
文獻標識碼: B
文章編號: 0258-7998(2014)07-0006-03
隨著信息技術(shù)的發(fā)展,對頻譜的需求日益增強,信號工作頻段越來越高,單個信道占用的頻譜帶寬也越來越寬[1]。在實際生活中,越來越多的通信系統(tǒng)工作在很寬的頻帶,如LTE的頻譜帶寬已經(jīng)達到20 MHz。若要監(jiān)測這一類頻譜,由帶通采樣定理可知[2],對數(shù)據(jù)采樣率有更高的要求,相應(yīng)地對數(shù)字信號處理器件處理能力的要求也更高。但僅僅提升數(shù)字信號處理器件的處理能力,而相應(yīng)數(shù)據(jù)傳輸接口傳輸緩慢,也無法實時完成頻譜監(jiān)測任務(wù)。因此,各類數(shù)字處理器件之間數(shù)據(jù)接口的傳輸速率成為了解決這類問題的核心所在。
為實現(xiàn)更好、更快、更寬的頻譜監(jiān)測,采用TI公司的OMAP-L138雙核處理器,利用其EMAC模塊、uPP接口,結(jié)合ARM與DSP之間的雙FIFO緩存結(jié)構(gòu),實現(xiàn)了一種高速處理器件之間高速數(shù)據(jù)傳輸接口的設(shè)計。該設(shè)計具有良好的可行性及擴展性,可以很方便地應(yīng)用到其他對數(shù)據(jù)傳輸有較高要求的應(yīng)用中。
1 設(shè)計方案
本文提出的高速傳輸接口設(shè)計以O(shè)MAP-L138雙核處理器為核心,配合高速以太網(wǎng)PHY芯片DP83640和FPGA(現(xiàn)場可編程門陣列),組成了一個高速數(shù)字信號傳輸系統(tǒng),系統(tǒng)結(jié)構(gòu)如圖1所示。射頻信號通過射頻前端變頻到75 MHz中頻,通過ADC以60 MS/s的采樣率采樣后送入FPGA,在FPGA中進行相關(guān)處理后通過uPP接口將數(shù)字化信息傳至DSP。在DSP中進行相關(guān)的頻譜參數(shù)處理后,利用共享內(nèi)存的方式交由ARM回傳數(shù)據(jù)到遠端觀測、記錄,實現(xiàn)了無線電磁信號到網(wǎng)絡(luò)頻譜信息的高速傳輸。本設(shè)計提高了數(shù)字頻譜監(jiān)測中數(shù)據(jù)傳輸?shù)耐掏履芰Γ瑢崟r性更強,更易擴展。

本設(shè)計中以TI公司的OMAP-L138為核心,其集成了ARM926EJ-STM精簡指令集處理器和C674x定點/浮點超長指令字(VLIW)數(shù)字信號處理器,其時鐘頻率最高可達300 MHz,提供了較強的控制能力與數(shù)據(jù)處理能力。外設(shè)中包括一個具有管理數(shù)據(jù)輸入/輸出(MDIO)模塊的10/100 Mb/s以太網(wǎng)模塊(EMAC)、通用并行接口uPP(Universal Parallel Port)等[3-4],這些強大的外設(shè)保證了高速傳輸系統(tǒng)的可實現(xiàn)性。
1.1 DSP與FPGA高速通信接口設(shè)計
從圖1可知,F(xiàn)PGA完成信號的高速采集并進行預(yù)處理之后,需要將數(shù)據(jù)交由DSP來進行相應(yīng)的信號處理。在DSP與FPGA的傳輸上采用了OMAP-L138提供的uPP接口。uPP為高速并行接口,可以利用其自身的DMA完成數(shù)據(jù)傳輸,而不占用處理器運行時間。在OMAP處理器中包含兩個通道的uPP[3],每個通道可以設(shè)置成8 bit或16 bit傳輸,通過使用START、ENABLE和WAIT接口控制。uPP引腳功能說明如表1所示。

uPP包含內(nèi)部DMA控制器以實現(xiàn)最大的吞吐率和最小化CPU占用。此外uPP外設(shè)支持數(shù)據(jù)的交織模式,使用這種模式,所有DMA資源可以服務(wù)一個單獨的I/O。uPP最大工作頻率可以達到75 MHz,若以16 bit傳輸,可以達到1 200 Mb/s的傳輸速率,兩個通道并行傳輸則能夠達到最大2 400 Mb/s的傳輸速率,這個數(shù)據(jù)傳輸速率對于大多數(shù)的應(yīng)用都已足夠。而在參考文獻[5]中提到的基于McBSP的傳輸方式能夠達到的最大數(shù)據(jù)速率只有40 Mb/s,可見uPP的使用大大提升了DSP與FPGA的接口速率。uPP與FPGA通信的時序如圖2所示。

在開始傳輸時,F(xiàn)PGA端只需要拉高使能信號并提供一個START信號,DSP收到信號之后便能夠啟用uPP自帶的DMA開始進行數(shù)據(jù)傳輸,其傳輸快捷,實現(xiàn)方便,利于擴展到其他類似數(shù)據(jù)傳輸任務(wù)中。
1.2 ARM與DSP雙核通信接口設(shè)計
DSP接收到FPGA回傳的預(yù)處理數(shù)據(jù)并完成相關(guān)處理之后便需要將數(shù)據(jù)信息回傳到客戶端進行相應(yīng)的觀察、記錄。在本設(shè)計中,為了充分發(fā)揮雙核的性能,完成數(shù)據(jù)的高速傳輸,提出了一種雙FIFO共享內(nèi)存的結(jié)構(gòu)實現(xiàn)ARM與DSP之間的高效通信。
在參考文獻[6]中,介紹了OMAP3530上ARM與DSP聯(lián)合調(diào)試的方法。在本文中,基于此方法,將ARM與DSP之間的通信進行了適當?shù)膬?yōu)化。ARM與DSP的通信采用DSP/BIOS Link(簡稱為DSPLink)完成。DSP Link是雙核處理器內(nèi)部GPP與DSP兩側(cè)通信的基礎(chǔ)軟件。它提供了一個通用的API,這個API可以從應(yīng)用層上實現(xiàn)物理層GPP與DSP交互,避免了客戶重新開發(fā),可以快速實現(xiàn)GPP與DSP的交互功能[4,7]。
DSPLink軟件架構(gòu)如圖3所示[7]。在GPP端,OS適應(yīng)層將DSP/BIOS Link組件需要的操作系統(tǒng)服務(wù)封裝。這個組件提供一些通用的API而非直接系統(tǒng)調(diào)用,使得DSP/BIOS Link可以很方便地在不同操作系統(tǒng)上移植。DSP端運行DSP/BIOS實時操作系統(tǒng)[8],GPP端與DSP端通過兩端的Link Driver模塊完成通信。Link Driver模塊封裝一些GPP與DSP之間底層的控制操作,同時負責控制DSP端的執(zhí)行以及數(shù)據(jù)傳輸。

DSPLink通過在ARM和DSP兩端觸發(fā)硬件中斷的方式來實現(xiàn)雙核之間的通信,實際上并不能夠達到高速的數(shù)據(jù)傳輸。但在本設(shè)計中,采用雙FIFO共享內(nèi)存的方式可有效解決這一問題。
在實際傳輸中,數(shù)據(jù)并不需要直接從DSP搬移到ARM,這種搬移必定會占用較多的時間,效率低下。本設(shè)計中通過對輸入數(shù)據(jù)在兩塊FIFO間進行乒乓緩存的方式完成。當一塊FIFO存滿時,只需要利用DSPLink將該FIFO在共享內(nèi)存中的地址以及數(shù)據(jù)大小傳遞給ARM,ARM直接從共享內(nèi)存中取出使用,這樣可以大大提高雙核之間數(shù)據(jù)傳遞的效率。該共享內(nèi)存結(jié)構(gòu)如圖4所示。

然而,在這個過程中存在一個問題,由于ARM運行Linux系統(tǒng),進程運行時使用的是虛擬地址,所分配的一串內(nèi)存在DSP端可能并不是一片連續(xù)的物理內(nèi)存,這就為共享內(nèi)存的實現(xiàn)帶來了較大的麻煩。為了解決這個問題,采用了TI公司提供的連續(xù)內(nèi)存管理CMEM(Contiguous Memory Manage)函數(shù)庫。CMEM是一個API函數(shù)庫,用于管理一塊或多塊連續(xù)物理內(nèi)存。CMEM同時提供了地址轉(zhuǎn)換服務(wù)和用戶模式的緩存管理API,用于管理一個或多個連續(xù)的物理內(nèi)存并提供地址轉(zhuǎn)換功能,物理連續(xù)地址內(nèi)存用于主處理器與DSP的數(shù)據(jù)緩存共享。
通過CMEM可以有效地解決DSPLink不能分配大片連續(xù)內(nèi)存的問題。CMEM提供了ARM核Linux程序和DSP程序的直接數(shù)據(jù)緩存共享,此外還可以提供ARM核Linux中不通過MMU存取內(nèi)存調(diào)用硬件加速器的方法。
利用CMEM基于POOL的配置,能夠避免內(nèi)存碎片,且能夠保證即便系統(tǒng)已經(jīng)運行了很長一段時間,也可以分配到很大一塊連續(xù)物理內(nèi)存塊[4]。
至此,ARM端只需要通過網(wǎng)絡(luò)便可以將監(jiān)測到的信息回傳到PC客戶端,完成監(jiān)測任務(wù)。
1.3 網(wǎng)絡(luò)接口設(shè)計
ARM通過網(wǎng)絡(luò)接口與PC相連,通過網(wǎng)絡(luò)來完成與用戶的數(shù)據(jù)交互。網(wǎng)絡(luò)結(jié)構(gòu)的標準模型是OSI模型,該參考模型從上到下分為7層,分別為:應(yīng)用層、表示層、會話層、傳輸層、數(shù)據(jù)鏈路層及物理層。在實際應(yīng)用中,通常使用TCP/IP網(wǎng)絡(luò)模型,該模型從上到下分為4個層次:應(yīng)用層、傳輸層、網(wǎng)絡(luò)層和網(wǎng)絡(luò)接口層(即物理層)[8]。其中應(yīng)用層、傳輸層、網(wǎng)絡(luò)層均在移植Linux系統(tǒng)時集成,本文不做重點討論。物理層對應(yīng)OSI模型中的數(shù)據(jù)鏈路層和物理層。數(shù)據(jù)鏈路層包括LLC(Logic Link Control)和MAC(媒體訪問控制器)子層,LLC負責與上層(網(wǎng)絡(luò)層)通信,MAC負責對物理層的控制。本系統(tǒng)中數(shù)據(jù)鏈路層使用OMAP-L138內(nèi)部集成的EMAC模塊實現(xiàn),而物理層使用NS公司的PHY芯片DP83640實現(xiàn)。
DP83640是一款具有IEEE 1588功能的Ethernet PHY芯片。可以在100 Mb/s的高傳輸速率下,通過以太網(wǎng)連接的IEEE 1588精密時間協(xié)議(PTP)實現(xiàn)系統(tǒng)之間的精確同步。
DP83640通過OMAP-L138提供的標準媒體獨立接口MII(Media Independent Interface)與其連接,其硬件連接圖如圖5所示。
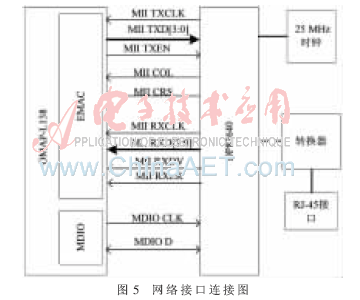
MII接口以4 bit的方式雙向傳輸,時鐘為25 MHz,工作速率可以達到100 Mb/s。MDIO為MII的管理接口,用來傳送MAC層的控制信息和物理層的狀態(tài)信息。MDIO具有兩根信號線,一個時鐘信號,一個數(shù)據(jù)信號。利用MII接口可以確保在不對MAC硬件重新設(shè)計或替換的情況下,任何類型的PHY設(shè)備都可以正常工作。
2 接口測試
2.1 ARM與DSP數(shù)據(jù)傳輸測試
測試ARM與DSP之間的通信時,通過DSP往ARM端傳遞消息。測試中,共發(fā)送1 000條消息,測試結(jié)果如圖6所示。

從圖6中可以看出,傳遞1 000條消息總共耗時359 704 μs,即ARM與DSP之間傳遞一條消息大約耗時359 μs,利用文中提到的共享內(nèi)存的方式,便可以在359 μs內(nèi)完成一次大量數(shù)據(jù)的傳輸,傳輸性能得到了大大的提高。在本應(yīng)用中,所選用的共享內(nèi)存FIFO大小僅為8 KB,但此時等效的傳輸速率已經(jīng)達到178.4 Mb/s。
在實際應(yīng)用中,可以根據(jù)需求來設(shè)定FIFO大小,從而可以改變ARM與DSP之間的等效傳輸速率。
2.2 網(wǎng)絡(luò)傳輸速率測試
測試方法:
(1)接收機作為客戶端,接收PC數(shù)據(jù);
(2)接收機作為服務(wù)器,往PC寫數(shù)據(jù)。
測試工具選用Linux平臺上的開放網(wǎng)絡(luò)測試工具bwm-ng,能夠準確地測試網(wǎng)絡(luò)通信速率[9]。
2.2.1 PC往接收機傳送數(shù)據(jù)速率測試
此種情況下PC作為服務(wù)器往接收機發(fā)送數(shù)據(jù),測試得到的通信速率可以達到61 Mb/s左右,最快可以達到64 Mb/s,這個速率能夠滿足大多數(shù)的應(yīng)用。
2.2.2 接收機往PC回傳數(shù)據(jù)速率測試
在這種情況下,接收機作為服務(wù)器往PC客戶端傳輸數(shù)據(jù)。PC端觀測到的接收速率在14.5 Mb/s左右,對于回傳頻譜監(jiān)測后的數(shù)據(jù)已經(jīng)足夠。
對比以上測試結(jié)果,在這兩種情況下,獲得的結(jié)果存在一定的差異,主要原因為當接收機作為服務(wù)器往外發(fā)送數(shù)據(jù)時,由于其時鐘頻率僅有300 MHz,而使用的PC主頻接近2.4 GHz,所以發(fā)送速率較PC慢。但從兩者可以看出,本設(shè)計中的網(wǎng)絡(luò)接口部分可以達到上行14.5 Mb/s、下行64 Mb/s的傳輸速率,已滿足大多數(shù)的網(wǎng)絡(luò)傳輸應(yīng)用需求。
本文采用OMAP-L138雙核處理器,結(jié)合FPGA實現(xiàn)了數(shù)字頻譜監(jiān)測接收機中的高速傳輸接口。利用uPP接口,DSP與FPGA之間最大通信速率可以達到2 400 Mb/s,能很好地滿足頻譜監(jiān)測任務(wù)的需求。雙核間采用共享內(nèi)存的方式,有效地解決了雙核系統(tǒng)間的高速傳輸問題,此設(shè)計可以很方便地擴展到其他應(yīng)用中。
參考文獻
[1] 費連.無線電監(jiān)測系統(tǒng)的革新——網(wǎng)絡(luò)化小型頻譜監(jiān)測系統(tǒng)的概念及主要技術(shù)要求[J].電子測量與儀器學(xué)報,2009(S1):180-184.
[2] 陳祝明.軟件無線電技術(shù)基礎(chǔ)[M].北京:高等教育出版社,2007.
[3] Texas Instrument Inc..OMAP-L138 technical reference manual[Z].2009.
[4] DSP+ARM雙核處理器OMAPL138開發(fā)入門[M].北京:清華大學(xué)出版社,2013.
[5] 徐萍,左洪成,徐婷.基于雙FIFO乒乓緩存的多速率匹配McBSP接口設(shè)計[J].電子質(zhì)量,2011(9):29-31.
[6] 林上升,韓潤萍.基于OMAP3530硬件平臺的ARM和DSP協(xié)同開發(fā)方法[J].電子技術(shù)應(yīng)用,2013,39(2):6-8.
[7] Texas Instrument Inc.DSP/BIOS LINK user guide[Z].2010.
[8] 邴哲松.ARM Linux嵌入式網(wǎng)絡(luò)控制系統(tǒng)[M].北京:北京航空航天出版社,2012.
[9] Volker Gropp.Bandwidth monitor NG[EB/OL](2007)[2014-03-31].http://www.gropp.org.