
網(wǎng)絡(luò)處理器芯片主要用于構(gòu)建網(wǎng)絡(luò)通信基礎(chǔ)設(shè)施平臺,對于位于網(wǎng)絡(luò)通信終端節(jié)點(diǎn)的用戶來說,通常是透明而不可見的。因此,與通用CPU以及嵌入式CPU等大眾電子消費(fèi)密切相關(guān)的通用處理器芯片相比,網(wǎng)絡(luò)處理器(Network Processor)芯片一直以來很少能夠獲得廣泛的關(guān)注。
實(shí)際上,網(wǎng)絡(luò)處理器廣 泛應(yīng)用于包括路由器、交換機(jī)等各類網(wǎng)絡(luò)核心設(shè)備中,它特定應(yīng)用于網(wǎng)絡(luò)通信領(lǐng)域的各種任務(wù),例如報(bào)文處理、協(xié)議分析、路由查找、防火墻以及QoS等。網(wǎng)絡(luò)處 理器芯片對于網(wǎng)絡(luò)通信基礎(chǔ)設(shè)施的重要性,阿爾卡特朗訊公司的 Basil Alwan有一句話形容得很貼切,“網(wǎng)絡(luò)處理器是網(wǎng)絡(luò)設(shè)備最根本的基因,它定義了路由器平臺的能力、可擴(kuò)展性以及面向未來演化的可能性[1]”。
國內(nèi)外研制情況
經(jīng)過多年的發(fā)展,網(wǎng)絡(luò)處理器正逐漸替代網(wǎng)絡(luò)通信設(shè)備中固定功能的ASIC芯片,已成為構(gòu)建網(wǎng)絡(luò)通信系統(tǒng)的戰(zhàn)略性核心器件。商用網(wǎng)絡(luò)處理器市場在不斷增長,而市場上網(wǎng)絡(luò)處理器芯片產(chǎn)品則基本上來自國外廠商。
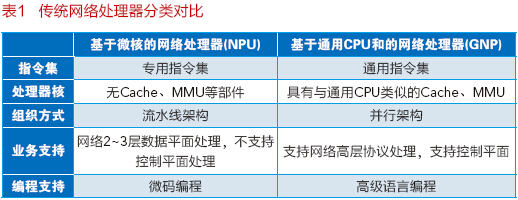
傳統(tǒng)網(wǎng)絡(luò)處理器按核心處理單元的不同可以分為兩類,即基于微核的網(wǎng)絡(luò)處理器(NPU)以及基于通用CPU核的網(wǎng)絡(luò)處理器(GNP),主要區(qū)別如表1所示。
目前,典型商用網(wǎng)絡(luò)處理器芯片包括阿爾卡特朗訊的FP系列[1]、Marvell 公司的Xelerated系列[2]、EZchip的NP系列[3]等。上述網(wǎng)絡(luò)處理器通常采用多核多線程、超流水等高級體系結(jié)構(gòu),利用功能部件定制優(yōu)化、深亞微米集成電路設(shè)計(jì)等技術(shù)提高報(bào)文處理性能,其中多款網(wǎng)絡(luò)處理器可以達(dá)到400Gbps報(bào)文處理要求。
阿爾卡特朗訊公司的FP3網(wǎng)絡(luò)處理器集成共288個(gè)RISC Core,主頻可達(dá)1GHz,其中每32個(gè)Core為一個(gè)Cluster,共9個(gè)Cluster。它采用多Pipeline處理模型,F(xiàn)P3的報(bào)文轉(zhuǎn)發(fā)處 理能力高達(dá)400Gbps。與FP3類似,Marvell公司的HX4100網(wǎng)絡(luò)處理器(原Xelerated公司)也采用類似的多Pipeline處理 模型,通過集成數(shù)百個(gè)支持VLIW指令集的PISC(Packet Instruction set computer)專用處理器核,也可實(shí)現(xiàn)400Gbps線速報(bào)文處理。值得一提的是,HX4100流水線間得PISC采用同步數(shù)據(jù)流體系結(jié)構(gòu),從而避免 了控制流模型中的指令相關(guān)性對性能的影響,可確保系統(tǒng)獲得確定性的處理性能。EZchip的NP-5采用Functional Pipeline處理模型,處理流程映射到4級面向任務(wù)優(yōu)化的處理引擎,采用專用指令集,基于功能編程語言(FPL)開發(fā),分組處理能力達(dá)到 240Gbps。上述芯片產(chǎn)品都屬于基于微核的網(wǎng)絡(luò)處理器,大多采用流水線方式組織,以提供極高的報(bào)文轉(zhuǎn)發(fā)處理性能,在芯片功耗方面具有優(yōu)勢,主要缺點(diǎn)是 通常僅支持微碼編程,軟件開發(fā)復(fù)雜困難。
Broadcom公司的XLP II 900網(wǎng)絡(luò)處理器[4]集成了多達(dá)80個(gè)通用CPU核(nxCPUs),具有三級 Cache存儲子系統(tǒng)和4個(gè)DDR3內(nèi)存控制器,采用并行處理架構(gòu),可提供160Gbps報(bào)文轉(zhuǎn)發(fā)處理性能。通過集成安全加速引擎,其可支持高性能的加 密、認(rèn)證以及深度報(bào)文檢測等功能。Cavium公司的OCTEON III網(wǎng)絡(luò)處理器[5]也采用并行架構(gòu),通過集成48個(gè)64位 MIPSCPU核和大量的加速引擎,可提供100Gbps報(bào)文轉(zhuǎn)發(fā)處理能力,并支持廣泛的網(wǎng)絡(luò)業(yè)務(wù)處理硬件加速。上述芯片產(chǎn)品都屬于基于通用CPU核的網(wǎng) 絡(luò)處理器(GNP),面向支持多樣化網(wǎng)絡(luò)高層協(xié)議和業(yè)務(wù)處理設(shè)計(jì),具有較強(qiáng)的可編程性,通常可以支持C/C++高級語言編程,并運(yùn)行通用Linux操作系 統(tǒng),從而為開發(fā)人員帶來便捷。然而,集成度與功耗問題嚴(yán)重制約了GNP的性能提升。
從國內(nèi)來看,華為、中興等網(wǎng)絡(luò)設(shè)備廠商以及國防科大等科研院所早已基于國外成熟網(wǎng)絡(luò)處理器芯片設(shè)計(jì)了多款高性能路由器產(chǎn)品,并已經(jīng)在國內(nèi)外市場 上得到廣泛應(yīng)用。國防科大、西安電子科大以及清華大學(xué)等單位在國內(nèi)也較早開展了網(wǎng)絡(luò)處理器研制,取得了一定進(jìn)展和技術(shù)積累,但與國外仍有一定差距,目前還 沒有成熟的國產(chǎn)商用網(wǎng)絡(luò)處理器芯片產(chǎn)品。
隨著國家戰(zhàn)略層面對網(wǎng)絡(luò)通信基礎(chǔ)設(shè)施安全及自主創(chuàng)新能力的重視,作為構(gòu)建網(wǎng)絡(luò)通信設(shè)備的核心器件,網(wǎng)絡(luò)處理器芯片的國產(chǎn)化將是一種必然。為了選擇一條切實(shí)可行的網(wǎng)絡(luò)處理器研制的技術(shù)途徑,必須充分把握網(wǎng)絡(luò)處理器研制所面臨的挑戰(zhàn)和技術(shù)發(fā)展趨勢。
研制挑戰(zhàn)與技術(shù)趨勢
與通用CPU不同,網(wǎng)絡(luò)處理器芯片研制一方面涉及網(wǎng)絡(luò)通信、微電子、操作系統(tǒng)以及處理器體系結(jié)構(gòu)等多個(gè)領(lǐng)域的技術(shù),設(shè)計(jì)難度大;另一方面其處理性能必須能夠匹配飛速增長的網(wǎng)絡(luò)接口帶寬需求,硬性要求高。因此,網(wǎng)絡(luò)處理器芯片復(fù)雜度高、實(shí)現(xiàn)困難,其研制周期長,投入資金高昂,研發(fā)難度非常大,這也是國產(chǎn)商用高性能網(wǎng)絡(luò)處理器遲遲未取得突破的重要原因。以思科公司為例,其SPP網(wǎng)絡(luò)處理器于1999年開始設(shè)計(jì),2003年才在cisco的第一臺集群路由器CRS-1中使用;而其在2008年設(shè)計(jì)完成的QFP網(wǎng)絡(luò)處理器前后共花費(fèi)1億美金才研制成功,商用高性能網(wǎng)絡(luò)處理器的研制難度可見一斑。
從技術(shù)發(fā)展趨勢看,隨著軟件定義網(wǎng)絡(luò)(Software Defined Network,SDN)、網(wǎng)絡(luò)功能虛擬化(Network Function Virtualization)等技術(shù)的出現(xiàn)和發(fā)展,對網(wǎng)絡(luò)通信設(shè)備的可編程性提出更高要求。不斷演化的網(wǎng)絡(luò)通信業(yè)務(wù)和協(xié)議也要求構(gòu)建網(wǎng)絡(luò)通信設(shè)備的核心 器件必須能夠易于編程開發(fā),以期加快系統(tǒng)研制進(jìn)度、降低開發(fā)成本并實(shí)現(xiàn)投資保護(hù)。基于通用CPU核的網(wǎng)絡(luò)處理器GNP雖然提供高度的可編程性支持,然而在功耗及芯片集成度方面的天然劣勢使其難以滿足飛速增長的網(wǎng)絡(luò)通信帶寬的需求。
針對上述問題,Intel公司提出未來的通信處理平臺應(yīng)該以通用多核CPU為核心,采用芯片組方式,從而在性能與可編程性間獲得完美折衷。Intel的Crystal Forest通信處理平臺[6]采 用雙Xeon處理器作為分組處理的主要功能單元,通過集成片外QuickAssist加速器,將DPI、加解密以及解壓縮等常用的分組處理功能卸載到 QuickAssist加速器中。從軟件層面看,QuickAssist通過提供加速器抽象層,隔離各種物理實(shí)體,從而允許上層軟件都通過統(tǒng)一接口訪問多 樣化的硬件加速器。雖然,Crystal Forest通信平臺目前僅可以支持約100Gbps的流量的線速處理,與業(yè)界高性能網(wǎng)絡(luò)處理器有一定差距,但是我們認(rèn)為Intel提出的基于通用多核 CPU的多芯片解決方案值得思考和借鑒。多芯片解決方案可以有效緩解對網(wǎng)絡(luò)處理器芯片設(shè)計(jì)的性能壓力,并在系統(tǒng)升級、部署方面提供更大的靈活性。在思科以 及阿爾卡特朗訊最近推出的高性能核心路由器中(例如思科CRS-3),高性能轉(zhuǎn)發(fā)線卡都集成多個(gè)處理芯片協(xié)同完成分組轉(zhuǎn)發(fā)處理業(yè)務(wù)。
國產(chǎn)化技術(shù)途徑
在把握了網(wǎng)絡(luò)處理器芯片研制挑戰(zhàn)以及發(fā)展趨勢的基礎(chǔ)上,我們認(rèn)為基于國產(chǎn)通用多核CPU+可編程網(wǎng)絡(luò)處理引擎(NPE)的架構(gòu)是網(wǎng)絡(luò)處理器芯片 國產(chǎn)化一條現(xiàn)實(shí)可行的技術(shù)途徑。實(shí)際上,網(wǎng)絡(luò)處理器研制與高性能CPU及通用操作系統(tǒng)研制有很多共性技術(shù),例如高性能RISC核設(shè)計(jì)、片上網(wǎng)絡(luò)、低延時(shí)高 帶寬的存儲器接口、操作系統(tǒng)和編譯系統(tǒng)等。以飛騰、龍芯為代表的國產(chǎn)通用多核CPU以及以麒麟為代表的國產(chǎn)操作系統(tǒng)在國家核高基等項(xiàng)目支持下已取得巨大突 破,其相關(guān)成果已經(jīng)在國家信息系統(tǒng)建設(shè)中發(fā)揮重要作用。因此,有效利用國產(chǎn)高性能CPU和操作系統(tǒng)的研究成果,并對其網(wǎng)絡(luò)處理能力進(jìn)行充分挖潛,是縮短國 產(chǎn)網(wǎng)絡(luò)處理器芯片研制周期,降低研制成本和風(fēng)險(xiǎn)的有效途徑。
然而,通用多核CPU主要面向通用計(jì)算領(lǐng)域設(shè)計(jì),適用于計(jì)算密集型的應(yīng)用。而網(wǎng)絡(luò)處理器則主要面向網(wǎng)絡(luò)處理領(lǐng)域設(shè)計(jì),適用于訪存密集型應(yīng)用。如 何提高通用CPU的訪存計(jì)算比(MCR)是決定能否利用通用CPU進(jìn)行網(wǎng)絡(luò)處理的關(guān)鍵。針對這一問題,國防科技大學(xué)課題組對網(wǎng)絡(luò)處理器實(shí)現(xiàn)模型和途徑進(jìn)行 了深入研究和探索,提出應(yīng)擺脫傳統(tǒng)以多核軟件為核心的實(shí)現(xiàn)模型,由可編程硬件(即NPE)定義網(wǎng)絡(luò)報(bào)文的處理路徑,并對性能敏感的功能進(jìn)行硬化卸載,從而 有效降低通用多核CPU軟件的處理壓力,實(shí)現(xiàn)系統(tǒng)性能提升。這種“硬件定義”的處理模型允許在不改變現(xiàn)有通用多核CPU內(nèi)部架構(gòu)、不對其內(nèi)部實(shí)現(xiàn)進(jìn)行特定 優(yōu)化的前提下,縮短網(wǎng)絡(luò)處理器研制周期,降低研制成本,從而有效加速網(wǎng)絡(luò)處理器芯片的國產(chǎn)化進(jìn)程。
總結(jié)
網(wǎng)絡(luò)處理器芯片作為構(gòu)建網(wǎng)絡(luò)通信基礎(chǔ)設(shè)施的核心器件,其國產(chǎn)化必須綜合考慮芯片的設(shè)計(jì)復(fù)雜度和研制難度,準(zhǔn)確把握技術(shù)發(fā)展趨勢。我們認(rèn)為,國產(chǎn)通用多核CPU與可編程網(wǎng)絡(luò)處理引擎(NPE)相結(jié)合的體系結(jié)構(gòu)是解決網(wǎng)絡(luò)處理器“中國芯”的問題的一條希望之路。
參考文獻(xiàn):
[1] 阿爾卡特朗訊FP3網(wǎng)絡(luò)處理器[R/OL],http://www.alcatel-lucent.com/products/fp3.
[2]Marvell Xelerated網(wǎng)絡(luò)處理器[R/OL],http://www.marvell.com/network-processors/xelerated-hx/.
[3]EZchip NP-5網(wǎng)絡(luò)處理器[R/OL],http://www.ezchip.com/p_np5.htm.
[4]Broadcom XLP900網(wǎng)絡(luò)處理器[R/OL], http://www.broadcom.com/products/Processors/Enterprise/XLP900-Series
[5]CaviumOcteon III網(wǎng)絡(luò)處理器[R/OL],http://www.cavium.com/OCTEON-III_CN7XXX.html.
[6]TianTian, Alexander Belousov. Intel下一代通信平臺數(shù)據(jù)平面解決方案,2012.12.