
摘? 要: 目前,C語言和匯編語言" title="匯編語言">匯編語言的混合編程" title="混合編程">混合編程已經(jīng)在TI公司的TMS320C62X上成為一種最流行的編程方法。闡述了基于TMS320C62X的C語言和匯編語言混合編程應(yīng)遵循的接口規(guī)范以及并行匯編代碼" title="匯編代碼">匯編代碼的編寫。給出了一個基于TMS320C62X的運動補償?shù)幕旌暇幊淘O(shè)計實例。
關(guān)鍵詞: DSP? C語言? 并行匯編? 混合編程
?
TMS320C62X是美國德州儀器公司(TI)的新一代高性能定點數(shù)字信號處理器(DSP)芯片。基于DSP的軟件設(shè)計問題,就是采用編程語言進行算法實現(xiàn)并使程序效率盡量滿足實時性要求。TI DSP的軟件設(shè)計可以采用匯編語言、高級語言(C/C++)以及C語言與匯編語言的混合編程。完全采用匯編語言編程復(fù)雜性高、開發(fā)周期長,而完全采用C語言編程則程序的執(zhí)行效率相對較低,不能滿足實時性的要求。為了設(shè)計出性價比最好、開發(fā)周期較短、比較復(fù)雜的DSP系統(tǒng),可以采用混合語言編程,把C語言和匯編語言的優(yōu)點有效地結(jié)合起來。C語言和匯編語言的混合編程有三種形式:在編寫C語言代碼中插入?yún)R編語句,只需在匯編語句兩邊加上雙引號和括號,在括號前面加上標(biāo)識asm,如asm(“匯編語句”);在編寫C代碼的過程中調(diào)用內(nèi)聯(lián)函數(shù),TMS320C62X中有一些直接映射為內(nèi)聯(lián)的C6000指令的特殊函數(shù),內(nèi)聯(lián)函數(shù)用前下劃線(_)表示,使用時同調(diào)用C語言的庫函數(shù)一樣調(diào)用它,如b=_nassert(N>=10);匯編代碼以C代碼可以調(diào)用的函數(shù)出現(xiàn)。本文采用第三種形式。為了使程序代碼的執(zhí)行具有盡可能高的執(zhí)行效率,本文將著重點放在并行匯編代碼的編程,而不是線性匯編代碼的編程。
1 C語言與匯編語言混合編程的接口規(guī)范和標(biāo)準(zhǔn)
用C語言編寫的代碼中核心代碼常常只是整個程序代碼的5%,但是卻占用了整個程序約95%的執(zhí)行時間。對這些核心代碼采用匯編語言編寫,可以大大提高代碼的執(zhí)行效率,而C語言程序可以象調(diào)用C程序的一個函數(shù)那樣去調(diào)用這個匯編函數(shù)。為了實現(xiàn)C語言和匯編語言的混合編程,需要注意一些規(guī)定的接口規(guī)范和標(biāo)準(zhǔn)。
(1)采用C語言和匯編語言混合編程時,TMS320C62X定義了一套嚴(yán)格的寄存器規(guī)則。這個寄存器規(guī)則表明了編譯器如何使用這些寄存器以及在函數(shù)調(diào)用過程中如何保護這些寄存器。
調(diào)用函數(shù)保護了寄存器A0~A9和B0~B9,這就使得在編寫匯編程序" title="匯編程序">匯編程序的時候可以任意的使用這幾個寄存器而不需保護它們。但當(dāng)使用到寄存器A10~A15或B10~B15的時候,則必須自行對它們進行保護。長型、雙精度型或者是長雙精度型的數(shù)據(jù)對象要放在一個奇/偶寄存器對(如A1:A0)里,奇數(shù)寄存器存放著數(shù)據(jù)的符號位、指數(shù)位和最高有效位,而偶數(shù)寄存器則存放著低有效位。
在默認(rèn)情況下,A3用作返回結(jié)構(gòu)指針寄存器,B3用作被調(diào)用函數(shù)返回地址寄存器,A15用作幀指針寄存器,B14用作數(shù)據(jù)頁指針寄存器,B15用作堆棧指針寄存器。這些寄存器在被調(diào)用的匯編函數(shù)中用到時都要進行保護。
(2)調(diào)用函數(shù)將參數(shù)傳遞到被調(diào)用函數(shù)中,前十個參數(shù)將被從左到右依次放入寄存器A4、B4、A6、B6、A8、B8、A10、B10、A12和B12,如果傳遞的參數(shù)是長型、雙精度型或者是長雙精度型,則將參數(shù)依次放入寄存器組A5:A4、B5:B4、A7:A6等,并將剩下的變量按相反的順序放在堆棧里。注意,如果傳遞的參數(shù)是一個結(jié)構(gòu)類型的參數(shù),則傳遞的是該結(jié)構(gòu)類型的地址。
(3)如果在C/C++調(diào)用函數(shù)中做了正確的函數(shù)返回聲明,則被調(diào)用的匯編函數(shù)可以返回有效值。如果返回值是整型或32位的浮點型,則放在寄存器A4中返回;如果返回值是雙精度或是長雙精度型,則放在A5:A4中返回;如果返回值是一個結(jié)構(gòu)類型,則將其結(jié)構(gòu)的地址放在A3中返回。
(4)編譯器為所有的外部對象指定一個鏈接時的名字。當(dāng)寫匯編語言代碼時,必須用與這個名字相同的名字。對于只在匯編語言模塊中用到的變量的標(biāo)識符,不能從下劃線開始。任何一個在匯編語言中聲明的對象都要使其在C/C++中是可訪問的,那么在匯編語言中必須用.def 或.global將其聲明為外部變量。同樣在匯編語言中要引用C/C++函數(shù)或?qū)ο髸r,必須用.ref 或.global將C/C++對象聲明,這將產(chǎn)生一個在匯編語言函數(shù)中沒有定義的由鏈接器辨識的外部引用。
還有一些細(xì)節(jié)也需要注意,如中斷子程序必須把該子程序?qū)⒁玫降乃屑拇嫫鬟M行入棧處理;除了全局變量的初始化外,匯編語言的模塊不得因為任何目的而使用.cinit段;匯編代碼的結(jié)束需用指令B.s2 B3將程序執(zhí)行從被調(diào)用函數(shù)返回到C語言調(diào)用函數(shù)中。
2 并行匯編代碼的編寫
C6000的匯編代碼格式如下:
標(biāo)號: 并行標(biāo)記? [條件寄存器]指令助記符 功能單元? 操作數(shù) ;注釋。如:
?????? LDW? .D2? *B4,B2
?????? ||? [A1]SHL?? .S2X? A4,B4 ;用到了交叉數(shù)據(jù)通道
TMS320C62X片內(nèi)有8個并行的處理單元,分為相同的兩組。其體系結(jié)構(gòu)采用超長指令字(VLIW)結(jié)構(gòu),一個指令包里的8條并行指令可同時分配到8個處理單元并行運行。這種一個指令包里有8條指令并行執(zhí)行也給并行匯編代碼的編寫帶來很多要考慮的問題,具體如下: ?
(1)TMS320C62X指令的執(zhí)行可以用延遲間隙來說明。延遲間隙在數(shù)量上等于從指令的源操作數(shù)被讀取到執(zhí)行的結(jié)果可以被訪問所用的指令周期" title="指令周期">指令周期。如對于乘法指令(MPY),源操作數(shù)從第i個周期被讀取,則其計算結(jié)果在第(i+2)個周期才可用。
(2)使用相同功能單元的兩條指令不能被安排為并行指令。
(3)使用同一條交叉通路的兩條指令不能被安排在同一個執(zhí)行指令包中,這是因為從寄存器組A~B或者從B~A都只有一條交叉通路。?
(4)將數(shù)據(jù)讀入到(或存儲自)相同寄存器組的兩條讀(寫)指令不能被安排在同一個執(zhí)行包中。
(5)每一個執(zhí)行包里只能允許每一寄存器組處理一個長定點類型數(shù)據(jù)。
(6)在一個指令周期內(nèi)對同一寄存器讀取多于四次是不允許的,但條件寄存器不在此限制之列。在一個指令周期內(nèi),不能 同時存在兩條寫入同一寄存器的指令,只有在寫操作不是在同一個指令周期發(fā)生時,才可以將具有同一目的地址的兩條指令安排并行。
3 基于TMS320C62X的運動補償?shù)幕旌暇幊淘O(shè)計實例
運動補償是MPEG-4標(biāo)準(zhǔn)中的一種重要算法。運動補償是指根據(jù)運動矢量在參考幀中找出參考塊。如果運動矢量的X分量和Y分量都是整象素長度,則直接在參考幀中找出參考塊。如果為半象素長度,則需要通過內(nèi)插運算計算出參考塊,計算出的參考塊需要加上解碼得出的誤差塊才能得到當(dāng)前參考塊。本文給出了運動矢量的X分量和Y分量都是整象素長度時的運動補償方法。根據(jù)運動矢量可直接在參考幀中找到參考塊(8×8)。完成此功能的C語言函數(shù)如下:
void mc_case_a2(unsigned? char *pSrc, short SrcOffset, short SrcWidth, unsigned? char *pDst, short RoundCtrl)
{?? ……
???? ????????? for (i=0; i<8; i++)
????? {
???????????????????? *(tmp_P_Dst+i) = *(tmp_P_Src+i);
???? ? ......
????????????? }
}
參數(shù)運動矢量SrcOffset對4(4個字節(jié)為一個字,長32位)的余數(shù)可能是0、1、2、3。當(dāng)余數(shù)是0的時候,編譯后執(zhí)行代碼是按字讀取(LDW)的,這充分體現(xiàn)了TMS320C62X的優(yōu)點,也使程序的運行效率比較高。而當(dāng)余數(shù)不為0的時候,則可能是按字節(jié)讀取(LDB)或是按半字讀取(LDH),這使程序的運行效率較低。視頻的編碼和解碼都要用到運動補償來重構(gòu)圖像,這是一個很費時的操作,而且其代碼也是圖像處理中的核心代碼,這樣就要求編寫高效的程序來完成此操作。為了使代碼的運行效率更高,且結(jié)合TMS320C62X的硬件特點,希望對于不同的運動矢量,做運動補償?shù)臅r候都能采用按字讀取和存儲的方式。這需要對運動矢量參數(shù)除以4,根據(jù)余數(shù)調(diào)整指針,使指針始終指向字對齊方式(而在C程序中當(dāng)前塊是char型的以字節(jié)方式存儲的,對其進行移位處理只能是一個字節(jié)一個字節(jié)地進行移位,這就使得在C程序中不能用和匯編程序同樣的方法來對程序進行優(yōu)化),如運動矢量除以4以后的余數(shù)為1,為了使要取的8個象素對準(zhǔn)字訪問方式,則要按圖1進行操作。
?
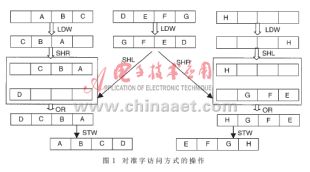
根據(jù)運動矢量參數(shù)進行移位使其對準(zhǔn)字訪問的核心代碼的程序為:
????MVK?????.S2? 0xFFFC,temp???? ;獲得地址的LSB位
????ADD?? ? .L1X? pSrc,offset,pSrc??????;參考塊第一個元素的地址
? ??AND? ?? .L2X pSrc,temp,tmp_pSrc???? ;字對準(zhǔn)訪問的地址
????AND? ?? .S1? 0x0003,pSrc,rshiftA??? ;用兩個LSB位得
???????????????????????????????????? ?? ;到了需右移幾個字
SUB? .L1? 0x04,rshiftA,lshiftA?? ;需左移幾個字
MPY? ?.M1? rshiftA,8,rshiftA ;需右移的#bit數(shù)
MPY???? .M1? lshiftA,8,lshiftA ;需左移的#bit數(shù)
作為一個說明C語言與匯編程序混合編程的設(shè)計例子,采用并行匯編實現(xiàn)了這個函數(shù)的優(yōu)化。這里只給出部分匯編程序:
.text????????????? ??? ;將該段匯編代碼安排在.text
??????????????????????????? ?段,當(dāng)然通過在C語言中用
?????????????????????????? #program_section也可以將其安排在其它自己命名的段中。
????????????????????????????
.global mc_case_a? ????? ;函數(shù)名,用.def或.gloal對其進行
???????????????????????????? ? 聲明,使得C代碼調(diào)用該函數(shù)
????_mc_case_a:???????????? ;標(biāo)號,是C調(diào)用函數(shù)和匯編
?????????????????????????? ?? 被調(diào)用函數(shù)的接口處
……
.asg??? B10,ocsr?????
.asg??? B11,rw_4??
STW?? .D2? ocsr,*stack--[1] ?;被調(diào)用函數(shù)用到了B10~B15,A10
??? STW?? .D2? r_w4,*stack--[1] ;~A15的寄存器,則需對它們保護
MVC? .S2? CSR,ocsr
AND? .S2? -2,ocsr,ocsr?
MVC? .S2? ocsr,CSR?????? ??? ;關(guān)閉某些中斷??????????????????? ……
loop:
LDW .D2? *tmp_pSrc++[src_width1],r_w1?
??????????????????????????????????????????????????????? ;讀取第一個字
LDW .D1?? *pSrc++[1],r-w2?? ;讀取第二個字
????LDW ?.D1?? *pSrc++[src_width2],r-w3 ;讀取第三個字
SHRU?? .S2?? r_w1,rshiftB, r-w1???????????
????SHL?? .S1???r_w3,lshiftA, r_w3
????SHL????.S2X??r_w2,rshiftB,r_w4
????SHRU? ? .S1??r_w2,rshiftA, r_w2
????OR???? .L2???r_w1,r_w4, r_w1
????OR???? .L1?? r_w1,r_w3,r_w2 ;這幾步作了圖a中的操作過程
????STW?? .D2??? r_w1,*pDst++[2]???
????STW?? .D1??? r_w2,*tmpDst++[2] ;存儲取得的兩個字
????B?????.S2 ???loop??????????????????????;延遲跳轉(zhuǎn)到標(biāo)號loop處,實現(xiàn)循環(huán) ……
????LDW?? .D2T2? *++stack[1],r_w4
????LDW?? .D2T2? *++stack[1],ocsr?? ? ;對被調(diào)用函數(shù)中自己保護的寄存器作恢復(fù)處理
??? MVC???.S2??? ocsr, CSR?????? ? ? ?? ;恢復(fù)中斷環(huán)境
????B? ?? .S2???? B3????????????????????????;返回到調(diào)用函數(shù)處
????????????? ……
在TI CCS上用其庫函數(shù)CLOCK()對這個算法的C語言程序和并行匯編程序分別進行了性能測試。在純C語言中,運動矢量對4的偏移量的余數(shù)為0 時,約為33個指令周期, 余數(shù)為1時約為93個指令周期, 余數(shù)為2 時約為 51個指令周期,余數(shù)為3 時約為 93個指令周期,平均約耗時 67個周期。而將其用并行匯編代碼編寫,其周期數(shù)恒定為33個指令周期。33個指令周期的執(zhí)行時間,對于這個函數(shù)基本上是達(dá)到了函數(shù)的最大優(yōu)化。
由此可見,程序的核心算法的代碼用并行匯編程序編寫,而主體的C語言程序則以函數(shù)調(diào)用的形式調(diào)用這些核心算法的并行匯編函數(shù),是提高程序代碼執(zhí)行效率的一種有效方法。
?
參考文獻(xiàn)
1 TMS320C6000 CPU and Instruction Set Reference Guide.?Texas Instruments Incorprated,2000
2 TMS320C600 Programmer’s Guide. Texas Instruments Incorporated, 2001
3 MS320C6000 Optimizing Compiler User’s Guide. Texas Instruments Incorporated,2001
4 任麗香,馬淑芬,李方慧. TMS320C6000系列DSPs的原理與應(yīng)用.北京:電子工業(yè)出版社,2000.7
5 鐘玉琢, 王 琪, 賀玉方.基于對象的多媒體數(shù)據(jù)壓縮編碼國際標(biāo)準(zhǔn)-MPEG-4及其校驗?zāi)P?北京:科學(xué)出版社,2000