成為一個(gè)頻繁序列,或者一個(gè)序列模式。本文描述的算法基于序列模式挖掘,但是不考慮最小支持度,并且經(jīng)過一次循環(huán)即可挖掘出模式,所以不存在產(chǎn)生候選項(xiàng)集。
通常個(gè)性化推薦系統(tǒng)分為3個(gè)階段:數(shù)據(jù)預(yù)處理階段、模式發(fā)現(xiàn)階段和推薦階段。其中數(shù)據(jù)預(yù)處理階段和模式發(fā)現(xiàn)階段都是推薦系統(tǒng)定期執(zhí)行的(即離線部分),而推薦階段是實(shí)時(shí)的(即在線部分),因?yàn)橄到y(tǒng)需要通過用戶訪問的信息及時(shí)生成推薦信息。

在推薦階段,需要對用戶瀏覽過的頁面實(shí)時(shí)地進(jìn)行分析,并預(yù)測用戶要點(diǎn)擊的頁面,動態(tài)地為用戶推薦可能要瀏覽的頁面,因此在本階段引入活動窗口。如果根據(jù)用戶最新瀏覽的兩個(gè)網(wǎng)頁進(jìn)行推薦,則窗口大小為2。為便于理解,暫時(shí)討論活動窗口為3的情況。例如用戶u的活動窗口為〈A,B,C〉,假設(shè)用戶u下一個(gè)頁面點(diǎn)擊了頁面D,則活動窗口改為〈B,C,D〉,在此基礎(chǔ)上用戶u下一個(gè)頁面點(diǎn)擊了頁面D,則活動窗口改為〈B,D,C〉。如圖3所示。系統(tǒng)根據(jù)用戶的活動窗口,在已經(jīng)挖掘到的模式中進(jìn)行查詢,如果查詢到結(jié)果頁面,并且不止一個(gè)結(jié)果頁面,則可以根據(jù)模式比值進(jìn)行相應(yīng)處理,可以將比值最高的作為推薦頁面返回給用戶,也可以將比值排名前幾的作為推薦頁面返回給用戶。

3 MapReduce算法設(shè)計(jì)
在MapReduce算法設(shè)計(jì)[5]中,定義活動窗口的大小為2,并且默認(rèn)數(shù)據(jù)經(jīng)過預(yù)處理并保存在文本文件中,文本文件的一行為一個(gè)用戶的事務(wù),一個(gè)單詞表示為一個(gè)項(xiàng),項(xiàng)與項(xiàng)之間用空格隔開。
3.1 Map階段
Map階段輸入數(shù)據(jù)的鍵值對,Key為文本的行標(biāo),在本文中沒有實(shí)際意義,Value為文本中的一行數(shù)據(jù)。Map階段的偽代碼如下:
輸入:(key, value)
輸出:(word, one)
方法:map
{
line = value.toString();
pages = line.split(“ ”);
length = pages.length();
//通過三層循環(huán)發(fā)現(xiàn)模式
for(i=0; i<length-2; i++)
{
for(j=i+1; j<length-1; j++)
{
for(k=j+1; k<length; k++)
{
word=pages[i]+“ ”+pages[j];
one=pages[k];
//輸出結(jié)果
output.collect(word,one);
}
}
}
}
3.2 Reduce階段
在Reduce階段,Reduce工作節(jié)點(diǎn)從遠(yuǎn)程Map工作節(jié)點(diǎn)讀取中間結(jié)果。在此階段中,統(tǒng)計(jì)出模式出現(xiàn)的頻率,并得出與事務(wù)總數(shù)的比值,最后輸出結(jié)果鍵值對。
輸入:(word, values)
輸出:(word, sum)
方法:reduce
{
//通過循環(huán)發(fā)現(xiàn)模式出現(xiàn)的頻率
while(values.hasNext())
{
value=values.next().get();
result=resultMap.get(value);
if(null != result)
{
result += 1;
resultMap.put(value,result);
}
else
{
resultMap.put(value, 1);
}
}
itr=map.keySet().iterator();
//根據(jù)頻率得出與事務(wù)總數(shù)的比值
while(itr.hasNext())
{
key=itr.next();
ratio=map.get(key)/sumt;
resultBuffer.append(key+“:”+ratio);
}
//輸出結(jié)果
output.collect(word, resultBuffer);
}
本文提出了一種簡易的基于序列模式的推薦模型,并結(jié)合MapReduce,實(shí)現(xiàn)了在大數(shù)據(jù)條件下進(jìn)行模式挖掘的系統(tǒng),彌補(bǔ)了常見的個(gè)性化推薦系統(tǒng)缺少時(shí)序的缺點(diǎn),可以作為輔助的個(gè)性化推薦系統(tǒng)的應(yīng)用。但本文缺少實(shí)驗(yàn)數(shù)據(jù),沒有進(jìn)行實(shí)現(xiàn)分析,從而略顯遺憾。并且存在以下問題需要在以后的工作中繼續(xù)研究:
(1)個(gè)性化推薦的研究是基于用戶行為的研究,尤其是用戶Web瀏覽行為[6],用戶對不同類別的Web瀏覽習(xí)慣存在較大的差別。本文在用戶事務(wù)和活動窗口中均沒有考慮重復(fù)頁面的情況,并且活動窗口固定大小,因此在后續(xù)工作中應(yīng)加入特定條件下用戶行為的研究。
(2)在事務(wù)中的項(xiàng)較多的情況下,可以考慮對項(xiàng)進(jìn)行分類的策略,但是不同類別的項(xiàng)之間也可能存在關(guān)聯(lián),在活動窗口中也可引入類別的概念,可以考慮同類別項(xiàng)之間的前后順序,而不像本文只單純地考慮瀏覽頁面的順序,這也將在后續(xù)工作中進(jìn)行研究。
參考文獻(xiàn)
[1] SARWAR B,KARYPIS G,KONSTAN J,et al.Item-based collaborative filtering recommendation algorithms[C].In Proceedings of the Tenth International. World Wide Web Conference on World Wide Web,2001.
[2] GHEMAWAT S,GOBIOFF H,LEUNG S-T.The Google file system[C].Procedings of 19th ACM Symposium on Operating System Principles,2003:29-43.
[3] DEAN J,GHEMAWAT S.MapReduce: simplified data processing on large clusters[J].Communications of the ADM 50th Anniversary lssue:1958-2008,2008,51(1):107-113.
[4] AGRAWAL R,SRIKANT R.Mining sequential patterns[C]. In Proc. of the Intl.conf.on Data Engineering,1995:3-15.
[5] WHITE T.Hadoop:the definitive guide[M].Yahoo Press,2010.
[6] MOBASHER B,DAI H,LUO T,et al.Effective personalization based on association rule discovery from web usage data[C].Proceedings of the 3rd International Workshop on Web Information and Data Management,2001:9-15.