
摘 要: 介紹了螞蟻算法" title="螞蟻算法">螞蟻算法,并進(jìn)一步將這種新型的生物優(yōu)化思想進(jìn)行擴(kuò)展,應(yīng)用于網(wǎng)格系統(tǒng)" title="網(wǎng)格系統(tǒng)">網(wǎng)格系統(tǒng)中的任務(wù)調(diào)度" title="任務(wù)調(diào)度">任務(wù)調(diào)度問題。通過增加負(fù)載平衡因子,將用戶提交的任務(wù)合理地映射到相對(duì)空閑的資源上去,經(jīng)仿真平臺(tái)實(shí)驗(yàn),可有效地實(shí)現(xiàn)任務(wù)的合理調(diào)度和網(wǎng)格系統(tǒng)的負(fù)載平衡。
關(guān)鍵詞: 網(wǎng)格計(jì)算 任務(wù)調(diào)度 螞蟻算法 NP 負(fù)載平衡因子
?
網(wǎng)格任務(wù)調(diào)度是網(wǎng)格計(jì)算的關(guān)鍵問題之一。大量任務(wù)請(qǐng)求使用網(wǎng)格資源時(shí),必須對(duì)它們進(jìn)行合理調(diào)度才能達(dá)到資源的優(yōu)化利用。然而現(xiàn)有的一些任務(wù)調(diào)度方法[1]如Backfilling[2],F(xiàn)CFS(First Come First Service)等并不能很好地適應(yīng)網(wǎng)格資源的特點(diǎn),如調(diào)度問題的NP完全性、資源的異構(gòu)性以及資源分配決策的并行性和分布性等。
鑒于構(gòu)造性方法質(zhì)量較差且缺少柔性,螞蟻算法就成了解決此類問題的首選。本文提出一種基于改進(jìn)螞蟻算法[3]的網(wǎng)格任務(wù)調(diào)度方法,它充分考慮了資源的鏈路帶寬、CPU計(jì)算處理能力" title="處理能力">處理能力、磁盤容量以及資源的單位定價(jià)等因素,并把這些因素綜合起來確定資源的信息素" title="信息素">信息素濃度。在保證資源利用率的同時(shí),能顯著改善網(wǎng)格系統(tǒng)的負(fù)載均衡問題。
1 螞蟻算法介紹
螞蟻算法[4,5]由意大利學(xué)者M(jìn).Dorigo等人首先提出,是一種源于大自然生物世界的新的仿生類算法。作為通用型隨機(jī)優(yōu)化方法,它吸收了昆蟲王國中螞蟻的行為特征,通過其內(nèi)在的搜索機(jī)制,在一系列困難的組合優(yōu)化問題求解中取得了成效。由于在模擬仿真中使用的是人工螞蟻概念,因此有時(shí)亦被稱為螞蟻系統(tǒng)[6]。
1.1 螞蟻算法的原理
用于優(yōu)化領(lǐng)域的人工螞蟻算法,其基本原理吸收了生物界中螞蟻群體行為的某些顯著特征:(1)察覺小范圍內(nèi)狀況并判斷出是否有食物或其他同類的信息素軌跡。(2)釋放自己的信息素。(3)所遺留的信息素?cái)?shù)量會(huì)隨時(shí)間而逐步減少。
1.2 螞蟻算法的特點(diǎn)
螞蟻算法是一種智能優(yōu)化仿生算法,其顯著特點(diǎn)為:(1)其原理是一種正反饋機(jī)制或稱增強(qiáng)型學(xué)習(xí)系統(tǒng),它通過信息素的不斷更新達(dá)到最終收斂于最優(yōu)路徑上。(2)它是一種分布式的優(yōu)化方法,不僅適合目前的串行計(jì)算機(jī),而且適合未來的并行計(jì)算機(jī)。(3)它是一種全局優(yōu)化的方法,不僅可用于求解單目標(biāo)優(yōu)化問題,而且可用于求解多目標(biāo)優(yōu)化問題。(4)它是一種啟發(fā)式算法,計(jì)算復(fù)雜度為O(NC*m*n2),其中NC是迭代次數(shù),m是螞蟻數(shù)目,n是目的節(jié)點(diǎn)數(shù)目。
2 網(wǎng)格任務(wù)調(diào)度仿真系統(tǒng)
為了集中研究任務(wù)調(diào)度問題,排除其他復(fù)雜因素的干擾,設(shè)計(jì)了一個(gè)比較通用的結(jié)構(gòu)簡單的但功能齊全的任務(wù)調(diào)度仿真系統(tǒng)。
2.1 仿真系統(tǒng)結(jié)構(gòu)
仿真系統(tǒng)結(jié)構(gòu)如圖1所示。
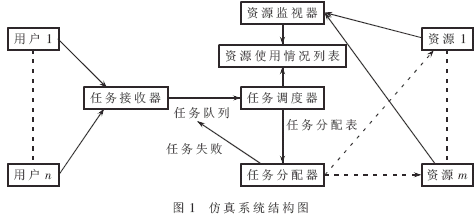
2.2 仿真系統(tǒng)工作流程
(1)當(dāng)用戶提交一個(gè)任務(wù)請(qǐng)求(包含任務(wù)的任務(wù)量、通信量、任務(wù)提交時(shí)間、時(shí)間限度等參數(shù))時(shí),觸發(fā)任務(wù)接收器,任務(wù)接收器就將新任務(wù)加入到任務(wù)隊(duì)列排隊(duì)。任務(wù)隊(duì)列按照優(yōu)先級(jí)排序,可以根據(jù)不同用戶的不同需要(用戶等級(jí)、任務(wù)緊迫度等)對(duì)進(jìn)入隊(duì)列的任務(wù)進(jìn)行排序。
(2)仿真環(huán)境中的計(jì)時(shí)器每隔一定時(shí)間觸發(fā)任務(wù)調(diào)度器,任務(wù)調(diào)度器就會(huì)從任務(wù)隊(duì)列中取出待處理的任務(wù),并從資源監(jiān)視器中獲得當(dāng)前系統(tǒng)資源使用情況列表。
(3)根據(jù)待處理任務(wù)及系統(tǒng)資源調(diào)用任務(wù)分配策略器,產(chǎn)生一個(gè)最優(yōu)化的任務(wù)分配表。
(4)根據(jù)最優(yōu)化任務(wù)分配表,調(diào)用任務(wù)分配器,執(zhí)行任務(wù)分配表中的任務(wù)。如果任務(wù)順利完成,則將任務(wù)占有的資源釋放并加入到資源列表中;如果任務(wù)失敗,則釋放該任務(wù)占有的系統(tǒng)資源,并將失敗的任務(wù)插入到任務(wù)隊(duì)列中,以待下次調(diào)度。
(5)當(dāng)不能從任務(wù)隊(duì)列中獲得任務(wù)時(shí),表明所有任務(wù)都已經(jīng)完成,將根據(jù)運(yùn)行中得到的數(shù)據(jù)產(chǎn)生需要的統(tǒng)計(jì)結(jié)果。
3 螞蟻算法在網(wǎng)格任務(wù)調(diào)度中的應(yīng)用
3.1 改進(jìn)后的螞蟻算法思想
當(dāng)一個(gè)新資源s加入網(wǎng)格系統(tǒng)時(shí),需要提供其鏈路帶寬r(Mbps)、CPU個(gè)數(shù)m和處理能力p(MIPS)、磁盤存儲(chǔ)容量f(MB)以及此資源的單位定價(jià)k等基本參數(shù),資源發(fā)現(xiàn)器(類似于GLOBUS中的GIIS)據(jù)此可以初始化該資源的各種信息素(每種信息素對(duì)應(yīng)于一個(gè)基本參數(shù))。在初始化各種信息素之前,先定義資源中各基本參數(shù)的閾值:
rmax=r0 mmax=m0 pmax=p0 fmax=f0 kmax=k0
并規(guī)定:如果資源的各參數(shù)值超過閾值,則統(tǒng)一以閾值進(jìn)行后面的計(jì)算。
然后初始化各種信息素:
Tsr(0)=r/r0*100% 鏈路帶寬r的信息素
Tsm(0)=(m*p)/(m0*p0)*100% CPU計(jì)算能力的信息素
Tsf(0)=f/f0*100% 磁盤存儲(chǔ)容量f的信息素
Tsk(0)=k/k0*100% 資源的單位定價(jià)k的信息素 (1)
則資源s的初始化總信息素為:
Ts(0)=a*Tsr(0)+b*Tsm(0)+c*Tsf(0)+d*Tsk(0) (2)
其中,a+b+c+d=1,a,b,c,d分別表示鏈路帶寬信息素、CPU計(jì)算能力信息素、磁盤存儲(chǔ)容量信息素以及資源的單位定價(jià)信息素在該資源總信息素中所占的比重。
每當(dāng)有新資源加入網(wǎng)格系統(tǒng),或某資源退出或者掉線,或任務(wù)成功或失敗返回時(shí),資源信息素都會(huì)隨之改變:Tsnew=g*Tsold+△Ts,△Ts是信息素改變量,g表示信息素持久性(取0.6),1-g表示信息素的揮發(fā)性[7]。
當(dāng)任務(wù)從資源s成功返回時(shí),△Ts=Ce*K,Ce是獎(jiǎng)勵(lì)參數(shù),取0.6,表示增加成功經(jīng)驗(yàn);當(dāng)任務(wù)從資源s失敗返回時(shí),△Ts=Cp*K,Cp是懲罰因子,取-1.2.
資源信息素改變時(shí),任務(wù)分配概率隨之改變:
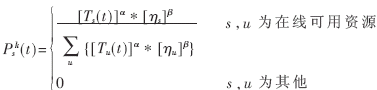
式中,Ts(t)為時(shí)間t時(shí)資源s的信息素濃度,ηs表示資源s的固有屬性,ηs=Ts(0);α表示信息素的重要性,β表示資源固有屬性的重要性。
3.2 改進(jìn)后的螞蟻算法流程
基于上面的公式和思想,設(shè)計(jì)了下面的用于網(wǎng)格系統(tǒng)中任務(wù)調(diào)度的算法,該算法分為9個(gè)步驟:
(1)利用公式(1)初始化所有資源的各種信息素,利用公式(2)初始化各資源的總信息素。
(2)調(diào)度器接收當(dāng)前從用戶發(fā)送來的實(shí)驗(yàn)數(shù)據(jù),即隨機(jī)任務(wù)。
(3)對(duì)當(dāng)前實(shí)驗(yàn)的每個(gè)任務(wù),依據(jù)其分配給每個(gè)資源的概率判斷使用哪個(gè)資源。具體做法是以下(4)~(6)。
(4)利用公式:
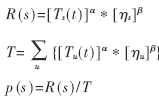
算出該任務(wù)分配給每個(gè)資源的概率。其中,ηs表示資源s的固有屬性,ηs=Ts(0);Ts(t)是資源s的信息素濃度;α表示信息素的重要性,取α=0.5;β表示資源固有屬性的重要性;u代表系統(tǒng)中所有可用資源。
(5)依據(jù)概率將任務(wù)分配給一個(gè)資源。
(6)利用公式:
Tsr(t′)=Ts(t)*p-0.0005L1
Tsr(t)=Tsr(t′)
Tsm(t′)=Ts(t)*p-0.0005L2
Tsm(t)=Tsm(t′)
對(duì)鏈路帶寬信息素、CPU計(jì)算能力信息素進(jìn)行更新。而磁盤容量信息素及資源單位定價(jià)信息素暫時(shí)不變。其中,L1,L2為任務(wù)的通信量及計(jì)算量。然后根據(jù)公式:Ts(t)=a*Tsr(t)+b*Tsm(t)+c*Tsf(t)+d*Tsk(t)將該資源的信息素進(jìn)行更新。
(7)將當(dāng)前實(shí)驗(yàn)的所有任務(wù)都分配給資源后,則等待任務(wù)的返回。如果任務(wù)成功返回,則利用以下公式:
Tsr(t+1)=p*Tsr(t)+0.6*L1
Tsm(t+1)=p*Tsm(t)+0.6*L2
Tsf(t+1)=p*Tsf(t)+0.6*L3
Tsk(t+1)=Tsk(t)
Ts(t+1)=a*Tsr(t+1)+b*Tsm(t+1)+c*Tsf(t+1)+d*Tsk(t+1)
對(duì)該資源的信息素進(jìn)行更新。其中,L3為任務(wù)在計(jì)算過程中占用磁盤容量最大時(shí)的值。
如果任務(wù)失敗返回,則利用公式:
Tsr(t+1)=p*Tsr(t)-1.2*L1
Tsm(t+1)=p*Tsm(t)-1.2*L2
Tsf(t+1)=p*Tsf(t)-1.2*L3
Tsk(t+1)=Tsk(t)
Ts(t+1)=a*Tsr(t+1)+b*Tsm(t+1)+c*Tsf(t+1)+d*Tsk(t+1)
對(duì)該資源的信息素進(jìn)行更新。
(8)重復(fù)(3)~(7),直到當(dāng)前實(shí)驗(yàn)的所有任務(wù)都成功返回為止。
(9)重復(fù)(2)~(8),直到所有用戶實(shí)驗(yàn)都被處理完為止。
3.3 負(fù)載平衡因子的添加
當(dāng)某個(gè)資源負(fù)載很重時(shí),很容易成為網(wǎng)格計(jì)算的瓶頸,影響所有任務(wù)的及時(shí)完成。改進(jìn)后的螞蟻算法,在很大程度上實(shí)現(xiàn)了負(fù)載平衡。為了取得更好的負(fù)載平衡效果,要不斷地探測資源的負(fù)載及其任務(wù)完成情況,以便對(duì)以后新任務(wù)的分配產(chǎn)生積極的影響。同時(shí)通過把各資源的負(fù)載完成率的差值控制在一個(gè)較小的門限之內(nèi)以保證負(fù)載均衡。本文在螞蟻算法中引入一個(gè)負(fù)載平衡因子λ。
λ=u/Ts(0)
式中,u為資源上尚未完成的任務(wù)量,而Ts(0)基本上可以代表某資源的處理能力。
每次任務(wù)完成時(shí)的信息素改變量為△Ts+c/λ(c為調(diào)節(jié)因子),即如果對(duì)未完成任務(wù)中所需處理時(shí)間長的節(jié)點(diǎn),將資源信息素降低一些,則所需處理時(shí)間短的節(jié)點(diǎn)信息素就增加一些。這樣就能保證任務(wù)負(fù)載率盡快逼近同一個(gè)值,在以后分配任務(wù)的過程中,系統(tǒng)的負(fù)載均衡能力就會(huì)得到進(jìn)一步提高。
4 實(shí)驗(yàn)結(jié)果
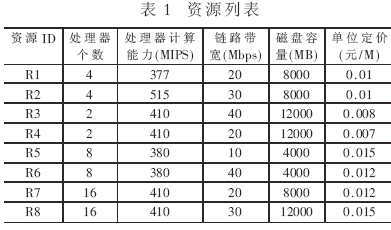
在仿真平臺(tái)下,用8個(gè)資源和800個(gè)任務(wù)進(jìn)行模擬實(shí)驗(yàn)。資源情況如表1所示,任務(wù)計(jì)算量為2000M~10000M,數(shù)據(jù)通信量在10M~100M。
?
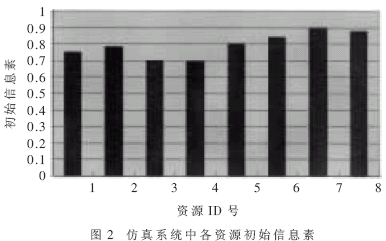
圖2給出了各資源的初始總信息素(其中,取a=0.2,b=0.5,c=0.2,d=0.1)。初始總信息素基本上代表了這個(gè)資源的處理能力。
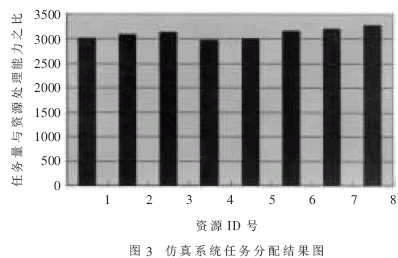
如圖3所示,所有資源的任務(wù)量與資源處理能力之比基本相同。任務(wù)最終完成情況與資源的處理能力成正比,性能好的資源分到了更多的任務(wù)。同時(shí)由此圖與資源列表可以分析出,任務(wù)的調(diào)度受處理器個(gè)數(shù)、處理器計(jì)算能力影響較大。而當(dāng)磁盤容量滿足任務(wù)存儲(chǔ)需求時(shí),其差別可以忽略不計(jì)。
針對(duì)網(wǎng)絡(luò)資源變化比較頻繁的這種復(fù)雜的網(wǎng)格環(huán)境,提出了應(yīng)用改進(jìn)的螞蟻算法進(jìn)行任務(wù)調(diào)度的策略,通過綜合考慮資源的各方面參數(shù)來確定其信息素濃度,有利于更恰當(dāng)?shù)剡x擇資源,提高了資源的利用率;同時(shí)通過引入負(fù)載平衡因子,提高了整個(gè)仿真系統(tǒng)的負(fù)載均衡能力。下一步的研究重點(diǎn)將集中在提高螞蟻算法運(yùn)行速度,加快算法的收斂時(shí)間這個(gè)問題上。有一種思想就是把螞蟻算法和一些經(jīng)典的人工智能算法結(jié)合起來,例如將螞蟻算法的應(yīng)用與神經(jīng)網(wǎng)絡(luò)的訓(xùn)練結(jié)合。
參考文獻(xiàn)
1 Lichen Zhang.Scheduling algorithm for real-time application in grid environment[C].In:System,Man and Cybernetics,2002 IEEE International Conference on,2002
2 Barry G Lawsom,Evgenia Smirni.Multiple-queue backfilling scheduling with priorities and reservations for parallel systems[J].ACM SIGMENTRICS Performance Evaluation Review,2002;29(4):40~47
3 Daniel Merkel,Martin Middendorf,Hartmut Schmeck.Ant colony optimization for resource-constrained project scheduling[J].IEEE Transaction on Evolutionary Computation,2002;6(4)
4 Marco Dorigo,Gianni Di Caro.Ant algorithms for discrete optimization[J].Artificial Life,1999;5(3):137~172
5 Marco Dorigo,Luca Maria Gambardella.Ant colony system:a cooperative learning approach to the traveling salesman problem[J].IEEE Transaction on Evolutionary Computation,1997;1(4):53~56
6 Colorini A,Marco Dorigo,Maniezzo V.An investigation of some prosperities of an ant algorithm[J].in:Proceedings of the Parallel Problem Solving from nature Conference,1992:509~520
7 Macro Dorigo,Eric Bonabeau,Guy Theraulaz.Ant algorithms and stigmergy[J].Future Generation Computer Systems,2000;16(8):851~871