
摘 要: Scribe提供了一種有效的算法可以較小的計算量查找到最佳節(jié)點。然而,該算法在查找的過程中,需要不斷地進行網絡臨近性測量來比較、判斷、查找最佳節(jié)點,耽誤時間。特別是在中國電信和中國網通" title="網通">網通互聯(lián)互通問題比較嚴重的網絡環(huán)境下,情況會進一步惡化。為了更快地查找到最佳節(jié)點,減少最終用戶的等待時間" title="等待時間">等待時間,解決應用層組播" title="組播">組播技術在中國應用的具體問題,充分利用了Scribe節(jié)點運行過程中的歷史數(shù)據(jù)和已知的IP地址數(shù)據(jù)庫,優(yōu)化了Scribe最佳節(jié)點查找算法。模擬實驗顯示,該算法將最佳節(jié)點查找速度提高了5%左右。
關鍵詞: 對等網絡(P2P); 應用層組播" title="應用層組播">應用層組播; 終端系統(tǒng)組播(Scribe); 流媒體
?
最近幾年,流媒體直播越來越受到廣泛的關注。IP組播是支持流媒體直播的最有效技術。然而,相關技術研究雖然經歷了十多年的發(fā)展,并未能得到廣泛應用。于是近年來不少學者提出了應用層組播技術。
應用層組播系統(tǒng)大多是建立在P2P技術基礎上的。目前P2P最流行的算法就是DHT算法。但在大多數(shù)DHT算法中,節(jié)點標識符是隨機選擇的,而鄰居關系只是基于這些標識符來建立。如何合理地將節(jié)點的地理位置考慮進去,優(yōu)化DHT算法,使該算法在保留原有優(yōu)點的基礎上更快地找到最佳節(jié)點,對于應用層組播的推廣應用有著非常重要的理論意義。在2005年,中國利用應用層組播技術建立的商業(yè)公司如雨后春筍般地涌現(xiàn)出來,如UUSEE、PPLIVE、PPSTREAM等,但都面臨著中國電信與中國網通網絡互聯(lián)互通問題。如何優(yōu)化DHT算法,對于在中國互聯(lián)網上提供應用層組播服務也有著更積極的現(xiàn)實意義。
Scribe是在Pastry基礎上開發(fā)的一個可擴展的應用層組播體系結構。Scribe充分利用了Pastry的可靠性、自組織性和網絡位置屬性。本文在Scribe最佳節(jié)點選擇算法的基礎上,充分利用了Scribe節(jié)點歷史數(shù)據(jù)和已知的IP地址庫,有效地提高了Scribe查找最佳節(jié)點的速度。
1 算法設計
1.1 最佳節(jié)點的定義
應用層組播算法的一個特點是:它的設計是針對某種應用進行優(yōu)化,所以哪一個點是新加入組播樹的節(jié)點的最佳節(jié)點并沒有準確地定義。本文根據(jù)自身的理解和實際工作的經驗,從實際應用的角度做了如下定義:
(1)距離新加入節(jié)點延時最小的節(jié)點
應用層組播的首要任務是要給用戶提供穩(wěn)定的、高質量的音視頻流。與組播節(jié)點延時最小的上層節(jié)點,通常都是網絡位置較近的、網絡環(huán)境相對比較穩(wěn)定的點。所以,延時最小應該是最佳節(jié)點的第一判斷標準。
(2)距離組播樹的根路徑最短的節(jié)點
由于應用層組播多用于音視頻直播,組播樹最底層的節(jié)點與根節(jié)點之間的延時是需要考慮的問題。如果直播內容的延時過大,對于用戶體驗來說就相對較差,特別是對一些體育比賽的直播。因此,把距離組播樹的根路徑最短列為最佳節(jié)點第二重要的判斷標準。
(3)處理能力空余多的點
為了整個系統(tǒng)的穩(wěn)定性以及避免過熱點的存在,應用層組播應該盡量控制節(jié)點的度,防止組播樹的某些點過熱。節(jié)點的空余處理能力是選擇最佳節(jié)點的第三標準。
通常情況下,最佳節(jié)點的選擇,要根據(jù)三個條件統(tǒng)一考慮。本文只限于討論第一個標準:在一個新節(jié)點加入組播樹時,花費多長時間才能找到相對它的最佳節(jié)點(延時最小的節(jié)點),如何縮短這個時間以減少用戶的等待時間。
1.2 Scribe節(jié)點加入機制
Scribe是在Pastry基礎上開發(fā)的一個可擴展的應用層組播體系結構。Pastry是目前業(yè)界比較活躍的開放的P2P研究項目,2007年2月剛剛發(fā)布了2.0的版本。Pastry也是業(yè)界考慮節(jié)點網絡位置的DHT算法中的一個。
Scribe使用Pastry來管理組的創(chuàng)建、組的加入和基于每個組的組播樹的建立。Pastry和Scribe是全分布式的:所有的決定都基于本地信息;每個節(jié)點都有同樣的能力;每個節(jié)點都可以是組播源、組播樹的根、組成員、組播樹上的一個節(jié)點或者是上述任何角色的混合。Scribe給應用層提供了簡單的API接口。Scribe的完整表述和評估見參考文獻[1]。
Scribe建立一個組播樹,并以匯合點(rendez-vous)為根,向組內成員發(fā)送信息。組播樹是以類似逆向路徑轉發(fā)方案建立起來的,是由組成員到匯合點的路由組成的。組的加入操作是以一種分布式的方法進行的,可以支持大型的、動態(tài)的成員關系。
組播樹中的Scribe節(jié)點被稱作該組的轉發(fā)器(forwarders),它們可能是也可能不是組的成員。每一個轉發(fā)器都有一個子表,它包含該點在組播樹中所有的孩子節(jié)點(包括IP地址和nodeId)。
當一個Scribe節(jié)點要加入一個組時,它要求Pastry路由一條以groupId為關鍵字的JOIN信息。這條信息被轉送到組的匯合點。在這條路由的每個節(jié)點上,Pastry檢查自己的所屬組列表,看是否已經是該組的forwarder。如果這個節(jié)點還不是該組的forwarder,它就創(chuàng)建一個組的入口,并把源點加到與該組相關的子表中。然后,它通過沿著加入節(jié)點到匯合點的路由的下一個點發(fā)送一條JOIN消息成為該組的forwarder。如果是,它就接收這個點作為自己的孩子,并把它加到自己的子表中。原來從源節(jié)點發(fā)出的信息則被終止。
圖1為Scribe的組加入機制。圓圈代表節(jié)點,有一些節(jié)點顯示了nodeId。為簡單起見,設pastry的配置參數(shù)b=1,所以每次前綴只匹配1個bit。假設有一個groupId為1100的組,它的匯合點的nodeId和groupId相同,nodeId是0111的節(jié)點正在加入這個組。在這個例子中,Pastry路由一個JOIN消息到node1001;然后這個消息又從1001路由到1101;最后,從1101來的消息到達1100。這個路由在圖1中用實線表示。
?

假設節(jié)點1001和1101還不是group1100的轉發(fā)器。那么節(jié)點0111的加入將使得這個路由上的兩個節(jié)點成為該組的forwarder,并且把該點加入到它們的子表中。假設節(jié)點0100決定加入這個組,JOIN消息的路由在圖1中以點實線箭頭表示。由于1001點已經是一個轉發(fā)器,它把0100節(jié)點加到自己的子表中,JOIN消息就被中斷了。
1.3 尋找最佳節(jié)點
從上面Scribe的節(jié)點加入機制可以看出,Scribe最佳節(jié)點的選擇主要決定于Pastry將其JOIN消息路由到的第一個節(jié)點。而這一個點的選擇是依靠Pastry的路由表" title="路由表">路由表決定的。所以,為Scribe尋找最佳節(jié)點的工作,其實就是在Pastry節(jié)點加入Pastry網絡時對節(jié)點路由表和葉子節(jié)點集合進行的初始化上。
在Pastry中,一個新節(jié)點X若加入Pastry網絡,必須知道一個在網絡上相近的節(jié)點A.X向A發(fā)出一個關鍵字為自己的路由請求,這條信息將會一直轉發(fā)到在nodeId空間里離X最近的節(jié)點。X將接收路由過程中所有節(jié)點的路由表,經過整理后得到自己的路由表和葉子節(jié)點集合。
而一個新加入的點如何發(fā)現(xiàn)網絡上相近的Pastry節(jié)點,一種方法是使用一種叫“expanding ring”的IP組播方式,但這需要網絡支持組播。Pastry使用了一種有效的算法,它可以通過位于任何位置的Pastry節(jié)點找到離自己最近的節(jié)點。圖2的流程圖表示了Pastry的最佳節(jié)點發(fā)現(xiàn)算法。這個算法使用了這樣一個屬性:種子(seed)節(jié)點的葉子節(jié)點集合的位置應該在網絡上均勻地分布。在葉子節(jié)點中找到較近節(jié)點后,路由表的距離屬性被用來成指數(shù)倍地減少靠近新加入的節(jié)點。這是通過在路由表中反復遞歸查找最近點實現(xiàn)的。Pastry最近節(jié)點查找方法的詳細說明可參見參考文獻[2]。
?
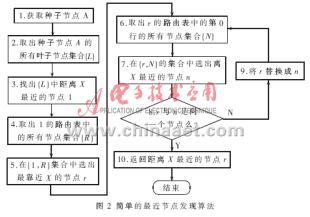
從Pastry的節(jié)點加入算法可以看出,Pastry保留了網絡鄰近性不變。然而,在比較最近節(jié)點時是需要進行實際測量的,因此需要較長的等待時間。下面,將介紹如何縮短等待時間。
1.4 優(yōu)化算法
1.4.1 歷史數(shù)據(jù)
任何一個Pastry節(jié)點在加入Pastry網絡之前,對Pastry網絡的狀況都是一無所知的。但在加入這個網絡并平穩(wěn)運行一段時間之后,它會了解到對于它自己而言,相對穩(wěn)定且臨近的Pastry節(jié)點和Scribe上層節(jié)點。因此在它退出之后,再重新加入這個組播組時,這些歷史信息對它本身而言還是相對有效的。但由于組成員是動態(tài)的,原來網絡連接質量好的節(jié)點,可能已經離開了組播組。如果它仍然在組播組中,將會極大提高該節(jié)點尋找到最佳節(jié)點的速度。
Pastry使用定時(每20分鐘)運行的路由表管理任務來保證路由表中的每一入口都是nodeId滿足條件的節(jié)點當中的最靠近自己的節(jié)點。當發(fā)現(xiàn)比當前節(jié)點更靠近自己的節(jié)點時,Pastry替換成更近的節(jié)點,并把原節(jié)點保留在一個備份列表中,以便當最近節(jié)點失效時,可以馬上替換回來。Pastry為每個入口最多保留10個備份節(jié)點,這些歷史數(shù)據(jù)對于該節(jié)點是非常寶貴的,但是Pastry和Scribe只把這些數(shù)據(jù)保存在內存中,節(jié)點退出之后,這些數(shù)據(jù)就被釋放掉了。而本算法則將這些數(shù)據(jù)定期保存到硬盤上,這樣當該節(jié)點再次進入Pastry網絡時,可以充分利用這些歷史數(shù)據(jù)。
在后面的測試數(shù)據(jù)中可以看出,在組播組的人數(shù)達到一定規(guī)模的穩(wěn)態(tài)時,該算法能夠有效提高最佳節(jié)點查找的速度。但是這個算法對于第一次加入的節(jié)點沒有任何作用。
1.4.2 IP地址庫
在我國,由于眾所周知的原因,中國電信和中國網通兩大電信運營商之間的網絡互聯(lián)非常差。而Pastry中nodeId的生成是不考慮實際網絡位置的。在nodeId空間中,相鄰兩點在網絡位置上相距很遠的可能性非常大。也就是說,nodeId相鄰的兩個點很可能一個在網通,一個在電信。如果在這種條件下,仍然采用1.2節(jié)中的算法尋找最佳節(jié)點,就會耽誤很多時間。
經過多年的測試和搜集,已經有人成功地搜集完中國電信、中國網通以及其他中國主要ISP的IP地址網段。如果在使用圖2的尋找方案中,充分利用該IP地址庫,則可以有效降低等待網絡探測的時間,加快最佳節(jié)點的尋找速度。這一算法對提高新節(jié)點第一次加入組播組的速度會有一些幫助。但是,這個算法只對中國或互聯(lián)網狀況類似中國的網絡才適用。
1.4.3? 算法的實現(xiàn)
實現(xiàn)過程:
? (1)在Scribe節(jié)點正常運行中,定期地將節(jié)點的路由表、葉子節(jié)點集合、Ping包延時表等相關數(shù)據(jù)保存到硬盤上。當節(jié)點退出后再進入時,首先載入這些歷史數(shù)據(jù)和IP地址數(shù)據(jù)庫,然后按照圖3的流程進行處理。
(2)圖3顯示了根據(jù)優(yōu)化算法對Pastry節(jié)點加入網絡初始化時的流程圖。
?
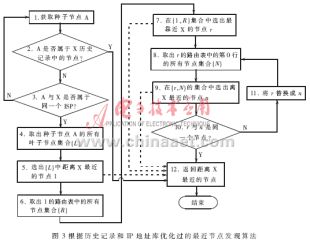
圖3與圖2比較可以發(fā)現(xiàn),第2、3、5、7、9步為修改的地方。第2步,如果種子節(jié)點原來就在本機保存的最佳節(jié)點紀錄中,直接返回最佳節(jié)點。第3步,如果種子節(jié)點的IP地址和本機不屬于同一個電信運營商,重新抓取另一個種子(系統(tǒng)通常會提供多個種子),但不屬于同一個ISP的兩點在網絡上相鄰的可能性很小。第5、7、9步,在從某個集合中挑選最近節(jié)點時,都使用類似第2、3步的判斷方法:首先查看該點是否是本機保存的最佳節(jié)點,如果是,就直接跳到第12步,結束搜索過程。如果不是,則比較該點IP地址是否和本機屬于同一個ISP,如果不是,則跳過測試比較的步驟,節(jié)省搜索時間;如果是,則仍按照以前的步驟,進行測試比較。下面的實驗表明,該算法可以有效提高Scribe最佳節(jié)點的選擇速度。
2 性能分析和測試
2.1 試驗環(huán)境和機制介紹
Pastry提供的網絡模擬器是基于包級別的、離散的網絡模擬器。這個模擬器可以模擬物理鏈路上的傳播延時,最多可以模擬10萬個節(jié)點,但是不能模擬排隊延時、包丟失。
實驗使用Pastry的配置為b=4, 葉子節(jié)點集合大小l=16。利用Pastry/Scribe提供的API及例子程序開發(fā)一個小程序。該程序設定所有的Pastry節(jié)點都運行Scribe,不運行其他的P2P應用。每個Scribe節(jié)點都加入同一個組播組,第一個節(jié)點既當信息發(fā)布源,又當組播樹的根。其他的節(jié)點一旦加入Pastry就立刻加入組播組,并開始接收數(shù)據(jù)。把N個節(jié)點一個一個地加入,計算每個節(jié)點從加入開始到正常接收Scribe數(shù)據(jù)的時間,然后計算平均值。在不同的N值分別測試10次,以利用程序保存下來的歷史數(shù)據(jù)。把模擬試驗所使用的N×N的延時矩陣文件,人為分為兩個部分,分別模擬兩大運營商。并在程序中給出類似IP地址的區(qū)分判斷。由于試驗設備的限制,本次試驗的N的最大值為4 000。
以Pastry提供的網絡模擬器測試經過優(yōu)化過的Scribe程序。作為比較,把沒有經過優(yōu)化的Scribe程序也在相同的模擬器上運行。由于模擬器本身對時間參數(shù)作了優(yōu)化,因此,時間的絕對值可能沒有什么參考價值,但優(yōu)化程序的加速比率卻有一定的參考意義。
2.2 試驗數(shù)據(jù)和結論
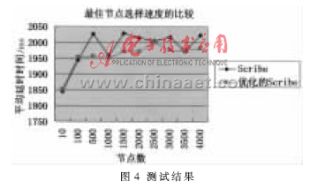
測試的結果如圖4所示。從圖中可以看出,隨著節(jié)點數(shù)的增加,節(jié)點選擇最佳節(jié)點的時間也在增加。這主要是由于節(jié)點多時,節(jié)點加入需要交換的信息也越來越多所致。從兩種算法的比較可以看出,優(yōu)化的算法在節(jié)點數(shù)少時,沒有任何優(yōu)勢。這主要是因為節(jié)點少,需要進行測試的時間也比較少,加速優(yōu)勢體現(xiàn)不明顯。隨著節(jié)點的增多,可以看出,經過優(yōu)化的算法要比原算法有優(yōu)勢。原算法的最佳節(jié)點的平均尋找時間起伏比較大,而優(yōu)化的算法則相對比較穩(wěn)定。新算法的節(jié)點加入速度大約是原算法的95%左右。
?
本文介紹了利用歷史數(shù)據(jù)和IP地址庫提高Scribe最佳節(jié)點查找速度的一種算法。模擬實驗顯示,該算法對于中國的互聯(lián)網現(xiàn)狀還是有一定效果的。下一步的工作,應當充分考慮最佳節(jié)點的其他標準,統(tǒng)一優(yōu)化查找速度。事實上,該算法不僅可以用來提高Scribe最佳節(jié)點的查找速度,也同樣適用于所有結構化P2P網絡上的應用層組播系統(tǒng)。
參考文獻
[1] ?CASTRO M, DRUSCHEL P, KERMARREC A M, et al.?SCRIBE: a large-scale and decentralized application-level ?multicast infrastructure. IEEE Journal of Selected Areas in?Communications, 2002,20(8).
[2] ?CASTRO M, DRUSCHEL P, HU Y C, et al. Exploiting?network proximity in peer-to-peer overlay networks. BertinoroItaly: International Workshop on Future Directions in?Distributed Computing(FuDiCo), 2002.