
摘 要: 介紹一個智能輔助學(xué)習(xí)平臺的設(shè)計(jì)理念、功能和結(jié)構(gòu)。它根據(jù)相同領(lǐng)域的電子資料集合自動學(xué)習(xí)領(lǐng)域本體,基于所學(xué)本體自動建立不同資料之間的語義關(guān)聯(lián),應(yīng)用語義關(guān)聯(lián)自動實(shí)現(xiàn)學(xué)習(xí)資料之間的參考關(guān)系。其結(jié)果是將相同領(lǐng)域的原來相互獨(dú)立的多種資料自動按語義融合為一個整體,以提高學(xué)習(xí)和研究工作的資料應(yīng)用效率。
關(guān)鍵詞: 領(lǐng)域本體;電子學(xué)習(xí);本體學(xué)習(xí)
目前在網(wǎng)上和電子圖書館已有海量的知識資源,而如何更高效地應(yīng)用這些電子知識資源已成為一個熱門研究和應(yīng)用領(lǐng)域。與傳統(tǒng)紙質(zhì)知識資源相比,電子知識資源幾乎不受容量的限制,能夠用計(jì)算機(jī)對它們進(jìn)行快速訪問和處理。
在學(xué)習(xí)一門新知識時(shí)通常需要對一個主題參考多種資料才能夠透徹地理解,在研究工作中,甚至需要分析能夠找到的全部知識資源。對紙質(zhì)知識進(jìn)行這種資料的查詢和引用是一個費(fèi)時(shí)費(fèi)力、效率低下的工作。本文介紹一個智能輔助學(xué)習(xí)工具,它幫助用戶在學(xué)習(xí)一份資料的某個知識點(diǎn)時(shí)能夠自動快速定位其他資料的相同或相近知識點(diǎn),省去學(xué)習(xí)時(shí)查找資料的時(shí)間。
1 系統(tǒng)基本設(shè)計(jì)理念與功能概述
本節(jié)對文中系統(tǒng)用到的本體(ontology)知識點(diǎn)、知識項(xiàng)和等核心概念進(jìn)行定義,并闡明本設(shè)計(jì)的基本理念,并簡要介紹系統(tǒng)實(shí)現(xiàn)的核心功能。
1.1 系統(tǒng)的基本概念和設(shè)計(jì)理念
(1)本體
本體是知識工程領(lǐng)域一個非常重要的概念,它源于哲學(xué)的本體論(ontology),在人工智能中被借用過來表示特定領(lǐng)域知識體系中的概念體系。許多研究者對它有不同的定義,得到公認(rèn)的是Tom Gruber定義:本體是關(guān)于共享概念的協(xié)議。
本體在實(shí)際應(yīng)用中表現(xiàn)為特定領(lǐng)域中專業(yè)術(shù)語和術(shù)語之間語義關(guān)系的集合,是支持本系統(tǒng)知識項(xiàng)之間基于語義自動關(guān)聯(lián)的核心組件。例如在數(shù)據(jù)庫領(lǐng)域,“數(shù)據(jù)庫”、“鎖”、“數(shù)據(jù)庫管理系統(tǒng)”、“DBMS”等都是術(shù)語,術(shù)語之間存在多種語義關(guān)系,如同義關(guān)系、對義關(guān)系、反義關(guān)系、同位關(guān)系、上下位關(guān)系、部分整體關(guān)系等。在本體中,“數(shù)據(jù)庫管理系統(tǒng)”與“DBMS”就是同義關(guān)系。而概念是以文字形式的術(shù)語所描述的超出文字的意義,同義的術(shù)語表示相同的概念。
(2)知識點(diǎn)、知識的形態(tài)與知識項(xiàng)
知識點(diǎn)是教學(xué)中常用的一個概念,它是從教育和學(xué)習(xí)的角度對一個領(lǐng)域知識進(jìn)行標(biāo)志和處理的基本單位。一般在教材編寫中將一個小節(jié)作為一個知識點(diǎn)。在概念上,本系統(tǒng)也以知識點(diǎn)作為知識處理的單位之一。
知識還有不同的形態(tài),文字、圖形、表格、視頻等是知識表示的不同形態(tài)。本系統(tǒng)將知識的不同形態(tài)分別進(jìn)行存儲和處理。
知識項(xiàng)是知識點(diǎn)的具體化,是知識點(diǎn)與知識形態(tài)的結(jié)合。本系統(tǒng)中知識點(diǎn)和知識形態(tài)都是抽象的概念,對于給定的知識點(diǎn)只有通過具體的形態(tài)表示出來才被具體化。知識項(xiàng)是本系統(tǒng)對知識處理的最小單位。
(3)設(shè)計(jì)理念
將領(lǐng)域知識分為3個層次:最高層用本體實(shí)現(xiàn)領(lǐng)域概念知識的橫向(關(guān)聯(lián))和縱向(層次化)語義關(guān)系網(wǎng),在第二層用知識點(diǎn)描述領(lǐng)域概念知識的有效組合,第三層通過知識項(xiàng)表示知識的具體形態(tài)。這三層實(shí)現(xiàn)了由整體到局部、由抽象到具體領(lǐng)域知識的語義關(guān)聯(lián)和層次化框架。
在語義層面,應(yīng)用本體作為領(lǐng)域知識的概念骨架,通過本體建立系統(tǒng)中各個知識項(xiàng)之間的語義聯(lián)系,基于此語義聯(lián)系幫助讀者/研究者動態(tài)檢索相關(guān)的知識項(xiàng)。在數(shù)據(jù)的存儲層面,將整體的文檔知識按知識點(diǎn)和知識形態(tài)存放在數(shù)據(jù)庫中。在實(shí)現(xiàn)層,將自動化技術(shù)和人工處理相結(jié)合,應(yīng)用自然語言處理技術(shù)自動地識別和提取領(lǐng)域?qū)I(yè)詞匯,并應(yīng)用互信息等技術(shù)識別領(lǐng)域詞匯之間的聚類關(guān)系,再輔以人工的鑒別和修正,達(dá)到效率和質(zhì)量的折衷。
1.2 系統(tǒng)基本功能
為讓讀者對系統(tǒng)有一個整體了解,先從外觀上介紹系統(tǒng)的功能。系統(tǒng)可視為一個服務(wù)系統(tǒng),在功能上可分為服務(wù)準(zhǔn)備和服務(wù)實(shí)現(xiàn)2個部分。本文以數(shù)據(jù)庫領(lǐng)域?yàn)槔榻B本系統(tǒng)功能。
服務(wù)準(zhǔn)備部分的主要功能是根據(jù)不同主題或領(lǐng)域建立服務(wù)項(xiàng)目,針對每個服務(wù)項(xiàng)目選擇和導(dǎo)入相關(guān)的電子文檔(知識資源),根據(jù)所選領(lǐng)域中導(dǎo)入的知識資源自動學(xué)習(xí)和創(chuàng)建領(lǐng)域本體,包括領(lǐng)域詞匯和詞匯之間關(guān)系的確認(rèn)。在對領(lǐng)域詞匯關(guān)系的精確度要求不高的情況下,這一部分工作可由普通系統(tǒng)維護(hù)和管理工作人員進(jìn)行,當(dāng)要求精確地確定詞匯間關(guān)系時(shí),需要領(lǐng)域的專業(yè)人士進(jìn)行人工調(diào)整和修正。
圖1是對所導(dǎo)入數(shù)據(jù)庫領(lǐng)域的電子文檔進(jìn)行自動識別領(lǐng)域詞匯后,由領(lǐng)域?qū)<?或教師)對它們之間的語義關(guān)系作進(jìn)一步確定和編輯的用戶界面。

服務(wù)實(shí)現(xiàn)部分由學(xué)習(xí)者操作,學(xué)習(xí)者選取要學(xué)習(xí)的領(lǐng)域,以該領(lǐng)域某個知識源為主線查看其中的知識點(diǎn),而可用相關(guān)資源的鏈接將自動出現(xiàn)在導(dǎo)航窗口中,實(shí)現(xiàn)同時(shí)閱讀和參考多個知識資源。在圖2中,學(xué)習(xí)者選取了《數(shù)據(jù)庫基礎(chǔ)及應(yīng)用》這一本書作為學(xué)習(xí)主線,在學(xué)習(xí)‘數(shù)據(jù)模型’的主要數(shù)據(jù)模型這一小節(jié)時(shí),相關(guān)的內(nèi)容在主窗口顯示(圖形和文字分開),在主窗口下方的導(dǎo)航欄顯示了在其他書本和章節(jié)中相關(guān)內(nèi)容的鏈接。任意選取其中一個鏈接,將顯示其中的詳細(xì)內(nèi)容。

2 基于語料庫自動學(xué)習(xí)領(lǐng)域本體
本設(shè)計(jì)應(yīng)用基于語料庫的自然語言處理技術(shù)從電子文檔資源中識別領(lǐng)域?qū)I(yè)詞匯,用互信息技術(shù)分析領(lǐng)域詞匯之間的可能關(guān)系,再輔以人工鑒別和修正。圖3說明了用計(jì)算機(jī)輔助本體構(gòu)造過程的3個基本步驟:選擇和準(zhǔn)備知識資源、提取領(lǐng)域術(shù)語詞匯、建立詞匯術(shù)語之間語義關(guān)系。圖中以圓角矩形表示的步驟由系統(tǒng)自動完成;用橢圓表示的步驟由系統(tǒng)提供人機(jī)交互界面,以人工操作完成;虛線的人機(jī)操作在精度要求不高時(shí)可以省略。
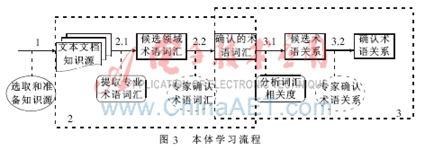
2.1 知識資源預(yù)處理
領(lǐng)域本體學(xué)習(xí)的第一步是準(zhǔn)備電子知識資源,電子版的教程是較理想的。這一步的基本任務(wù)是導(dǎo)入電子版的知識資源,并對導(dǎo)入的資源格式進(jìn)行規(guī)范化處理,轉(zhuǎn)換為系統(tǒng)可識別和處理的知識項(xiàng)單元。文字部分被轉(zhuǎn)換為text格式,圖形部分統(tǒng)一為通用的jpg/bpm等格式并加上圖形的標(biāo)題存入數(shù)據(jù)庫中。這一步不需要深入的領(lǐng)域?qū)I(yè)知識,可由一般系統(tǒng)服務(wù)人員進(jìn)行。
2.2 識別領(lǐng)域詞匯
第二步主要實(shí)現(xiàn)從所導(dǎo)入的文本知識資源中識別領(lǐng)域詞匯,并最終確認(rèn)。這一步主要是取得領(lǐng)域詞匯的詞干,即構(gòu)成領(lǐng)域術(shù)語的最基礎(chǔ)元素。一般文本挖掘方法在識別詞匯時(shí)事先篩選某些常用詞匯作為高頻詞,它們在識別過程中被排除。這里不采用此方法,因?yàn)橹形牡念I(lǐng)域詞匯通常也會使用某些常用字/詞,對它們賦予新的領(lǐng)域含義。本系統(tǒng)應(yīng)用基于語料庫[2]的自然語言技術(shù),先對文本的知識資源進(jìn)行中文分詞處理[3],再對所出現(xiàn)的詞匯進(jìn)行詞頻分析,將資源文檔中的詞頻與語料庫詞頻進(jìn)行對比,頻率顯著高于語料庫中的頻率時(shí),推斷它為領(lǐng)域詞匯。由自動系統(tǒng)識別出領(lǐng)域詞匯后,可由領(lǐng)域?qū)<以龠M(jìn)行確認(rèn)和修正。
2.3 識別詞匯關(guān)系及組合術(shù)語
第三步的目的是識別并確認(rèn)領(lǐng)域詞匯之間的關(guān)系,根據(jù)它們之間的有效組合并得到領(lǐng)域術(shù)語集合。
從構(gòu)詞法上看,專業(yè)領(lǐng)域中的詞匯有3種基本構(gòu)成形式:給普通詞匯賦予新的領(lǐng)域含義;創(chuàng)建一個全新的詞;以前兩種形式為詞干加上前綴或后綴形成新詞。
第一種領(lǐng)域詞匯通過分詞系統(tǒng)自動劃分為一個獨(dú)立的詞,在語料庫中也會出現(xiàn),它可通過上一步的詞頻對比分析識別得到。第二種領(lǐng)域詞匯在自動分詞系統(tǒng)中無法分出,在語料庫中也沒有該詞。它由若干單字或常用詞組合而成。第二種和第三種可應(yīng)用信息論中的互信息,自動地從樣本文檔中識別。信息論中互信息反映了一種信息與另一種信息相關(guān)聯(lián)的程度,用下式表示:
M(a,b)=log2(P(a|b)/P(a))
其中P(a)、P(b)分別表示事件a和b出現(xiàn)的概率,P(a|b)為事件a相對于事件b的條件概率。在本系統(tǒng)中,以樣本文檔中總詞數(shù)cntTotal為基數(shù),以詞出現(xiàn)的次數(shù)c除以總詞數(shù)作為概率估計(jì)值。P(a|b)用a與b同現(xiàn)次數(shù)除以b出現(xiàn)次數(shù)作為估計(jì)值。僅對文檔中先后同現(xiàn)2次以上的詞進(jìn)行互信息統(tǒng)計(jì)分析,應(yīng)用互信息計(jì)算公式通過編程計(jì)算得到詞匯兩兩組合的相關(guān)度表。以詞匯之間的組合關(guān)系為邊,以相關(guān)度為權(quán)值構(gòu)造一個有向加權(quán)多圖。圖4就是對數(shù)據(jù)庫電子文檔應(yīng)用互信息計(jì)算得到的加權(quán)圖之一。根據(jù)它就可以在一定置信度范圍內(nèi)獲得詞匯之間的可能組合關(guān)系。
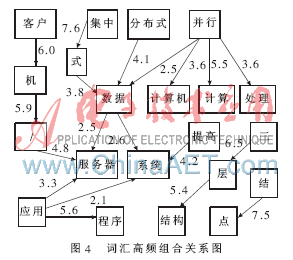
詞匯的組合關(guān)系蘊(yùn)含著語義關(guān)系。基本的語義關(guān)系包括同義、上下位、反義、對義、部分與整體關(guān)系等。對這些關(guān)系還分別賦以一個相關(guān)度值,以反映它們之間關(guān)聯(lián)程度。自動建立了所識別詞匯之間的組合關(guān)系后,賦予詞匯之間默認(rèn)的關(guān)系和相關(guān)度值。有領(lǐng)域經(jīng)驗(yàn)的人可對這些關(guān)系和相關(guān)度值進(jìn)行編輯,在實(shí)際的輔助學(xué)習(xí)平臺應(yīng)用中由教師進(jìn)行操作。圖1就是實(shí)現(xiàn)此功能的操作界面。
本文介紹了一個應(yīng)用所構(gòu)造本體的智能輔助學(xué)習(xí)系統(tǒng)的功能、設(shè)計(jì)想念和實(shí)現(xiàn)方法。通過該系統(tǒng)它可將一個學(xué)科(領(lǐng)域)的多種資源存入數(shù)據(jù)庫中,實(shí)現(xiàn)學(xué)習(xí)某一主題的知識時(shí),可以同時(shí)對比閱讀多種相同或相關(guān)主題的內(nèi)容,省去手工查閱多種資料的麻煩,還可直接跳轉(zhuǎn)到另一種資源,以它為主繼續(xù)學(xué)習(xí),這給學(xué)習(xí)和研究帶來很大方便。下一步的工作是將該技術(shù)應(yīng)用到企業(yè)知識管理中。
參考文獻(xiàn)
[1] 周寧,張玉峰,張李義,等.信息可視化與知識檢索[M].北京:科學(xué)出版社,2005.
[2] 北京大學(xué)計(jì)算語言學(xué)研究所.人民日報(bào)語料庫[DB/OL].
[2001-05-10].http://www.icl.pku.edu.cn/icl_groups/corpus/dwldform1.asp.
[3] 張華平,劉群.計(jì)算所漢語詞法分析系統(tǒng)ICTCLAS,http://sewm.pku.edu.cn/QA/reference/ICTCLAS/FreeICTCLAS/,2002.