
1 引言
如今,隨著集成電路工藝發(fā)展到深亞微米的階段,處理器體系結(jié)構(gòu)的設(shè)計研究正朝著多 核的方向發(fā)展。Intel、IBM、SUN 等主流芯片產(chǎn)商已經(jīng)在市場上發(fā)布了自己的多核處理器。 目前多核處理器的發(fā)展尚處于起步階段,有很多問題還有待解決。其中,一個十分重要的方 面就是設(shè)計高效的片上通信架構(gòu)[1]。多個內(nèi)核上同時執(zhí)行的各個程序之間可能需要進(jìn)行數(shù)據(jù) 共享與同步,因此多核處理器的硬件結(jié)構(gòu)必須支持各個CPU 內(nèi)核之間的通信。一般說來, 異構(gòu)多核處理器和同構(gòu)多核處理器在通信機(jī)制的設(shè)計上有著不同的考慮。異構(gòu)多核處理器通 常是針對嵌入式系統(tǒng)的應(yīng)用,主要存在著總線、存儲控制器、共享存儲區(qū)等通信機(jī)制。
異構(gòu)多核處理器系統(tǒng)的幾種主要通信機(jī)制,事實上都可以通過一個共享存儲區(qū)來實現(xiàn) [2],例如郵箱、消息、信號量實際上都是以共享存儲區(qū)作為傳播載體。同時,也考慮到 SystemC 的設(shè)計方法可以支持設(shè)計者在不同層次上建模減小了代碼量和工作量,提供了更高的工作效 率。因此本文在采用共享存儲器通信機(jī)制[3]的同時,基于SystemC 提出且建立事務(wù)級多核通 信模型,并利用MP3 解碼程序?qū)嵗C明了本模型有效的實現(xiàn)了多核間的通信。
2 SystemC 通信總線模型
2.1 SystemC 簡介
SystemC 由C++衍生而來,在C++基礎(chǔ)上添加硬件擴(kuò)展庫和仿真庫構(gòu)成,從而使SystemC 可以建模不同抽象級別的包括軟件和硬件的復(fù)雜電子系統(tǒng)[4]。他的最基本的結(jié)構(gòu)單元是模塊 (module),模塊可以包含其他模塊或過程(process)和方法(method),過程如同C 語言中的函 數(shù)用以實現(xiàn)某一行為模塊,通過接口(port) 與其他模塊通信接口之間用信號(Signal) 相連。 一個完整的系統(tǒng)由多個模塊組成,每個模塊包含一個或多個過程和方法,過程是平行工作的。 基于SystemC 的設(shè)計方法支持設(shè)計者在不同層次上建模減小了代碼量和工作量提供了更高 的工作效率,也就是說利用SystemC 與傳統(tǒng)的方法相比可以更為高效快速地進(jìn)行仿真。
2.2 模塊細(xì)化及基于SystemC 的通信總線行為級建模
一個典型的片上系統(tǒng)模型框架通常包括總線、總線仲裁器、微處理器、數(shù)字信號處理器 (L6P)、存儲器和其他專用集成電路(ASIC)。這樣一個復(fù)雜的系統(tǒng),傳統(tǒng)的設(shè)計辦法是全部 使用C/C++進(jìn)行描述以進(jìn)行系統(tǒng)級建模和驗證,然后將硬件部分的描述手工翻譯為 VHDL/Verilog HDL,等硬件描述語言進(jìn)行描述.等硬件全部實現(xiàn)后再進(jìn)行軟件的設(shè)計與實現(xiàn)。在引入SystemC 作為建模語言的情況下,整個系統(tǒng)可以方便地用一種語言進(jìn)行描述、 建模、仿真、細(xì)化,直到最終實現(xiàn)。
在使用 SystemC 建立片上總線行為級模型時,根據(jù)總線一般模型中各個模塊的行為特 性,進(jìn)行了進(jìn)一步的模型細(xì)化,得出片上總線行為級模型的SystemC 模塊結(jié)構(gòu)圖,如圖1 所示。在模型細(xì)化的過程中,總線主設(shè)備被劃分為直接型主設(shè)備、阻塞型主設(shè)備和非阻塞型 主設(shè)備;總線從設(shè)備被劃分為快速存儲器、慢速存儲器和代表ASIC 的通用串口;通信總線和 仲裁器模塊保持不變。
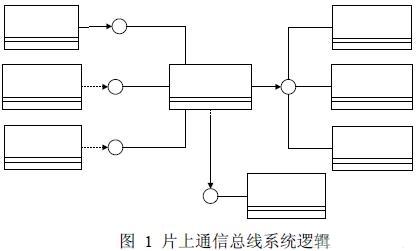
總線采用分層通道的方式實現(xiàn),實現(xiàn)了直接型接口、阻塞型接口和從設(shè)備接口。在某些 時鐘的上升沿,總線收集到來自各個主設(shè)備的從設(shè)備讀寫請求,并將這些請求加入請求隊列。 在時鐘的下降沿,總線將請求發(fā)送給總線仲裁器,由總線仲裁器根據(jù)一定的仲裁規(guī)則進(jìn)行仲 裁,從請求隊列中選擇出合適的主設(shè)備請求并通過從設(shè)備接*由總線從設(shè)備進(jìn)行服務(wù)。
3 基于異構(gòu)多核的通信模塊設(shè)計與實現(xiàn)
3.1 設(shè)計原理
按照上文中提到的總線架構(gòu),多核處理器作為通信總線的主設(shè)備而共享存儲區(qū)作為總線 的從設(shè)備形成了整個系統(tǒng)模型,但考慮到異構(gòu)多核與同構(gòu)多核相比存在一個問題:即由于不 同內(nèi)核的應(yīng)用程序采用的是不同的交叉編譯器,因此高級語言所指定的內(nèi)存空間是無法做到 一致的,即便是直接寫匯編程序指定內(nèi)存地址,由于操作系統(tǒng)分配給不同模擬器的程序空間 是不同的,也無法做到共享存儲。也就是說,無論是高級語言編程,還是匯編語言編程,都 要解決二進(jìn)制代碼和內(nèi)核模擬器之間的通信。因此上文中提到的基于SystemC 的通信總線 就需要針對不同的異構(gòu)多核組合進(jìn)行相應(yīng)的修改,缺少通用性,違反了模塊設(shè)計封裝化原則。
經(jīng)過不斷的探索和比較,本文最終采用了一種從方法學(xué)角度和可擴(kuò)展性角度來看,都比 較合適的方法: 在各個處理器與通信總線之間添加一個通信控制模塊(CMCCtrl-- Communication control)如圖2 所示。

該模塊用來專門處理各個核之間的通信指令,對其進(jìn)行解釋翻譯,并將最終行為直觀的 告訴總線,達(dá)到核間通信的目的。新架構(gòu)設(shè)計按照SystemC 交易級建模(TLM)原則,為以后 多核功能的擴(kuò)展性提供可能性。
3.2 通信機(jī)制
為了異構(gòu)多核通信的實現(xiàn),需要向多核仿真器的每個模擬器內(nèi)核擴(kuò)展三條訪問共享存儲 區(qū)的指令,分別是:申請空間、讀取和寫入。
在內(nèi)核代碼中對共享存儲區(qū)訪問指令進(jìn)行譯碼之后,需要對共享存儲區(qū)發(fā)出操作請求, 與操作請求一起發(fā)送的是操作的信息,對于申請、讀取和寫入三種操作,各自的操作信息如 下表所示:

當(dāng) CMCCtrl 受到接收到來自Core1/Core2 的訪問請求,模塊觸發(fā)。同時隨著請求一起接 收下來的其他信息,包括指令編碼、請求的數(shù)據(jù)類型、地址偏移等等。CMCCtrl 對這些請求 信息進(jìn)行分析,當(dāng)判斷出核間需要數(shù)據(jù)通信后,將需要的信息提取發(fā)送至總線模塊。具體模 塊描述如下:
SC_MODULE(CMCCtrl)
{ sc_inout isCore1, isCore2; //來自Core1/Core2 的訪問請求,是本模塊的觸發(fā)信號
sc_out core1_latency, core2_latency; //返回給Core1/Core2 的延時信息
sc_inout data_value; //需要傳遞的數(shù)據(jù)
sc_port bus_port; //通信總線模塊接口
/*返回給Core1/Core2 的應(yīng)答信號,表明CORE1/Core2 獲得了共享存儲區(qū)的訪問權(quán),并
且可以繼續(xù)執(zhí)行下一個周期的操作*/
sc_inout ackCore1, ackCore2;
/*隨著isCore1/isCore2 請求一起接收下來的請求信息,包括指令編碼、請求的數(shù)據(jù)類型、
地址移等等*/
sc_inout data_type, array_capacity, data_index, data_id;
/*隨著is Core1/isCore2 請求一起接收下來的,表明當(dāng)前Core1/Core2 運行的周期數(shù),用
于進(jìn)行內(nèi)核調(diào)度判斷和訪存沖突分析*/
sc_in core1_cycle, core2_cycle;
/*對isCore1 或者isCore2 的上升沿敏感的響應(yīng)函數(shù),它被定義為線程類型,是CMCCtrl
類的實現(xiàn)函數(shù)。函數(shù)內(nèi)部需要對兩個內(nèi)核的訪問請求進(jìn)行判斷、控制,并調(diào)用相應(yīng)的其
它成員函數(shù)。*/
void Controller();
//對于每一個write_shm_data 請求,將數(shù)據(jù)寫入指定的共享存儲區(qū)空間
void WriteShmDataHandler(struct InstBuffer *inst);
//對于每一個read_shm_data 請求,將數(shù)據(jù)寫入指定的共享存儲區(qū)空間
void ReadShmDataHandler(struct InstBuffer *inst);
……
SC_HAS_PROCESS(CMCCtrl);
// constructor
CMCCtrl (sc_module_name _name){……}
};
4 MP3 解碼程序的多核測試
為了更加充分進(jìn)行驗證,并展示多核通信模塊在實際應(yīng)用中的價值,本文選擇了MP3 解碼程序進(jìn)行基于多核系統(tǒng)的移植,并驗證仿真結(jié)果以及仿真效率。
MP3編碼的主要方法是在頻域上對音頻文件內(nèi)容進(jìn)行編碼壓縮,而解碼過程是還原頻域 的內(nèi)容再變換成原始的時域音頻信號。按照ISO/IEC11172-3標(biāo)準(zhǔn),MP3解碼算法分為同步與 校驗、Huffman解碼、比例因子解析、反量化、重排序、立體聲處理等十個部分。
在考慮應(yīng)用程序的多核移植時,可以是數(shù)據(jù)劃分也可以是任務(wù)劃分的。對于MP3代碼, 如果采用數(shù)據(jù)劃分式,則可以在不同的處理器內(nèi)核上解不同的數(shù)據(jù)幀。而如果采用任務(wù)劃分 方式,則可以將解碼的不同過程在多個內(nèi)核之間形成流水作業(yè),采用共享存儲區(qū)進(jìn)行不同流 水級之間的數(shù)據(jù)傳遞。顯然后者需要更多的核間通信,更適合于驗證其性能,因此,本文采 用了按照任務(wù)劃分的方式進(jìn)行代碼的多核移植。
在測試中,我們采用ARM+PISA的雙核系統(tǒng),因此需要將MP3解碼程序按照功能劃分為 兩部分,分別放在兩個內(nèi)核上運行,形成流水線。本文所采用的MP3解碼軟件在ARM開發(fā) 套件(ARM Design Suit)軟件仿真平臺上測試的結(jié)果表明:合成多項濾波器部分占用了大 約50%的計算量[4]。根據(jù)這個結(jié)論,本文粗略地對應(yīng)用程序在雙核之間進(jìn)行任務(wù)劃分:其中 一個內(nèi)核運行計算量最大的合成濾波,另外一個內(nèi)核實現(xiàn)Huffman解碼、比例因子解析、反 量化等步驟。兩個內(nèi)核通過系統(tǒng)提供的通信控制模塊進(jìn)行通信并保持同步。

表2是這一測試的統(tǒng)計結(jié)果。統(tǒng)計數(shù)據(jù)提供了兩方面的信息:
1)MP3解碼程序的雙核加速比,由統(tǒng)計結(jié)果中的“運行周期數(shù)”反映;
2)多核仿真器在進(jìn)行MP3解碼仿真時的仿真效率,由“仿真時間”和“仿真速度”兩 項統(tǒng)計結(jié)果反映。
5 總結(jié)
無論考慮單位計算性能的能耗因素,還是對于提高處理器性能,多核體系結(jié)構(gòu)尤其是異 構(gòu)多核體系結(jié)構(gòu)都是當(dāng)前的熱點研究方向。本文主要論述了面向異構(gòu)多核處理器的片上通信 設(shè)計。對于處理器的內(nèi)核間通信,采用了共享內(nèi)存技術(shù)。
本模型充分體現(xiàn)了SystemC的語言優(yōu)勢,對進(jìn)一步了解和探討異構(gòu)多核處理器結(jié)構(gòu)、核 間通信、異構(gòu)多核低功耗設(shè)計等方面打下一定基礎(chǔ)。
本文作者創(chuàng)新點: 提出了一種基于SystemC的異構(gòu)多核通信架構(gòu)模型,并通過添加控制 模塊解決異構(gòu)多核間通信通用性問題。