
文獻(xiàn)標(biāo)識(shí)碼: B
文章編號(hào): 0258-7998(2010)07-0024-03
1 算法簡(jiǎn)介
說(shuō)話(huà)人識(shí)別系統(tǒng)主要實(shí)現(xiàn)建模及識(shí)別兩方面功能。建模功能提取語(yǔ)音的特征參數(shù)并存儲(chǔ)起來(lái)形成用戶(hù)模板。識(shí)別功能提取語(yǔ)音的特征參數(shù),與模板參數(shù)進(jìn)行匹配,計(jì)算其距離。系統(tǒng)框圖如圖1所示。本文采用改進(jìn)的DTW(Dynamic Time Warping)算法和LPCC(Linear prediction cepstrum coefficients)特征參數(shù)。

1.1 LPCC算法
(1)分幀:語(yǔ)音信號(hào)具有短時(shí)平穩(wěn)性[1],因此先將其分幀,再逐幀處理。
(2)有效音檢測(cè):有效音檢測(cè)基于短時(shí)能量和短時(shí)過(guò)門(mén)限率兩個(gè)參數(shù)。判決時(shí)采取兩級(jí)判斷法:若短時(shí)能量高于高門(mén)限則判為有聲;若低于低門(mén)限則判為靜音;若介于兩者之間,則再判斷其過(guò)門(mén)限率是否高于過(guò)門(mén)限率門(mén)限,若滿(mǎn)足則判為有聲,否則為靜音。
(3)加窗:加窗可濾去不需要的頻率分量,同時(shí)有利于減少LPCC算法在幀頭及幀尾處的誤差。本設(shè)計(jì)采用漢明窗,其表達(dá)式如下:
1.2 改進(jìn)的DTW算法
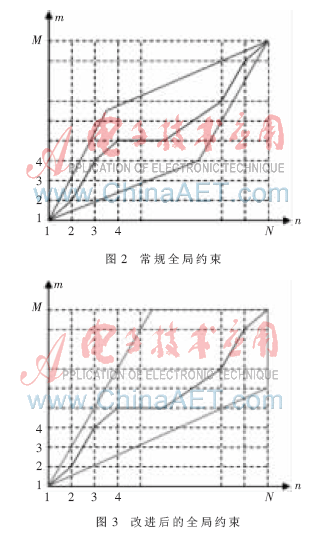
1.2.1 全局約束
圖2和圖3中,橫軸為測(cè)試語(yǔ)音參數(shù),縱軸為模板參數(shù),單位為幀。算法以測(cè)試語(yǔ)音為基準(zhǔn)逐幀進(jìn)行。如圖2,傳統(tǒng)的DTW算法中,測(cè)試參數(shù)長(zhǎng)度無(wú)法預(yù)知時(shí)全局約束便無(wú)法確定。圖3為改進(jìn)后的DTW,可在未知測(cè)試參數(shù)長(zhǎng)度的情況下進(jìn)行全局約束,配合幀同步算法,便于算法的實(shí)時(shí)處理。
1.2.2 局部約束
得到當(dāng)前距離后便要進(jìn)行前向路徑搜索。n=1指定與m=1匹配。從n=2開(kāi)始,每個(gè)交叉點(diǎn)(n,m)可能的前向路徑為(n-1,m)、(n-1,m-1)、(n-1,m-2),選出其中最小者作為當(dāng)前點(diǎn)(n,m)的前向路徑,并將該點(diǎn)的累加距離和加上其當(dāng)前距離作為當(dāng)前點(diǎn)的累加距離。最終在n=N處可得到若干個(gè)累加距離,選其最小者為最終匹配結(jié)果。
1.3 Matlab仿真
1.3.1 實(shí)驗(yàn)1:對(duì)個(gè)性信息的識(shí)別能力
實(shí)驗(yàn)1的目的在于觀察算法對(duì)于話(huà)者個(gè)性信息的識(shí)別能力,實(shí)驗(yàn)用的語(yǔ)音均為各話(huà)者對(duì)正確詞“開(kāi)門(mén)”的發(fā)音,以避免不同單詞帶來(lái)的影響。實(shí)驗(yàn)結(jié)果如圖4所示,系統(tǒng)的等錯(cuò)誤率(EER)為0.01,即當(dāng)錯(cuò)識(shí)率為0.01時(shí)錯(cuò)拒率也為0.01。

1.3.2 實(shí)驗(yàn)2:對(duì)語(yǔ)意信息的識(shí)別能力
實(shí)驗(yàn)2的目的在于觀察識(shí)別算法對(duì)于語(yǔ)意的識(shí)別能力,實(shí)驗(yàn)用的語(yǔ)音均為同一話(huà)者對(duì)正確詞及錯(cuò)誤詞的發(fā)音,以避免因不同話(huà)者帶來(lái)的影響。如圖5所示,在門(mén)限為1.25時(shí)得到系統(tǒng)的等錯(cuò)誤率(EER)為0.01。比較實(shí)驗(yàn)1、實(shí)驗(yàn)2的結(jié)果可知,算法對(duì)語(yǔ)義的識(shí)別能力和對(duì)話(huà)者個(gè)性信息的識(shí)別能力相近。

1.3.3 實(shí)驗(yàn)3:綜合測(cè)試
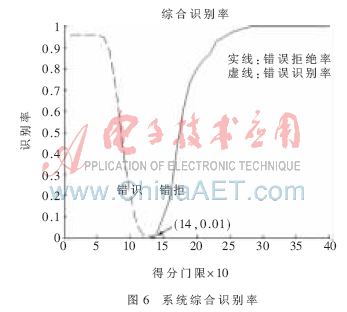
實(shí)驗(yàn)3綜合考慮了話(huà)者的個(gè)性信息及語(yǔ)意信息。如圖6所示,在門(mén)限為1.4時(shí),得到系統(tǒng)的等錯(cuò)誤率為0.01,也即此時(shí)系統(tǒng)的正確識(shí)別率為99%,同時(shí)存在1%的錯(cuò)誤識(shí)別率。
2 SoPC系統(tǒng)構(gòu)建
(1)CPU設(shè)置。NiosII core選定為NiosII/f。使能嵌入式硬件乘法器。復(fù)位地址設(shè)為cfi_flash,異常向量地址設(shè)定為ssram_2M,在custom instructions中添加用戶(hù)自定義指令floating Point Hardware。
(2)定時(shí)器設(shè)置。本設(shè)計(jì)使用了兩個(gè)定時(shí)器。Timer用于產(chǎn)生內(nèi)部中斷采集語(yǔ)音樣點(diǎn),設(shè)其計(jì)時(shí)周期為125 μs(對(duì)應(yīng)采樣率8 kHz)。Timer_stamp用于插入時(shí)間標(biāo)簽,定時(shí)周期采用默認(rèn)值。
(3)其他外設(shè)。NiosII核中還包含以下外設(shè):片上RAM/ROM、FLASH、SDRAM、SSRAM、按鍵、開(kāi)關(guān)、LED、音頻模塊、七段數(shù)碼管、LCD。
3 軟件流程
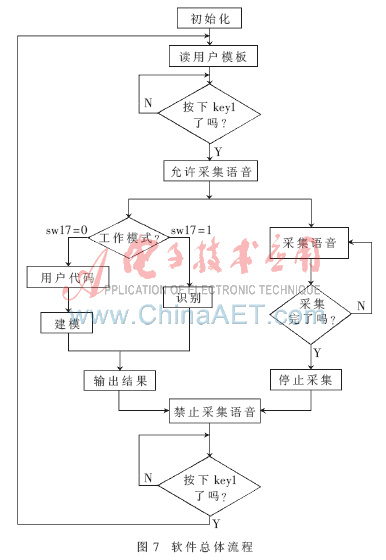
總體工作流程如圖7所示。系統(tǒng)首先初始化,然后讀出模板數(shù)據(jù),等待用戶(hù)按下按鍵。在此期間,用戶(hù)應(yīng)設(shè)置好系統(tǒng)工作模式(建模或識(shí)別)及話(huà)者代碼。然后按下按鍵開(kāi)始以中斷方式采集語(yǔ)音,并運(yùn)行函數(shù)主體。
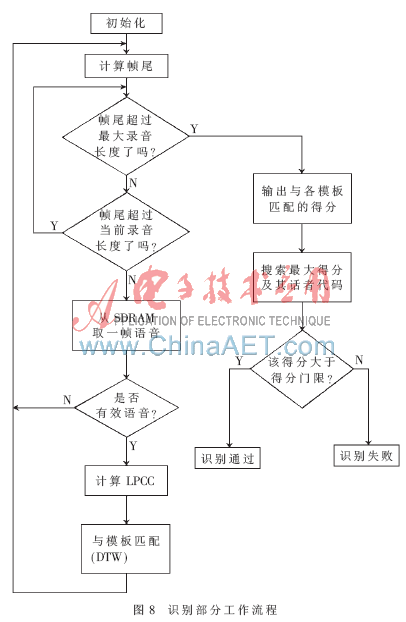
識(shí)別部分流程如圖8所示。函數(shù)首先判斷語(yǔ)音是否已經(jīng)采集完畢及LPCC算法是否已經(jīng)進(jìn)行到最后一幀,若同時(shí)滿(mǎn)足則結(jié)束運(yùn)算,否則繼續(xù)運(yùn)行。若當(dāng)前幀為有效音,則計(jì)算出其LPCC,并調(diào)用DTW子函數(shù),針對(duì)各模板分別計(jì)算距離得分。運(yùn)算完所有語(yǔ)音幀后,便可得到測(cè)試語(yǔ)音對(duì)各模板的最終得分,取其最大者記為當(dāng)次得分。若該得分大于得分門(mén)限,則識(shí)別通過(guò);否則予以拒絕。
建模部分流程的前半部分與識(shí)別過(guò)程類(lèi)似,不同之處在于建模過(guò)程只調(diào)用了LPCC算法。算法完成后,系統(tǒng)將LPCC矩陣寫(xiě)入對(duì)應(yīng)的Flash地址空間存儲(chǔ)。
4 軟硬件協(xié)同設(shè)計(jì)與優(yōu)化
4.1 軟件設(shè)計(jì)與優(yōu)化
(1)將數(shù)據(jù)緩存至SDRAM。最初的程序設(shè)計(jì)中使用數(shù)組存儲(chǔ)大型變量,后來(lái)改為將這些數(shù)據(jù)緩存于SDRAM中。改進(jìn)后,在板運(yùn)行速度無(wú)明顯改變,但NiosII軟件的運(yùn)行速度及穩(wěn)定性得到了提高。
(2)用float數(shù)據(jù)類(lèi)型代替double。最初的程序大量使用了雙精度數(shù)據(jù)類(lèi)型,但后來(lái)發(fā)現(xiàn)單精度浮點(diǎn)型已經(jīng)可以滿(mǎn)足要求,因此將數(shù)據(jù)類(lèi)型改為單精度浮點(diǎn)型(float),使得程序運(yùn)行速度提升了一倍。
(3)用指針?lè)绞皆L(fǎng)問(wèn)數(shù)組。改用指針的方式訪(fǎng)問(wèn)數(shù)組改善了程序的執(zhí)行效率,運(yùn)行速度有一定提升。
(4)用讀表法獲取漢明窗函數(shù)。最初的程序是通過(guò)運(yùn)算公式的方式得到窗函數(shù)的各個(gè)樣點(diǎn)值的,后改用讀表法,使得加漢明窗這一步驟耗時(shí)減少了98.7%,整個(gè)LPCC運(yùn)算耗時(shí)因此減少了59.3%。
(5)語(yǔ)音數(shù)據(jù)存儲(chǔ)為float類(lèi)型。最初的設(shè)計(jì)中,系統(tǒng)采集到原始語(yǔ)音數(shù)據(jù)后直接將其存儲(chǔ)起來(lái),后來(lái)改為將數(shù)據(jù)解碼后再存儲(chǔ),使得LPCC中取語(yǔ)音部分的時(shí)間由888 μs降至98μs。
4.2 硬件設(shè)計(jì)與優(yōu)化
(1)用定時(shí)器中斷方式采集語(yǔ)音。最初的設(shè)計(jì)中,系統(tǒng)必須在采集完所有語(yǔ)音數(shù)據(jù)之后才能對(duì)其進(jìn)行處理。后改用中斷方式采集語(yǔ)音,則可實(shí)現(xiàn)每采集滿(mǎn)一幀語(yǔ)音數(shù)據(jù)便進(jìn)行處理,極大地提升了處理速度。
(2)添加用戶(hù)自定義浮點(diǎn)指令。語(yǔ)音信號(hào)處理過(guò)程涉及大量單精度浮點(diǎn)型數(shù)據(jù)的運(yùn)算,因此在CPU中添加浮點(diǎn)指令。加入浮點(diǎn)指令后,系統(tǒng)耗時(shí)降低了90%以上。
本設(shè)計(jì)在算法上充分利用了DTW算法的特點(diǎn),既能識(shí)別語(yǔ)音內(nèi)容又能區(qū)分說(shuō)話(huà)人,很好地完成了文本有關(guān)的說(shuō)話(huà)人識(shí)別功能。同時(shí)對(duì)識(shí)別算法進(jìn)行幀同步處理,為算法的實(shí)時(shí)實(shí)現(xiàn)打下基礎(chǔ)。本設(shè)計(jì)在實(shí)現(xiàn)時(shí)采用軟硬件協(xié)同設(shè)計(jì)方法,在軟件和硬件上進(jìn)行設(shè)計(jì)和優(yōu)化,使得設(shè)計(jì)有很好的實(shí)時(shí)性。
作品的實(shí)際測(cè)試情況是:選取門(mén)限為1.5時(shí),系統(tǒng)的錯(cuò)識(shí)率可降至0%,此時(shí)正確識(shí)別率為90%,還有10%的拒識(shí)。識(shí)別時(shí)系統(tǒng)的響應(yīng)時(shí)間是8.5 ms。
參考文獻(xiàn)
[1] 趙力.語(yǔ)音信號(hào)處理[M].北京:機(jī)械工業(yè)出版社,2003.
[2] 馬志欣,王宏,李鑫.語(yǔ)音識(shí)別技術(shù)綜述[J].昌吉學(xué)院學(xué)報(bào),2006(3).
[3] 周立功.SoPC嵌入式系統(tǒng)基礎(chǔ)教程[M].北京:北京航空航天大學(xué)出版社,2006.
[4] 周鳳偉,劉操.1比特Sigma Delta調(diào)制在DSD中的應(yīng)用[J].廣播與電視技術(shù),2010(1).
[5] 沈佳銘.一種可重構(gòu)的24bitΣ-Δ調(diào)制器的設(shè)計(jì)[J].微電子學(xué)與計(jì)算機(jī),2007,24(4).
[6] 石博雅.G.726語(yǔ)音編解碼器在SoPC中的實(shí)現(xiàn)[J].電子技術(shù)應(yīng)用,2005(8).
[7] 葛保建.基于SoPC的軟硬件協(xié)同設(shè)計(jì)平臺(tái)的研究與實(shí)現(xiàn)[D].武漢科技大學(xué)碩士學(xué)位論文集,2008(3).