
摘 要: 基于SELP算法模型原理,設(shè)計(jì)了一款高質(zhì)量多速率語(yǔ)音專用處理器芯片。芯片使用可重構(gòu)" title="可重構(gòu)">可重構(gòu)體系結(jié)構(gòu)和超長(zhǎng)指令字系統(tǒng)設(shè)計(jì)方法,將復(fù)雜度高的子程序" title="子程序">子程序進(jìn)行優(yōu)化,能夠顯著提高指令并行度。仿真結(jié)果表明,在該芯片上實(shí)現(xiàn)語(yǔ)音壓縮編碼算法,執(zhí)行效率高于相同工藝水平的通用DSP,并保持原有編碼質(zhì)量。該處理器能夠?qū)崿F(xiàn)多種類型的語(yǔ)音壓縮算法" title="壓縮算法">壓縮算法,可以達(dá)到對(duì)語(yǔ)音算法的高保密性、低復(fù)雜度和易開發(fā)性。
關(guān)鍵詞: 語(yǔ)音壓縮 專用芯片 可重構(gòu)體系結(jié)構(gòu) 超長(zhǎng)指令字
在通信過程中,為了適應(yīng)多種應(yīng)用目的,需要使用不同的語(yǔ)音壓縮編碼算法。如果利用DSP進(jìn)行編程[1],存在編程難、保密性差、成本高等缺點(diǎn);如果使用ASIC完成算法實(shí)現(xiàn),只能用于實(shí)現(xiàn)單一算法,不能擴(kuò)展到其他算法,難以進(jìn)行二次開發(fā)[2][3]。
利用可重構(gòu)體系結(jié)構(gòu)[4],可以將各類語(yǔ)音算法常用的功能模塊使用專用指令集邏輯化實(shí)現(xiàn),而對(duì)算法的可變成分仍使用基本指令集編寫,能大幅度降低程序量和編程工作量。片內(nèi)FLASH(包括程序區(qū)與數(shù)據(jù)區(qū))對(duì)外不可見,只能通過注入方式進(jìn)行修改而不能讀取。這樣,既可以有效地達(dá)到算法的保密性,又能在固化的專用指令基礎(chǔ)上方便進(jìn)行算法的改進(jìn),同時(shí)保持專用芯片制造成本低的特點(diǎn)。基于此思路開發(fā)了一種可編程專用語(yǔ)音編解碼芯片TR100。
1 SELP算法介紹
壓縮算法采用實(shí)驗(yàn)室自行開發(fā)的基于SELP(Sinusoidal Excitation Linear Prediction)的多幀聯(lián)合編碼算法[5],在線性預(yù)測(cè)正弦激勵(lì)模型的基礎(chǔ)上,引入多幀參數(shù)聯(lián)合矢量量化" title="矢量量化">矢量量化方法,進(jìn)一步壓縮幀間冗余,使語(yǔ)音譜包絡(luò)信息和余量信號(hào)得到較好表示,在0.6kbps的極低速率下,獲得了很好的重建語(yǔ)音質(zhì)量,可懂度達(dá)到90%以上。

?
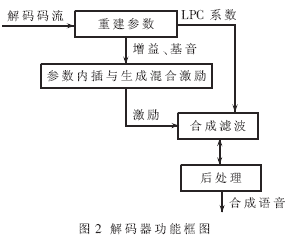
算法原理如圖1和圖2所示。輸入8kHz采樣率的語(yǔ)音信號(hào)以200個(gè)樣點(diǎn)為一幀,首先經(jīng)過預(yù)處理后進(jìn)行線性預(yù)測(cè)分析,對(duì)每幀語(yǔ)音提取預(yù)測(cè)系數(shù)、基音周期、子帶清濁音度和余量信號(hào)短時(shí)能量等參數(shù)。解碼器端采用多帶混合正弦激勵(lì),分別通過由清濁音信息調(diào)制的帶通濾波器合成激勵(lì)信號(hào),而后進(jìn)行合成濾波和后濾波產(chǎn)生合成語(yǔ)音。
在0.6kbps速率運(yùn)行時(shí)采用多幀聯(lián)合量化編碼技術(shù),將相鄰的3個(gè)語(yǔ)音幀聯(lián)合起來形成一個(gè)超幀。將預(yù)測(cè)系數(shù)轉(zhuǎn)化成線譜對(duì)系數(shù),采用基于模式的余量分裂多級(jí)矩陣量化P-RS-MSMQ算法來量化3幀聯(lián)合的線譜對(duì)(LSP)參數(shù)。模式信息來自于帶通濁音度參數(shù)量化結(jié)果,用在LSP參數(shù)的矢量量化算法上,能夠提高量化性能。LSP參數(shù)量化分三個(gè)步驟:均值去除、模式預(yù)測(cè)和對(duì)LSP殘差子矩陣進(jìn)行多級(jí)矩陣量化。用于模式預(yù)測(cè)的系數(shù)矢量是基于超幀模式的轉(zhuǎn)移,由前一超幀和當(dāng)前超幀確定。預(yù)測(cè)的殘差矢量就是余量LSP參數(shù)矢量。將當(dāng)前超幀各子幀的無(wú)偏LSP預(yù)測(cè)殘差矢量組成一個(gè)3×10的矩陣,然后分別進(jìn)行三級(jí)矩陣量化,各級(jí)量化比特?cái)?shù)分別為7、6、6、5。
根據(jù)不同的信道狀況與質(zhì)量要求,算法包括0.8kbps、1.2kbps和2.4kbps的三種速率壓縮方式,流程與0.6kbps算法基本相同,僅增加對(duì)余量信號(hào)的提取與編碼過程,其中需要進(jìn)行512點(diǎn)FFT運(yùn)算。
2 TR100芯片體系結(jié)構(gòu)設(shè)計(jì)
芯片設(shè)計(jì)工作主頻為20MHz,采用取指-譯碼-執(zhí)行3級(jí)流水線設(shè)計(jì)。語(yǔ)音接口與PCM采樣芯片連接,壓縮數(shù)據(jù)接口使用RS232標(biāo)準(zhǔn)。內(nèi)部結(jié)構(gòu)如圖3所示。
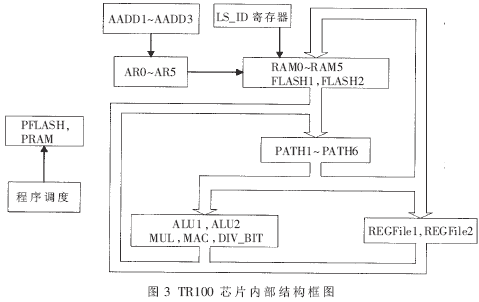
設(shè)計(jì)中采用了可重構(gòu)體系的思想。所謂可重構(gòu)體系結(jié)構(gòu),是指某一計(jì)算系統(tǒng)能夠利用可重用的硬件資源,根據(jù)不同的應(yīng)用需求,靈活地改變自身的體系結(jié)構(gòu),以便為每個(gè)特定的應(yīng)用需求提供與之相匹配的體系結(jié)構(gòu)。TR100芯片采用粗粒度可重構(gòu)體系結(jié)構(gòu),基本的可重構(gòu)硬件單元包括存儲(chǔ)系統(tǒng)、運(yùn)算單元、程序調(diào)度控制、寄存器和數(shù)據(jù)通路等類型。
存儲(chǔ)系統(tǒng)包括FLASH和RAM兩部分,為避免數(shù)據(jù)存儲(chǔ)瓶頸,芯片內(nèi)部包含2個(gè)16K×16位數(shù)據(jù)FLASH、5個(gè)2K×16位數(shù)據(jù)RAM,6個(gè)地址寄存器可以獨(dú)立對(duì)各個(gè)存儲(chǔ)器進(jìn)行單周期" title="單周期">單周期讀寫操作,3個(gè)地址運(yùn)算單元可以完成地址變換功能。
在運(yùn)算單元設(shè)計(jì)上,芯片內(nèi)部包括2個(gè)32位增強(qiáng)型算術(shù)邏輯單元ALU,能夠完成以加減運(yùn)算為中心、包括規(guī)格化、算術(shù)移位、四舍五入等輔助邏輯的復(fù)雜運(yùn)算功能;1個(gè)32位乘法器MUL;1個(gè)40位乘累加器MAC;1個(gè)16位除法器DIV。除法運(yùn)算需要10個(gè)周期,其他運(yùn)算單元均為單周期執(zhí)行。
程序調(diào)度控制包括程序存儲(chǔ)器、2級(jí)硬循環(huán)、比較跳轉(zhuǎn)部件、比較設(shè)置部件、調(diào)用/返回部件、溢出判斷等單元。程序分兩部分存儲(chǔ):程序FLASH存儲(chǔ)功能相對(duì)簡(jiǎn)單、指令長(zhǎng)度較短的部分,而程序RAM存儲(chǔ)功能較為復(fù)雜、占用運(yùn)算量較大、指令長(zhǎng)度較長(zhǎng)的部分。這種設(shè)計(jì)方法稱為專用指令集設(shè)計(jì),一方面保證了大多數(shù)語(yǔ)音壓縮算法可以在TR100芯片上可重組實(shí)時(shí)實(shí)現(xiàn),另一方面也因?yàn)橥瓿闪瞬煌惴ǖ耐ㄓ媚K而方便二次開發(fā)。
輔助系統(tǒng)包括一個(gè)二組多層寄存器,每組包括19個(gè)32位寄存器,兩個(gè)寄存器組可以被同時(shí)訪問; 6個(gè)32位選通器作為數(shù)據(jù)通路將存儲(chǔ)系統(tǒng)與運(yùn)算部件進(jìn)行互聯(lián),在保證數(shù)據(jù)連接靈活性的同時(shí)可以有效減少數(shù)據(jù)線寬;存儲(chǔ)器選通寄存器,用于設(shè)置指令訪問不同存儲(chǔ)器,以滿足多次調(diào)用相同子程序而使用不同數(shù)據(jù)的要求。
小結(jié)一下該芯片的主要特性:
1. 50ns運(yùn)算周期,20MHz主頻;
2. 2個(gè)32位增強(qiáng)型ALU, 1個(gè)32位乘法器,1個(gè)40位乘累加器;
3. 6個(gè)地址寄存器,3個(gè)地址變換部件;
4. 雙重硬件循環(huán);
5. 38×32bit雙寄存器組,支持分層窗口式訪問;
6. 5×2K字?jǐn)?shù)據(jù)RAM,2×16K字?jǐn)?shù)據(jù)FLASH;
7. 2K×256bit程序RAM;8K×64bit程序FLASH。
3 超長(zhǎng)指令字格式設(shè)計(jì)
為解決RISC體系結(jié)構(gòu)下,隨著并行操作能力增強(qiáng)而導(dǎo)致的內(nèi)部控制邏輯趨向復(fù)雜的問題,在七十年代開始,超長(zhǎng)指令字(VLIW)體系結(jié)構(gòu)開始進(jìn)入研究領(lǐng)域。它的目的是既能支持較高指令級(jí)并行性,又能使硬件控制邏輯比較簡(jiǎn)單[6]。
在針對(duì)語(yǔ)音編碼算法的專用處理器設(shè)計(jì)中,VLIW方法是非常適用的。而VLIW體系結(jié)構(gòu)能在低復(fù)雜度的控制邏輯水平上產(chǎn)生較高指令并行性,從而使芯片在低主頻下就能夠?qū)崿F(xiàn)語(yǔ)音運(yùn)算算法,這是優(yōu)于通用DSP的方面。由于算法中對(duì)資源并行度要求較高的程序模塊數(shù)量不大,可以通過全遍歷所有運(yùn)算量較大的模塊,提取所有可用的指令并行模式,在硬件控制邏輯復(fù)雜度增加很小的前提下實(shí)現(xiàn)超長(zhǎng)指令譯碼。
本文設(shè)計(jì)的VLIW指令系統(tǒng)包括兩種形態(tài):基本指令形態(tài)和專用指令形態(tài)。基本指令形態(tài)包括16位、32位、48位和64位四種指令長(zhǎng)度,并行程度較低,用于設(shè)計(jì)對(duì)資源并行性要求不高的子程序。專用指令形態(tài)包括128位、192位和256位三種指令長(zhǎng)度,并行程度較高,用于設(shè)計(jì)算法中時(shí)間復(fù)雜度較高、對(duì)資源并行性要求大的子程序。基本指令形態(tài)和專用指令形態(tài)均使用相同的指令格式,區(qū)別僅在于長(zhǎng)度不同,這樣就可以使用相同的譯碼器進(jìn)行譯碼,從而簡(jiǎn)化了電路設(shè)計(jì)。在編解碼程序運(yùn)行過程中,基本指令模塊直接從程序FLASH中取指,專用指令模塊從程序RAM中取指,均能做到單周期取指-單周期譯碼-單周期執(zhí)行(除法運(yùn)算除外)。
具體指令格式如表1。

其中,CBLength惟一確定本條指令的長(zhǎng)度;CBSF惟一確定本長(zhǎng)度下選用的指令子格式;CBCFi為第i個(gè)算子段的控制域,其編碼標(biāo)識(shí)第i個(gè)算子編碼段所對(duì)應(yīng)的算子;OPi為第i個(gè)算子編碼段編碼,其含義由CBCFi惟一確定。指令格式中的算子是指由硬件資源確定的指令字中的最小并行單元。
4 算法程序向芯片指令的移植
各類語(yǔ)音編碼算法中,會(huì)有一些子程序是通用的功能模塊。表2是在TR100上實(shí)現(xiàn)這些常用程序的執(zhí)行效率。

可以看到,整個(gè)壓縮算法中運(yùn)算量較大的模塊,如濾波器、點(diǎn)積、矢量量化等,TR100的運(yùn)行效率均明顯高于DSP,甚至能夠達(dá)到2倍以上。這是由于對(duì)于運(yùn)算、存儲(chǔ)單元訪問密集的模塊,硬件體系結(jié)構(gòu)中各個(gè)獨(dú)立的ALU、乘法器、乘累加器與7個(gè)存儲(chǔ)體在指令系統(tǒng)中也有相應(yīng)的指令格式進(jìn)行并行訪問,保證可以單周期進(jìn)行兩加兩乘運(yùn)算同時(shí)可以向存儲(chǔ)器中進(jìn)行兩讀一寫的操作。而對(duì)LPC參數(shù)計(jì)算與轉(zhuǎn)換、數(shù)學(xué)函數(shù)等雖然運(yùn)算量不大、但各種語(yǔ)音算法都要使用的模塊,TR100的運(yùn)行效率也與DSP基本相當(dāng)。這就保證了在TR100芯片上移植各類語(yǔ)音算法時(shí),受程序執(zhí)行效率的限制較小,而可以專注于算法功能的開發(fā)。同時(shí),芯片的注入功能可以對(duì)基本指令與專用指令進(jìn)行修改,開發(fā)者如果需要對(duì)現(xiàn)有專用指令進(jìn)行擴(kuò)充,可以很方便地進(jìn)行注入更改。
下面以加權(quán)矢量量化為例,說明芯片的運(yùn)算效率。在低速率語(yǔ)音算法中,由于線譜對(duì)系數(shù)常使用多幀聯(lián)合矢量量化,使得碼本的維數(shù)與規(guī)模都大為增加,導(dǎo)致搜索碼本的運(yùn)算量非常巨大。在本文SELP算法中,600速率使用的多級(jí)LSP碼本最大是30維×128個(gè)的規(guī)模,搜索時(shí)需要計(jì)算全部碼本與當(dāng)前系數(shù)的最小加權(quán)距離:

循環(huán)內(nèi)需要進(jìn)行減法和2次乘法。對(duì)于一些有并行功能的DSP,使用流水線方式進(jìn)行循環(huán)內(nèi)的操作。由于指令寬度的限制,循環(huán)體內(nèi)至少需要3個(gè)周期才能完成操作。
在TR100芯片中,專用指令集長(zhǎng)度可以達(dá)到256位,因此能夠?qū)⒀h(huán)體內(nèi)的操作使用一條指令:
REPEAT 30
ALUR1=R2-R3 || MULR=R1*ALUR1 ||
ALUR2=ALUR1*MULR || LD1 *(AR1+) ||
LD2 *(AR2+) || LD3 *(AR3+) ;
循環(huán)開始前進(jìn)行數(shù)據(jù)準(zhǔn)備,循環(huán)內(nèi)只要將所有運(yùn)算和取數(shù)操作并行起來即可正確完成求加權(quán)矢量誤差的計(jì)算。在循環(huán)體內(nèi)的一個(gè)操作周期相當(dāng)于每秒87萬(wàn)次運(yùn)算。與通用DSP的實(shí)現(xiàn)相比,本芯片可以在循環(huán)體內(nèi)減少5次運(yùn)算,對(duì)矢量搜索模塊的優(yōu)化超過4MIPS。
5 芯片性能
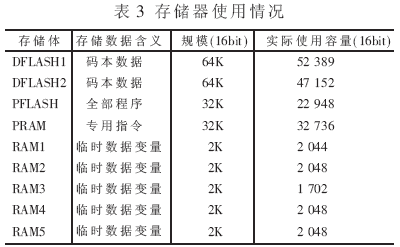
存儲(chǔ)器的使用情況如表3,需要注意的是數(shù)據(jù)FLASH中存儲(chǔ)的是4個(gè)速率的不同碼本,因此規(guī)模較大。
?
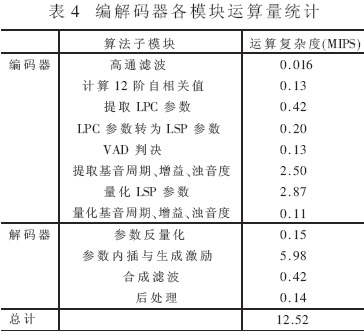
600bps速率算法各子模塊的運(yùn)算量如表4。
與C54x系列DSP實(shí)現(xiàn)結(jié)果相比,TR100芯片完成編解碼的運(yùn)算復(fù)雜度為12.5MIPS,明顯低于C54xDSP所需要的40MIPS。TR100芯片需要9.7K字變量存儲(chǔ)空間與28K字碼本存儲(chǔ)空間,與C54xDSP所需的變量存儲(chǔ)空間與碼本存儲(chǔ)空間相當(dāng)。
為了驗(yàn)證芯片編解碼工作的正確性,對(duì)比了浮點(diǎn)C程序、定點(diǎn)C程序以及芯片仿真三種情況下各個(gè)參數(shù)的重建誤差。表5中列出了三種情況下的各種結(jié)果,采用91 280幀中國(guó)軍標(biāo)語(yǔ)音測(cè)試數(shù)據(jù),可以看出芯片運(yùn)算結(jié)果達(dá)到了計(jì)算機(jī)C程序仿真的水平。

對(duì)于語(yǔ)音壓縮算法,由于基本算法模型相同,因此可以使用相同的專用處理器結(jié)構(gòu)進(jìn)行設(shè)計(jì),在保證各類算法均可實(shí)現(xiàn)的前提下,提高運(yùn)行效率。減少運(yùn)算復(fù)雜度的意義在于能夠降低芯片功耗和工藝要求。即使不同算法有各自專用的處理模塊,也可以很方便地通過注入新的專用指令來進(jìn)行修改。與DSP實(shí)現(xiàn)相比,專用處理器的運(yùn)行效率更高,開發(fā)難度更低,保密度更好,更容易降低芯片規(guī)模。
參考文獻(xiàn)
1 賈志科, 崔慧娟, 唐 昆等. 低速率語(yǔ)音編解碼專用芯片的設(shè)計(jì)[J]. 清華大學(xué)學(xué)報(bào),1999;39(5):73~76
2 McDonough J , Chang C , Kantak P, et al. A single chip QCELP vocoder for CDMA digital cellular[A]. Proceedings of IEEE Custom Integrated Circuits Conference[C]. New York, NY: IEEE, 1994;211~214
3 Byun K J, Hahn M, Kim K S. Implementation of 13 kbps QCELP vocoder ASIC[A]. Proceedings of AP-ASIC′99: The First IEEE Asia-Pacific Conference on ASICs[C]. Piscat-away, NJ: IEEE, 1999;258~261
4 王昭順, 王 沁, 曲英杰. 可重構(gòu)計(jì)算機(jī)體系結(jié)構(gòu)[J]. 北京科技大學(xué)學(xué)報(bào),2001;23(4):386~388
5 李軍林, 崔慧娟, 杜 松等. 0.8kb/s高質(zhì)量聲碼器算法[J]. 清華大學(xué)學(xué)報(bào),2003;43(1):12~15
6 王 沁. VLIW體系結(jié)構(gòu)微處理器設(shè)計(jì)考慮. 微計(jì)算機(jī)信息,1999;15(5):6~7