
IMA 是ATM反復(fù)用技術(shù),實(shí)現(xiàn)寬窄帶網(wǎng)絡(luò)一體化,在窄帶網(wǎng)絡(luò)接口(如El/T1鏈路接口)上實(shí)現(xiàn)ATM寬帶業(yè)務(wù)。通過IMA協(xié)議接口,實(shí)現(xiàn)將ATM信元流反向復(fù)用到多條低速El/T1鏈路上。IMA是支持高速ATM信元流的一種實(shí)用方法。為多媒體用戶的接入,利用現(xiàn)有鏈路(尤其是2 Mb/s鏈路)進(jìn)行ATM傳輸?shù)葢?yīng)用創(chuàng)造了條件。尤其適用于建網(wǎng)初期的TD—SCDMA接入網(wǎng)Node B側(cè)的數(shù)據(jù)傳輸。
基于計(jì)算機(jī)的數(shù)據(jù)采集系統(tǒng)可以依據(jù)與計(jì)算機(jī)的接口方式不同而分類。對(duì)于低速數(shù)據(jù)的采集,基于ISA總線的系統(tǒng)面臨被USB取代的趨勢(shì)。而對(duì)于高速數(shù)據(jù)采集系統(tǒng),主要還是基于PCI總線傳輸數(shù)據(jù)。PCI總線相對(duì)于其他總線具有高速率、硬件資源豐富和較好的PCI設(shè)備驅(qū)動(dòng)軟件開發(fā)包支持等優(yōu)點(diǎn)。高速數(shù)據(jù)采集系統(tǒng)主要有基于PCI接口芯片和基于PCI數(shù)據(jù)采集卡2種開發(fā)選擇。前者具有采集數(shù)據(jù)靈活、更容易控制等優(yōu)點(diǎn)。但需要設(shè)計(jì)基于選定芯片的數(shù)據(jù)采集卡。同時(shí)由于PCI總線是一個(gè)共享總線,仲裁算法一般是公平競爭,要想穩(wěn)定可靠地采集數(shù)據(jù)流,采集卡上必須有大小合適的緩存,這就涉及到一個(gè)先進(jìn)先出的結(jié)構(gòu),提高整個(gè)系統(tǒng)的復(fù)雜度。后者可以選用符合系統(tǒng)要求的數(shù)據(jù)采集卡,大大縮短項(xiàng)目的研制時(shí)間,設(shè)計(jì)也相對(duì)簡單。主要是對(duì)采集卡進(jìn)行必要的配置以及如何嵌入系統(tǒng)的軟/硬件設(shè)計(jì)的問題。
網(wǎng)絡(luò)處理器MPC8280是PowerPC處理器系列,集成了G2內(nèi)核和通信處理器CPM,可以輕松地處理100 Mb/s以太網(wǎng)、ATM等應(yīng)用。同時(shí)集成了系統(tǒng)PCI接口單元,滿足基于PCI總線數(shù)據(jù)傳輸?shù)拈_發(fā)模式。
1 MPC8280芯片介紹
用于通信領(lǐng)域的PowerPC處理器系列的MPC8280,它是一塊多功能通信處理器,采用雙內(nèi)核的結(jié)構(gòu),即PowerPC內(nèi)核G2和通信處理模塊CPM專用內(nèi)核CP。兩個(gè)內(nèi)核工作在不同的時(shí)鐘頻率。G2內(nèi)核和通用一般處理器功能相似,主要執(zhí)行高層代碼,完成對(duì)于外設(shè)的控制與管理;CP處理器內(nèi)核處理具體底層通信協(xié)議,通信處理模塊CPM部分還包含了各種豐富的通信控制外圍模塊,這些外圍模塊幾乎支持各種常見的底層傳輸協(xié)議,通過靈活設(shè)置這些外圍通信模塊實(shí)現(xiàn)具體應(yīng)用中的協(xié)議。圖1是MPC8280內(nèi)部構(gòu)架圖。

2 系統(tǒng)總體設(shè)計(jì)
2.1 設(shè)計(jì)思想
參考IMA功能單元的參考模型,可以得出IMAE1的數(shù)據(jù)處理功能流程圖,如圖2所示,主要完成物理層、TC子層、IMA子層、ATM層和AAL層的協(xié)議解碼,圖中PMD鏈路接口負(fù)責(zé)接收來自E1鏈路上的ATM信息,經(jīng)過成幀模塊處理后,發(fā)送到IMA協(xié)議處理模塊,還原為標(biāo)準(zhǔn)的ATM信元流,送到進(jìn)行 ATMSAR—PDU處理,提取鏈路信息,發(fā)送到上位機(jī)進(jìn)行分析、處理。
2.2 硬件總體設(shè)計(jì)
選用基于PCI接口芯片的數(shù)據(jù)采集的設(shè)計(jì)方案,采用板級(jí)處理機(jī)的方式,由板級(jí)處理機(jī)完成數(shù)據(jù)的重組和分組,再將組裝好的數(shù)據(jù)上傳,這樣數(shù)據(jù)組裝和數(shù)據(jù)上傳并行工作,能夠有效地減輕PC機(jī)的負(fù)擔(dān),同時(shí)還能實(shí)現(xiàn)硬件層數(shù)據(jù)過濾功能。硬件設(shè)計(jì)如圖3所示。系統(tǒng)由保護(hù)線路接人IMA E1傳輸線路,經(jīng)過E1成幀器轉(zhuǎn)化為PCM E1幀,再將多路IMA E1送入IMA處理器,形成ATM信元流,通過MPC8280進(jìn)行ATM適配,組裝成PDU數(shù)據(jù),再將PDU數(shù)據(jù)通過PCI接口上傳到上位機(jī)進(jìn)行協(xié)議解碼和分析。

3 各個(gè)功能模塊的設(shè)計(jì)
3.1 多PHY的UTOPIA接口設(shè)計(jì)實(shí)現(xiàn)
該系統(tǒng)實(shí)現(xiàn)了IMA E1數(shù)據(jù)的采集和仿真功能,所以需要2個(gè)通道的數(shù)據(jù)傳輸,同時(shí)由于需要MPC8280進(jìn)行處理,所以整個(gè)物理層模塊和MPC8280之間的數(shù)據(jù)交互,和單個(gè)通道時(shí)完全有所不同。UTOPIA接口是ATM網(wǎng)絡(luò)層和物理層之間的標(biāo)準(zhǔn)傳輸接口。它的運(yùn)行模式有單PHY模式以及多PHY模式。單PHY模式即物理層接口只有一個(gè),而多PHY情況下有多個(gè)物理層接口交互,這種情況下面就必須考慮怎么來進(jìn)行接口交互的輪詢選擇問題,下面為MPC8280的UTO~PIA 接口的詳細(xì)信號(hào)描述。
由圖4可以看到,UTOPIA接口傳輸信號(hào)主要由接口時(shí)鐘信號(hào)、數(shù)據(jù)傳輸信號(hào)、信元級(jí)的握手控制信號(hào)以及輪詢地址信號(hào)組成。UTOPIA接口接收和發(fā)送通道的控制信號(hào)是獨(dú)立的,它的工作模式分為主模式和從模式。在該設(shè)計(jì)中需要由MP(28280主動(dòng)來輪詢控制多個(gè)物理層器件的ATM信元的傳輸,所以 MP(28280側(cè)UTOPIA接口工作為主模式。對(duì)于物理層器件來說,在進(jìn)行信元傳輸時(shí),要接收來自MPC8280發(fā)起的各種控制與輪詢,所以物理層側(cè) UTOPIA接口工作為從模式。當(dāng)UTOPIA接口工作在多PHY的情況下,MP(28280 UTC)PIA接口支持2種多PHY的操作模式:

直接輪詢方法 利用CLAV[3~0],以及地址ADD[O,1],總共支持4片物理層器件。每個(gè)物理層器件1個(gè)收發(fā)CLAV,同時(shí)公共使用地址ADD[0,1]。每個(gè)cLAV的操作與單個(gè)時(shí)操作是一樣的。
單CLAV輪詢 利用1個(gè)CLAV以及ADD[4~0],ATM控制器輪詢所有激活的物理層器件,從0X0~FPSMR[LAST_PHY]中寫入地址。所有物理層器件共用1個(gè)收發(fā)CLAV,同時(shí)使用公共地址ADD[0~4]。
3.2 PCI接口設(shè)計(jì)
PCI局部總線在CPU和外部設(shè)備之間插入復(fù)雜的管理層,用此協(xié)調(diào)數(shù)據(jù)傳輸,并提供一致的總線接口,形成了開放的局部總線標(biāo)準(zhǔn),而不依賴于CPU芯片。 PCI總線是與CPU異步工作的,總線上的工作頻率固定為66 MHz。有32位和64位2種數(shù)據(jù)寬度的標(biāo)準(zhǔn),數(shù)據(jù)傳輸率最高分別為132 MB/s和264 MB/s。它能支持多種外設(shè),在高頻率下保持最佳性能。PCI還支持總線控制技術(shù),允許智能設(shè)備在適當(dāng)時(shí)取得總線控制權(quán),以加快數(shù)據(jù)傳輸。在一定意義上可以認(rèn)為PCI局部總線解決了高性能的CPU處理能力和低效的系統(tǒng)結(jié)構(gòu)之間的瓶頸問題。
在該設(shè)計(jì)中,采用專用PCI接口芯片實(shí)現(xiàn)PCI接口,采用的MP(:8280處理器中就集成了PCI接口邏輯功能,所以只需要具體配置處理器內(nèi)部相應(yīng)模塊寄存器實(shí)現(xiàn)其功能。圖5為PCI橋在整個(gè)網(wǎng)絡(luò)處理器內(nèi)部的功能框圖。
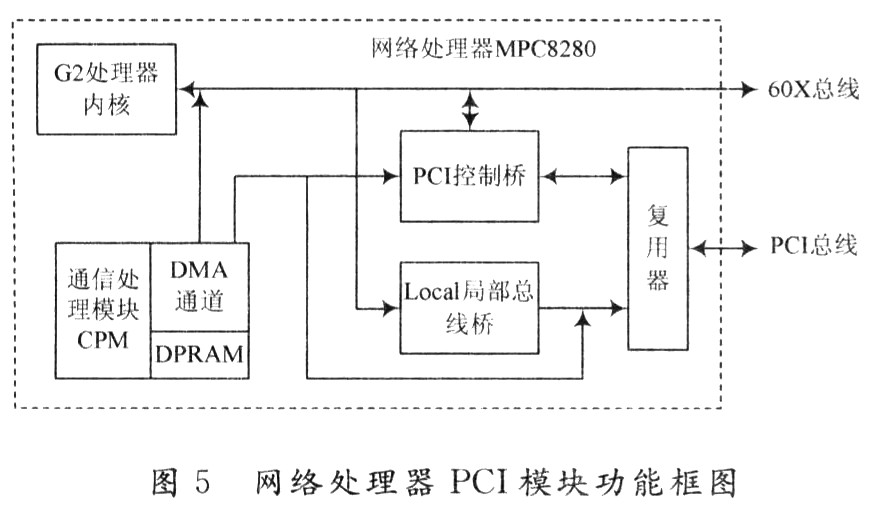
在MPC8280內(nèi)部,PCI橋?qū)ν獾腜CI接口信號(hào)和局部總線的信號(hào)引腳是復(fù)用的,所以在系統(tǒng)啟動(dòng)時(shí),必須通過正確設(shè)置相應(yīng)硬件跳線和硬件復(fù)位配置字.實(shí)現(xiàn)PCI引腳及內(nèi)部功能寄存器配置。PCI橋和通信處理模塊之間有DMA通道,可以在DPRAM與PCI接口之間直接進(jìn)行DMA通道的數(shù)據(jù)傳輸,但是這種情況一般采用極少。通常通信處理模塊CPM的數(shù)據(jù)通過60X總線傳送到外部的存儲(chǔ)器,PCI控制橋直接通過60X總線接口總線和系統(tǒng)內(nèi)存之間進(jìn)行數(shù)據(jù)的交互工作。
PCI接口作為數(shù)據(jù)采集卡系統(tǒng)和上層PC機(jī)軟件之間的交互的接口,其接口驅(qū)動(dòng)程序是由上層PC機(jī)操作系統(tǒng)提供的,所以MPC8280的PCI橋接口實(shí)際上工作在從模式下,PC機(jī)系統(tǒng)軟件對(duì)其進(jìn)行控制。整個(gè)數(shù)據(jù)采集系統(tǒng)的時(shí)鐘,復(fù)位信號(hào)以及電源,都是由PC機(jī)上的PCI接口提供的。
3.3 網(wǎng)絡(luò)處理器總線控制功能設(shè)計(jì)
將任何存儲(chǔ)設(shè)備或I/O設(shè)備接到處理器上,一般都會(huì)通過處理器的系統(tǒng)總線。處理器存儲(chǔ)空間以bank為單位控制。MPC8280是32位處理器,一共有 32條地址線,理論上可以尋址的空間范圍是4 GB,也就是尋址的范圍為Ox00000000~0xFFFFFFFF。每一個(gè)外部設(shè)備,如FLASH,SDRAM等都可以通過控制網(wǎng)絡(luò)處理器的內(nèi)存控制器中的OR和BR寄存器惟一地確定外設(shè)存儲(chǔ)空間對(duì)應(yīng)于4 GB空間的位置,每一組OR和BR寄存器對(duì)應(yīng)1個(gè)外設(shè)存儲(chǔ)(I/0)空間,稱之為1個(gè)bank。為了靈活實(shí)現(xiàn)對(duì)于外部存儲(chǔ)控制體的管理和設(shè)置,存儲(chǔ)控制器包含12個(gè)基地址寄存器(BRx)和12個(gè)選項(xiàng)配置寄存器(0Rx),分別對(duì)于12個(gè)外部存儲(chǔ)體進(jìn)行相應(yīng)具體設(shè)置。
配置選項(xiàng)寄存器OR的內(nèi)容根據(jù)不同存儲(chǔ)體選擇的控制狀態(tài)機(jī)而不同,主要提供一些補(bǔ)充的設(shè)置選項(xiàng),如高位地址掩碼,SDRAM狀態(tài)機(jī)的行列地址選擇,以及 GPCM狀態(tài)機(jī)的插入等待周期等。由上可見,通過配置內(nèi)存控制器中每個(gè)存儲(chǔ)體片選對(duì)應(yīng)的基地址寄存器BR和選項(xiàng)寄存器OR,可以設(shè)置外部存儲(chǔ)體的具體狀態(tài)控制機(jī)以及相應(yīng)的j1二作模式。需要注意的是,存儲(chǔ)控制器的狀態(tài)機(jī)制和存儲(chǔ)體之間沒有確定對(duì)應(yīng)的關(guān)系,每一個(gè)狀態(tài)機(jī)控制機(jī)都可以對(duì)應(yīng)于12個(gè)存儲(chǔ)體的任何一個(gè),多個(gè)存儲(chǔ)體也可以設(shè)置為同一的狀態(tài)控制機(jī)。
當(dāng)系統(tǒng)訪問相應(yīng)的存儲(chǔ)體時(shí),首先比較訪問地址和各個(gè)BR寄存器中BA位設(shè)置的高17位地址,當(dāng)所訪問的地址和某一寄存器中地址相匹配時(shí),表明該訪問的空間位于該存儲(chǔ)體地址空間范圍,此時(shí)系統(tǒng)通過片選信號(hào)片選該存儲(chǔ)體,該存儲(chǔ)體對(duì)應(yīng)的狀態(tài)機(jī)獲得總線訪問外部信號(hào)控制權(quán),系統(tǒng)就可以對(duì)該存儲(chǔ)體進(jìn)行訪問。
4 硬件系統(tǒng)信號(hào)完整性分析
信號(hào)完整性是指信號(hào)線上信號(hào)的質(zhì)量。高速電路的傳輸線效應(yīng)會(huì)導(dǎo)致信號(hào)完整性下降,會(huì)出現(xiàn)數(shù)據(jù)丟失以及判斷出錯(cuò)等問題,因此信號(hào)完整性分析便成為了高速電路設(shè)計(jì)和仿真的關(guān)鍵。在高速電路設(shè)計(jì)中,信號(hào)完整性并不是由單一原因引起的,而是板級(jí)設(shè)計(jì)中多種因素共同作用的結(jié)果。常見的信號(hào)完整性問題包括反射、振鈴、地彈、串?dāng)_等。振鈴和地彈實(shí)際上都屬于信號(hào)完整性問題中的單信號(hào)線現(xiàn)象,而串?dāng)_則是由于電路上兩條信號(hào)線與地平面引起地。
下面通過sDRAM內(nèi)存模塊部分信號(hào)完整性分析為例,描述整個(gè)硬件電路的信號(hào)完整性仿真分析過程。圖6為內(nèi)存模塊電路中的數(shù)據(jù)線信號(hào)DATA0未做任何優(yōu)化措施時(shí)的反射信號(hào)仿真圖。

DATA0是MPC8280 u1直接和內(nèi)存芯片u2相連的數(shù)據(jù)線,由圖6可知,不論是該信號(hào)的驅(qū)動(dòng)端u1—19,還是負(fù)載端U2—12,在該傳輸信號(hào)線上都有嚴(yán)重的反射現(xiàn)象。采用終端匹配措施后信號(hào)分析見圖7。
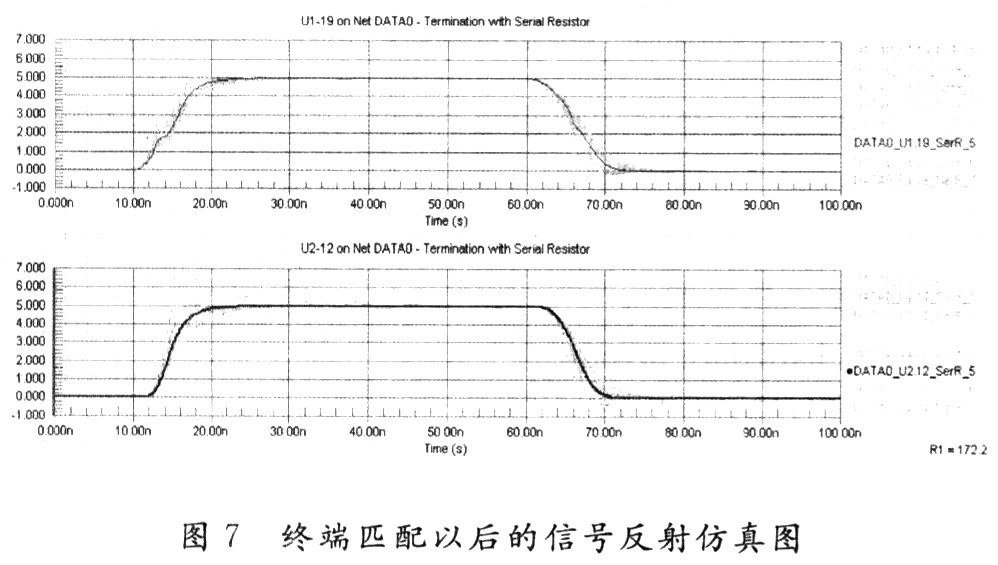
仿真器提供8種終端適配電阻的仿真效果波形,通過比較分析波形可以得出,當(dāng)適配電阻R一172.2 Ω時(shí),此時(shí)信號(hào)的反射達(dá)到最小,信號(hào)完整性最好。采用此電阻對(duì)DATA0信號(hào)連線進(jìn)行終端適配端接以后,信號(hào)的反射明顯減小,尤其是在消除抖動(dòng),低電平方面得到很大改善,從而DATAO信號(hào)完整性得到保證。其他的內(nèi)存訪問各個(gè)信號(hào)的反射分析與優(yōu)化也與這類似。
5 結(jié) 語
ATM 反向復(fù)用通過把多個(gè)物理通信接口(通常為E1接口)綁定為一個(gè)邏輯接口,從而突破單個(gè)物理接口的速率限制,根據(jù)實(shí)際需要配置接口速率,以獲得業(yè)務(wù)所需要的接口帶寬。在此設(shè)計(jì)了針對(duì)IMA E1傳輸?shù)臄?shù)據(jù)采集系統(tǒng),重點(diǎn)介紹基于MPC8280的數(shù)據(jù)采集系統(tǒng)硬件設(shè)計(jì)過程。該系統(tǒng)最后通過與軟件聯(lián)調(diào),能夠?qū)崿F(xiàn)多幀AAL2和AAL5數(shù)據(jù)的發(fā)送和接收,達(dá)到了IMA E1數(shù)據(jù)采集的目的。