
文獻標識碼:A
文章編號: 0258-7998(2014)07-0116-03
對業(yè)務系統(tǒng)連續(xù)性要求較高的企業(yè)或機構(gòu),,其數(shù)據(jù)安全極為重要[1],。傳統(tǒng)的RAID、遠程鏡像,、周期性備份和快照等技術(shù)都會引起數(shù)據(jù)丟失的問題[2-4],。因此對數(shù)據(jù)可靠性和安全級別要求較高的業(yè)務部門急需存儲系統(tǒng)能提供連續(xù)數(shù)據(jù)保護(CDP)功能[5]。
國內(nèi)外在CDP系統(tǒng)研究方面已經(jīng)開展了大量研究[6],。但這些工作主要集中在存儲架構(gòu)設計,、存儲空間優(yōu)化和一致點恢復等方面,對快速恢復研究不多,。針對海量的塊級變化數(shù)據(jù),,設計高效快速的索引方法是個研究難點。本文主要針對卷級系統(tǒng)歷史數(shù)據(jù)索引和查詢的優(yōu)化,,提出一種面向連續(xù)數(shù)據(jù)的分時分段的層次式快速索引方法HSTIM(Hierarchical Spatial-Temporal Indexing Method),。
1 HSTIM設計
在磁盤邏輯卷層次,數(shù)據(jù)由連續(xù)的數(shù)據(jù)塊組成,。每個數(shù)據(jù)塊有固定的大小,,并通過邏輯塊地址LBA來標識。連續(xù)數(shù)據(jù)保護實現(xiàn)的關鍵技術(shù)是對數(shù)據(jù)變化的記錄和保存,,以便實現(xiàn)任意時間點的快速恢復,。CDP一般有3種實現(xiàn)方式:基準參考數(shù)據(jù)模式、復制參考數(shù)據(jù)模式和合成參考數(shù)據(jù)模式[7-8],。其中,,合成參考數(shù)據(jù)模式是前兩種模式性能的折衷,較好地實現(xiàn)了前兩種模式的妥協(xié),,因此可以得到較好的資源占用和恢復時間效果,,但需要復雜的軟件管理和數(shù)據(jù)處理功能,實現(xiàn)比較復雜,。
1.1 分時分段索引數(shù)據(jù)組織
HSTIM中索引數(shù)據(jù)按分時和分段策略組織,,數(shù)據(jù)組織如圖1所示,。圖1例中在t3~t4時間段內(nèi)共產(chǎn)生N+1個索引文件(元數(shù)據(jù)單獨索引)。段區(qū)間的長度采用不等成劃分方法,,長度按磁盤寫IO密度來確定,。索引文件記錄了Rt(a) ,即t時刻邏輯地址為a的增量數(shù)據(jù)在增量存儲空間的位置,。為加速索引的讀取速度,,可采用多個物理硬盤存放索引文件。

1.2 索引快照
索引快照提取了一個時間段的索引階段結(jié)果,。在圖2的例子中,,t1和t2兩個時刻插入了索引快照。所有索引快照結(jié)果存放至一個獨立的索引文件,,如圖2的右側(cè)的索引快照獨立索引文件,。快照獨立索引文件采用OVBT索引方式,。如果用戶需要查詢圖1中t時刻的索引結(jié)果,,則可通過先查詢索引快照獲得t1和t2時刻的索引,然后查詢t2~t時刻的索引,,最后將索引結(jié)果進行合并即可,。HSTIM通過索引快照避免了索引數(shù)據(jù)的全查詢,加快了特定時刻索引的快速查詢,,尤其適用于歷史數(shù)據(jù)保護時間窗口較長的應用場景,。由于索引快照文件較小,在實現(xiàn)上沒有采用分段策略,,即將LBA地址從0~MAX索引快照存放至一個索引文件中,。

1.3 增量式快速查找
HSTIM通過改進OVBT索引節(jié)點結(jié)構(gòu)實現(xiàn)了增量查找支持。原先的OVBT內(nèi)部節(jié)點包括了引用數(shù)目和分裂值列表,。HSTIM中的內(nèi)部節(jié)點通過新增時間戳列表實現(xiàn)了增量查找,。HSTIM和OVBT的內(nèi)部結(jié)構(gòu)比較如圖3所示。

卷級CDP一次IO更新產(chǎn)生一條索引記錄項,,索引記錄項可用{LBA,timestamp,R}表示,,其中LBA表示IO的LBA地址,timestamp表示時間戳,,R代表數(shù)據(jù)在存儲池中的位置,。OVBT索引需要對每一個索引項進行記錄,針對每一個IO的時間戳生成一個獨立的B+樹索引,。OVBT有兩種類型的節(jié)點:葉子節(jié)點和非葉子節(jié)點,。兩種節(jié)點由通用的索引項{ref, entries}組成,其中ref表示節(jié)點被引用的次數(shù),,entries 由{entry, entry,…, entry}列表組成,。每個entry由{key, timestamp, info}3個元素構(gòu)成,。對葉子節(jié)點,key表示IO的LBA地址,,timestamp表示時間戳,,info表示數(shù)據(jù)在存儲池中的位置,即索引記錄項中的R,。對非葉子節(jié)點,,key代表B+的分裂鍵值,timestamp代表所指向下一層節(jié)點的插入時間,,info是指向下一層節(jié)點的指針,。
為記錄每一更新IO產(chǎn)生的B+樹的根節(jié)點,OVBT維護一張根節(jié)點記錄表(root table),。根節(jié)點記錄表由{root, root,…, root}列表組成,,每個root項由{timestamp, ptr}組成,其中timestamp代表獨立B+樹的產(chǎn)生時間,,ptr指向B+樹的根節(jié)點,。
2 性能評測
2.1 測試方法和實驗平臺
通過對實際應用中的IO trace文件進行回放的方式對HSTIM性能進行了評測,。測試選擇的IO trace是Msr-cambridge Trace,。該Trace文件采集了企業(yè)數(shù)據(jù)中心13臺服務器上共36個磁盤卷連續(xù)14天的塊級數(shù)據(jù)。實驗選取文件集合中數(shù)據(jù)量最大的文件CAMRESISAA02_ lvm1.csv(以下簡稱AA02_Trace)作為樣本,。所有的IO請求塊都按最小磁盤扇區(qū)大小(512 B)進行了等長切割和對齊存儲,。實驗平臺主要硬件包括Pentium(R) Dual-core E5200 2.50 GHz處理器、4 GB DDR2內(nèi)存和500 GB Seagate ST3500620A硬盤, 操作系統(tǒng)是Windows 7,。
2.2 HSTIM與B+-tree和OVBT性能綜合比較
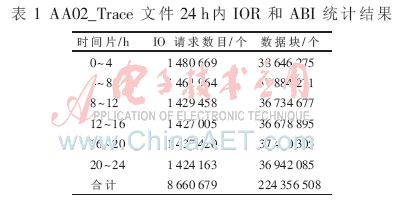
實驗對AA02_Trace文件進行了24 h的數(shù)據(jù)回放,,經(jīng)統(tǒng)計在24 h內(nèi),系統(tǒng)共產(chǎn)生8 660 679個IOR (寫IO請求),。如果對每個IOR按512 B等長切割,則共產(chǎn)生224 356 508個對齊的塊級IO(Aligned Block IO,以下簡稱ABI),,表1給出了AA02_Trace文件24 h內(nèi)的寫IO統(tǒng)計結(jié)果。為描述方便,,本實驗中對HSTIM采用了等長分時,時長分別為0.5 h和2 h,分別稱HSTIM-0.5和HSTIM-2,。實驗從索引文件大小、插入性能和查詢性能三方面對HSTIM,、B+-tree和OVBT進行了綜合比較,,給出了周期為2 h的性能統(tǒng)計結(jié)果。
(1)查詢性能比較
表2給出了OVBT與B+-tree的查詢性能比較,。實驗表明,,B+-tree的查詢速度在RPO小于5 h可以接受,基本在1 min內(nèi)得出查詢結(jié)果,。但在RPO大于5 h的情況下,查詢性能急劇下降,在RPO=6 h查詢時間為838 s,,RPO=12 h查詢時間長達2.27 h,。對OVBT而言,由于每一個時間點索引數(shù)據(jù)由一顆獨立B+樹組成,,查詢時間相對穩(wěn)定,。RPO小于12 h內(nèi)任意點查詢時間小于44 s。本實驗同時說明,傳統(tǒng)的分別對LBA和Timestamp建立B+-tree的索引方式不適合大數(shù)量的任意點恢復索引的需要,。
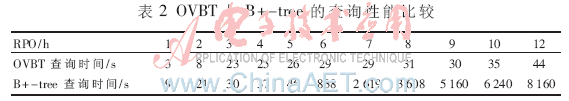
HSTIM由于采用分時策略并將分時索引快照獨立組織,,因此查詢時間包括索引快照查詢時間和時間段內(nèi)索引查詢時間。圖4給出了HSTIM-2,、HSTIM-0.5和OVBT的查詢性能比較,。實驗結(jié)果表明,HSTIM在查詢性能上較OVBT有較大提高,。在RPO=24 h,,HSTIM-0.5的查詢時間僅為OVBT的11.6%。HSTIM-0.5與HSTIM-2相比,,由于分時頻率高,,因此查詢索引快照時間略長于HSTIM-2,但時段內(nèi)的索引查詢速度明顯少于HSTIM-2,。但從整體上看,,HSTIM-0.5和HSTIM-2的查詢速度并無大的差別。
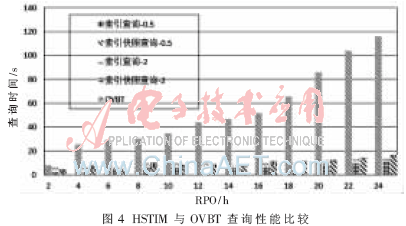
(2)索引空間消耗比較
圖5給出了OVBT與B+-tree索引空間比較結(jié)果,。測試表明,,OVBT索引存儲空間平均是B+-tree的5.2~5.5倍。由于OVBT內(nèi)部有大量重復數(shù)據(jù),,采用壓縮工具對索引文件進行壓縮,,壓縮后的OVBT索引文件大小平均僅為原索引文件的3%。但壓縮帶來的問題是,,恢復時需要引入額外的解壓縮時間開銷,。為減少存儲空間,在實際應用中可以將離當前時間點較遠的索引文件壓縮存儲,。
本文針對卷級CDP任意點恢復提供了一種快速的索引方法-HSTIM,,并對該方法的性能進行了評估。實驗結(jié)果表明,,在一定的備份窗口內(nèi),,HSTIM能為卷級CDP任意點的恢復提供快速索引支持。高效的索引可快速定位到變化數(shù)據(jù)在增量空間中的存放位置,,解決恢復中數(shù)據(jù)“在哪里”的問題,。
參考文獻
[1] 梁知音,段鐳,,韋韜,,等. 云存儲安全技術(shù)綜述[J].電子技術(shù)應用, 2013,39(4):130-132.
[2] SMITH D M. The cost of lost data[J]. Journal of Contemporary Business Practice, 2003,6(3):113-119.
[3] PATTERSON D, BROWN A, BROADWELL P, et al. Recovery oriented computing(ROC): motivation, definition, techniques, and case studies[R]. Computer Science Technical Report UCB/CSD-0201175, San Francisco: U.C. Berkeley, 2002:997-1013.
[4] SANKARAN A, GUINN K, NGUYEN D. Volume shadow copy service[J]. Power, 2004,14(2):2272-2284.
[5] SNIA. Continuous data protection-solving the problem of Recovery[EB/OL].(2008-08-08)[2014-02-22].http://www.snia.org/forums/dmf/knowledge/white_papers_and_reports/CDP_Solving_recovery_20080808.pdf.
[6] SNIA.DMF-Getting_started_with_ILM-20050415[EB/OL].(2005-04-15)[2014-02-22].http://www.snia.org/forums/dmf/programs/ilmi/DMF-Getting_started_with_ILM-20050415.pdf.
[7] PIERNAS J, CORTES T,CARC′IA J, DualFS: a new journaling file system without meta-data duplication[C]. In Proceedings of the 16th International Conference on Supercomputing. New York: ACM press, 2002:146-159.
[8] KAVALANEKAR S, WORTHINGTON B, ZHANG Q, et al.Characterization of storage workload traces from production Windows servers[C]. In IEEE International Symposium on Workload Characterization, IEEE press, 2008:671-686.