
使用網(wǎng)絡處理器來設計通信系統(tǒng),所設計的系統(tǒng)結構,和設計時所采用的設計方法,與傳統(tǒng)的方法相比都很不相同。影響最大的是設計工作的重點,設計人員的注意力將從硬件線路和通信協(xié)議的細節(jié)的考慮中,轉向軟件、服務以及最終用戶的技術要求方面。也就是說,設計將是以軟件為中心,以通信服務為中心,和以最終用戶的技術要求為注意的集中點。設計公司將一改過去集中注意于硬件設計的傳統(tǒng),轉而將注意力集中于用戶所需要的服務方面,并考慮如何使用軟件來實現(xiàn)用戶所需要的服務。
這些變化與進展在相當大程度上應該歸功于網(wǎng)絡處理單元(NPU, network processing unit)的推動。在這種情況下,系統(tǒng)設計人員如果對于網(wǎng)絡處理器能夠運用自如,那么就可以充分了解網(wǎng)絡處理器的作用,并且能夠感覺到,與使用網(wǎng)絡處理器隨之而來的潛在自由空間。系統(tǒng)設計人員也才有可能最大限度地發(fā)揮網(wǎng)絡處理器的潛能。
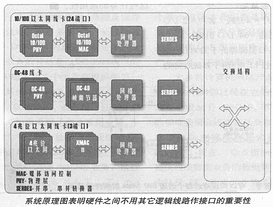
附圖是系統(tǒng)原理圖,它顯示出網(wǎng)絡處理器在系統(tǒng)設計中所處的重要位置。NPU一般位于物理層(MAC或幀調節(jié)器)線路和交換結構之間。在圖中并串行/串并行轉換器(SERDES)在NPU和交換結構造之間起接口作用。
NPU的運行速度有待提高
表1給出了在不同的數(shù)據(jù)傳輸速率條件下,網(wǎng)絡處理器處理一個40字節(jié)的分組(最小的通信分組)所需要的時間。例如,在數(shù)據(jù)傳輸速率為1G位/秒時,網(wǎng)絡處理器可以有360 ns 的時間來處理此分組。在這段時間內,NPU必須對分組進行檢查,語法分析,以及必要的編輯和查表(有時對于分組的內容需要按照不同的策略采取不同的處理措施,有的繼續(xù)向前傳送,有的要送去排隊,有的需要作標記;一般說來,對于一個分組可能要進行2到3種數(shù)據(jù)庫的查表處理)。對于即使是比較低的傳輸速率1G位/秒,網(wǎng)絡處理器也只有360 ns 來完成上述作業(yè);如果傳輸速率為100G位/秒,對于每個分組就只有3.6 ns 的時間來進行處理了。
從目前情況來看,價格適中的SRAM,存取時間為10 nsec,有望提高到5 nsec。如果將一個10 nsec的SRAM用于1G/秒的數(shù)據(jù)流,在留給處理分組的360 nsec 時間窗口內,只能對存儲器進行36次的存取。如果用于10 G位/秒的數(shù)據(jù)流,存取次數(shù)將減少到只能進行3次了;即使是采用5 nsec的SRAM,也只能進行7次存取。
從表1所給出的數(shù)據(jù)可以看出,為了有效地提高數(shù)據(jù)處理速率,只能將處理步驟分段,并采用流水線的方式來進行處理,或者采用多個處理機來并行處理(即多個處理機同時對不同分組進行處理)。這種解決辦法,對于策略查表存儲器,和內容尋址存儲器(CAM)都適用。例如,對于40 G位/秒的數(shù)據(jù)流,采用10 nsec 的存儲器,在允許的時間內一次存取也進行不了。這時,設計人員必須采用許多并行的存儲器陳列。
網(wǎng)絡處理器可以按照它們對于數(shù)據(jù)處理的速率來進行分類。在表1的中間部分列出了對于一定的數(shù)據(jù)速率,需要采用的網(wǎng)絡處理器種類和數(shù)量。例如,對于2.5 G位/秒的數(shù)據(jù)流,需要使用3個1G位/秒的處理器來進行處理。而對于100 G位/秒的數(shù)據(jù)流,則需要144個這樣的處理器。對于這樣的數(shù)據(jù)流,也許改為采用12個OC-192處理器,或兩個OC-768處理器更合適一些。
表1 對網(wǎng)絡處理器處理速率的要求(以每分組40字節(jié)為例)
| 傳輸速率(G位/秒) | 可以用來處理分組的時間(nsec/分組) | 所需處理器的種類及數(shù)量 | SRAM存取次數(shù)(nsec) | |||||
| 1G位/秒 | OC-48 | OC-192 | OC-768 | 10 | 5 | 2 | ||
| 1 | 360 | 1 | - | - | - | 36 | 72 | 180 |
| 2.5 | 144 | 3 | 1 | - | - | 14 | 28 | 72 |
| 10 | 36 | 12 | 4 | 1 | - | 3 | 7 | 18 |
| 40 | 9 | 48 | 16 | 4 | 1 | 0 | 1 | 4 |
| 100 | 3.6 | 144 | 48 | 12 | 2 | 0 | 0 | 1 |
| 200 | 1.8 | 288 | 96 | 24 | 4 | 0 | 0 | 0 |
除了實際處理分組需要時間以外,將分組從網(wǎng)絡一方轉移進來,和將數(shù)據(jù)轉移到交換結構一方去也去要花費時間。表2給出的分攤時間是總時間的25%。以上數(shù)字對于MAC接口是很符合實際的假設,但是對于交換結構接口,由于分段(segmentation)的效率一般只有50%,因此在計算時需要留下100%的速度余度,才能跟得上通信線路的速度。
表2 對于網(wǎng)絡媒體/交換結構接口的要求
| 媒體訪問控制和交換結構的接口 | ||||||
| 25%的分攤 | 22位 | 64位 | 128位 | |||
| SDR | DDR | SDR | DDR | SDR | DDR | |
| 1G位/秒 | 39MHz | 20MHz | - | - | - | - |
| 2.5位/秒 | 98MHz | 49MHz | 49MHz | 24MHz | - | - |
| 10位/秒 | 391MHz | 195MHz | 195MHz | 98MHz | 98MHz | 49MHz |
| 40位/秒 | 1563MHz | 781MHz | 781MHz | 391MHz | 391MHz | 195MHz |
| 100位/秒 | 3906MHz | 1953MHz | 1953MHz | 977MHz | 977MHz | 488MHz |
| 200位/秒 | 7813MHz | 3906MHz | 3906MHz | 1953MHz | 1953MHz | 977MHz |
從表2可以看出,對于10G位/秒的傳輸速率,如果采用32位單數(shù)據(jù)速率(SDR)總線,則總線必須工作在391MHz。而對于40G位/秒的傳輸速率,假定采用64位SDR總線,總線必須工作在781MHz。表3總結了對分組緩沖存儲器的要求。分組緩沖存儲器至少必須具有3倍用通信線路的速度的傳輸速率(300%的速度余度)。表3中分門別類地給出了這一要求。例如,對于10G位/秒的傳輸速率,如果采用的是64位的雙倍數(shù)據(jù)速率(DDR)緩沖存儲器,則需要工作在313MHz以上的頻率。
表3 對分組緩沖存儲器的要求
| 分組存儲器的界面 | ||||||||
| 300%速度余度 | 32位(MHz) | 64位(MHz) | 128位(MHz) | 512位(MHz) | ||||
| SDR | DDR | SDR | DDR | SDR | DDR | SDR | DDR | |
| 1G位/秒 | 125MHz | 63 | - | - | - | - | - | - |
| 2.5G位/秒 | 313MHz | 156 | 156MHz | 78MHz | - | - | - | - |
| 10位/秒 | 1250MHz | 625 | 625MHz | 313MHz | 313MHz | 156MHz | - | - |
| 40位/秒 | 5000MHz | 2500 | 2500MHz | 1250MHz | 1250MHz | 625MHz | 313MHz | 156MHz |
| 100位/秒 | 12500MHz | 6250 | 6250MHz | 3125MHz | 3125MHz | 1563MHz | 781MHz | 391MHz |
| 200位/秒 | 25000MHz | 12500 | 12500MHz | 6250MHz | 6250MHz | 3125MHz | 1563MHz | 781MHz |
網(wǎng)絡處理單元(NPU)的結構問題
網(wǎng)絡處理器和中央處理單元(CPU)不同。網(wǎng)絡處理器需要對它所需要進行處理自行抽象提取。它必須能夠識別字段(field),分組(packet),和數(shù)據(jù)流(flow)。它必須對于它所需要進行的處理功能,例如:語法分析,編輯,搜尋,和調度等,具有特殊的運算能力。
在程序編制模型方面,網(wǎng)絡處理器和CPU并沒有根本的不同:它也是一個可以儲存程序的微編碼機。但是在數(shù)據(jù)的模型方面則有很大的區(qū)別。NPU處理的是一種恒定的連續(xù)數(shù)據(jù)流(一種數(shù)據(jù)流結構),因此不需要將數(shù)據(jù)從一個大容量存儲器中移進移出。如上所述,網(wǎng)絡處理器為了滿足一定的數(shù)據(jù)速率,絕對地需要并行處理,或流水線(pipelined)結構,或者兩種方式同時都需要采用。
另一個問題是網(wǎng)絡處理器的可編程性能。一個極端是使它具有最大的可編程性,因而使它具有最大的靈活性,也可以在最大程度上適應未來的發(fā)展變化(即使它可以通過新開發(fā)的軟件使系統(tǒng)改變或升級,而不是當要求改變系統(tǒng)時就更新硬件)。這種方式的缺點是,為了完成一項作業(yè)需要執(zhí)行許多個指令,因而可能導致缺乏凈空(headroom)。
另一種折衷方式,稱為“適當程度的可編程性”。這種方式提供一定程度的可編程性以適應變化的需要,或者說使處理器具有一定的靈活性。但是它不能適應完全的重新編程的需要。和RISC型的CPU類似(RISC采用簡約的有效指令集,以提高CPU速度);而NPU則通過提供適當?shù)目删幊绦裕沟孟到y(tǒng)設計人員能夠犧牲某些靈活性,去提高運行速度,換取更多的性能凈空。
對于運行在載體網(wǎng)絡核心的交換機和路由器,速度的要求高于一切。這些在網(wǎng)際間工作的裝置,不需要進行復雜的分組處理功能,只是要求將分組以最大的線速度向前傳送。與此相反,在企業(yè)網(wǎng)的邊沿,線速度明顯地比較低,而交換機對分組的處理能力卻要求相當?shù)母摺@纾瑢τ诙鄥f(xié)議標記交換機,它處于網(wǎng)絡的邊沿,需要對某些數(shù)據(jù)流進行識別并相應地對某些分組予以標記。
交換機的設計人員可以根據(jù)這些不同的要求,以及交換機所處的位置,為預計在企業(yè)網(wǎng)邊沿使用的交換機選擇可以充分編程的NPU。而對于將應用在網(wǎng)絡核心部位的交換機,則應該選擇編程能力有限,但是具有較高速度的NPU。
網(wǎng)絡處理器的實現(xiàn)方式
網(wǎng)絡處理器的實現(xiàn)方式大體上可以分為三種。一種是采用專用的ASIC或FPGA(后者往往功能不夠完整,或者性能不夠理想)。這種方式就是依靠“硬件”的方式,它具有最高的性能,但是靈活性也最差(因為設計決策是熔制在硅的體內)。此外,ASIC的開發(fā)過程比較長,一次性的、不可重復使用的投入的費用也比較高。
另一種方式是將許多個RISC CPU做在一塊芯片上,采用對稱多重處理的運行方式(使用微編碼將通用CPU轉變成為專用的網(wǎng)絡處理器)。這種實現(xiàn)方式,由于NPU的一切行為幾乎都是通過軟件實現(xiàn)的,因此靈活性最高。這種方式所需要的開發(fā)時間比較短,它展現(xiàn)在設計人員面前的形象是設計人員十分熟悉的編程模型。然而,隨著軟件復雜性的增加,這種方式的費用也在增長。由于嚴重地依賴軟件,這種方式實現(xiàn)的系統(tǒng),與采用專用ASIC實現(xiàn)的系統(tǒng)相比性能較差,所消耗的功率也較多。
介乎上述二者之間的一種實現(xiàn)方式是流水線方式,它采用一些具有不同功能的專用處理器,組成“裝配線”型式的數(shù)據(jù)流構造。采用流水線方式實現(xiàn)的系統(tǒng),性能接近用ASIC實現(xiàn)的系統(tǒng),而在編程的靈活性方面又和多處理器實現(xiàn)的系統(tǒng)相差不多。
衡量NPU技術水平的尺度
設計人員十分關心的一個問題是技術水平。衡量技術水平,可以從幾個不同的層次加以分析。
* 在芯片層次,人們關心的問題是:在一個芯片上究竟可以容納多大的處理能力?根據(jù)當前的技術水準,在一個芯片上可以做成10G位/秒的NPU。
* 在線路卡(line-card)層次,問題在于:一張線路卡可以安置多少塊芯片?同樣重要的是:使用一個小型交換結構或一個共用的總線,究竟可以將多少塊芯片放在一個線路卡上,正常地并行運行?現(xiàn)在看來,可以在一張卡上安置足夠的處理能力,使之達到100G位/秒的傳輸要求。
* 在機架或機箱層次,問題在于,一個機架或機箱,通過一個交換結構可以容納多少張線路卡進行信息傳遞?現(xiàn)在看來一個機架實現(xiàn)數(shù)太拉(1012)位的傳輸能力是可能的。
* 在機房層次,問題在于,究竟多大規(guī)模的機架簇群可以連接在一起仍然能夠進行有效的通信?目前在這個層次上,還沒有把握說清楚,但是一些新建的機房已經(jīng)把目標瞄準在數(shù)拍它(1015)帶寬的水平。
評價一個NPU不能只看單個NPU的工作能力,還要看它的互操作性。一個10G位/秒的NPU,并不一定比一個9G位/秒的NPU優(yōu)越。它還決定于互操作性:如果9G位/秒的NPU,能夠十分容易地和其它的NPU連接在一起,實現(xiàn)更強得多的交換能力,那么選用它,不失為明智的選擇。
設計人員如何才能發(fā)揮多處理器的優(yōu)勢?不論是并行結構或者是串行結構,都可以采用;也可以采用混合結構,即串-并排列的結構。重要的問題在于需要考慮:負荷的平衡(注意不使任何一個NPU超載);作業(yè)的劃分;保持分組流的順序不亂;維持服務質量;以及對NPU之間通信業(yè)務量的控制。
衡量NPU性能的指標
如何正確地評估不同的NPU?關鍵的指標之一是:處理分組的速度(即每秒處理多少百萬個分組或稱為Mpps)。另一個指標是:在一定的分組傳遞速率下,處理每個分組時,允許進行的查表次數(shù)(一般每處理一個分組允許進行2次查表)。當然在進行處理時可以利用的存儲器的規(guī)模也是一項重要指標。此外,及時不斷的提高速度也是十分重要的。許多處理策略也需要進行周期性的更新。有些NPU具有能以很高的速度向前傳送的性能,但是更新處理策略,或更改某些參數(shù)時,卻需要耗用數(shù)毫秒,甚至數(shù)秒的時間才能完成。比較理想的NPU,更新策略,更改參數(shù)的時間最好在數(shù)微秒的時間范圍內;這一點對于用在路由頻繁跳變的場合特別重要。
“凈空”也是需要的。凈空可以看作是在保持線傳送速度不降低的情況下,可能增加的處理功能(或可能增加的處理復雜問題的能力);處理復雜問題的能力(即在一個時鐘周期內,用一個指令,包括轉移這樣的控制指令,可以完成多少處理功能)是另一重要的事項。
設計人員應該考慮的其它問題還有:等待時間,排隊和調度的效率,分組存儲(以及分段)的效率,在硅體內多重熔制的效率,芯片的大小,以及這些問題對于總體系統(tǒng)的影響(包括對于消耗功率和成本的影響)等等。
發(fā)展趨勢
隨著設計人員逐漸習慣于使用NPU進行系統(tǒng)設計,幾種時尚可能會流行。下面列出今后幾年將會出現(xiàn)的趨向。
* 今日的系統(tǒng)設計越來越趨向于從眾多的制造商那里采購ASIC和IC。這些芯片中有許多都是各廠商自家獨有的產品,與它們相關聯(lián)的軟件也都是各廠商自行開發(fā)的。它們之間往往缺乏互操作性。預計今后幾年設計人員會越來越對商品化的IC感興趣,并且NPU的發(fā)展毫無疑問將會進一步助長這種傾向的發(fā)展。在硬件方面的發(fā)展趨勢是越來越多地采用現(xiàn)成的商品IC,軟件也在朝這個方向發(fā)展,例如一些專門的協(xié)議棧開發(fā)商正在提供越來越多的商品軟件部件。以這些ASIC和IC,以及商品軟件部件為基礎的增值服務業(yè)務也將會發(fā)展,并且可能成為交換機供應商引以為榮的特點和具有真正競爭力的象征。
* 在市場范圍內,操作系統(tǒng)的供應商將會趨向聯(lián)合和統(tǒng)一,設計人員采用標準操作系統(tǒng)的可能性會越來越大。
* 從長遠看,可能會出現(xiàn)一系列標準的硬件平臺,例如標準的機架,標準的背板等。設計人員可能會從許多廠商中選擇一種線卡,買來插入標準機架。
* 在軟件方面,可能會出現(xiàn)一些標準的軟件集(操作系統(tǒng),協(xié)議軟件棧,管理控制軟件等)。系統(tǒng)設計人員將利用這些即插即用的部件組成系統(tǒng),并且增加一些可以提供不同服務內容的線卡。
如果這些趨向成為現(xiàn)實,標準接口問題將會成為十分重要的課題。例如,為了開發(fā)一種以太網(wǎng)的線卡,設計人員可能會選擇一種物理層(PHY)芯片、MAC芯片、網(wǎng)絡處理器以及并串/串并轉換器等(參看附圖)來進行設計開發(fā)。為了簡化設計業(yè)務,縮短開發(fā)時間,這些芯片必須具有明確清晰的接口,應該使設計人員不需要再花費力氣提供連接的邏輯線路,就可以完成任務。
NPU時代
網(wǎng)絡處理器將成為網(wǎng)絡中各個系統(tǒng)的重要組成部分,但是目前它還不很成熟。它們將在以下幾個方面取得重大進步:在它們能夠處理的分組的復雜程度和所具有的智能方面;在可以下載的程序規(guī)模大小方面;隨著線速度的增加在每個時鐘周期內能夠處理的一個分組或多個分組的綜合能力方面。
NPU 的性能正在按照統(tǒng)一的性能指標穩(wěn)步提高。經(jīng)過一段時間以后,使用網(wǎng)絡處理器來設計開發(fā)通信系統(tǒng)的方法學,估計將會和軟件的開發(fā)一樣,也會出現(xiàn)并取得發(fā)展進步。