
近年來,高性能數(shù)字信號處理芯片DSP(Digital Signal Process)技術(shù)的迅速發(fā)展,為語音識別的實(shí)時實(shí)現(xiàn)提供了可能,其中,ADI公司的數(shù)字信號處理芯片以其良好的性價比和代碼的可移植性被廣泛地應(yīng)用于各個領(lǐng)域。因此,我們采用ADI公司的定點(diǎn)DSP處理芯片ADSP2181實(shí)現(xiàn)了語音信號的識別。
1 語音識別的基本過程
根據(jù)實(shí)際中的應(yīng)用不同,語音識別系統(tǒng)可以分為:特定人與非特定人的識別、獨(dú)立詞與連續(xù)詞的識別、小詞匯量與大詞匯量以及無限詞匯量的識別。但無論那種語音識別系統(tǒng),其基本原理和處理方法都大體類似。一個典型的語音識別系統(tǒng)的原理圖如圖1所示。
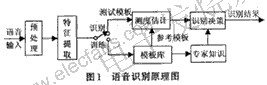
語音識別過程主要包括語音信號的預(yù)處理、特征提取、模式匹配幾個部分。預(yù)處理包括預(yù)濾波、采樣和量化、加窗、端點(diǎn)檢測、預(yù)加重等過程。語音信號識別最重要的一環(huán)就是特征參數(shù)提取。提取的特征參數(shù)必須滿足以下的要求:
(1)提取的特征參數(shù)能有效地代表語音特征,具有很好的區(qū)分性;
(2)各階參數(shù)之間有良好的獨(dú)立性;
(3)特征參數(shù)要計算方便,最好有高效的算法,以保證語音識別的實(shí)時實(shí)現(xiàn)。
在訓(xùn)練階段,將特征參數(shù)進(jìn)行一定的處理后,為每個詞條建立一個模型,保存為模板庫。在識別階段,語音信號經(jīng)過相同的通道得到語音特征參數(shù),生成測試模板,與參考模板進(jìn)行匹配,將匹配分?jǐn)?shù)最高的參考模板作為識別結(jié)果。同時,還可以在很多先驗(yàn)知識的幫助下,提高識別的準(zhǔn)確率。
2 系統(tǒng)的硬件結(jié)構(gòu)
2.1 ADSP2181的特點(diǎn)
AD公司的DSP處理芯片ADSP2181是一種16b的定點(diǎn)DSP芯片,他內(nèi)部存儲空間大、運(yùn)算功能強(qiáng)、接口能力強(qiáng)。有以下的主要特點(diǎn):
(1)采用哈佛結(jié)構(gòu),外接16.67MHz晶振,指令周期為30ns,指令速度為33MI/s,所有指令單周期執(zhí)行;
(2)片內(nèi)集成了80 kB的存儲器:16 kB字的(24b)的程序存儲器和16kB字(16b)的數(shù)據(jù)存儲器;
(3)內(nèi)部有3個獨(dú)立的計算單元:算術(shù)邏輯單元(ALU)、乘累加器(MAC)和桶形移位器(SHIFT),其中乘累加器支持多精度和自動無偏差舍人;
(4)一個16b的內(nèi)部DMA端口(1DMA),供片內(nèi)存儲器的高速存取;一個8b自舉DMA(BDMA)口,用于從自舉程序存儲器中裝載數(shù)據(jù)和程序;
(5)6個外部中斷,并且可以設(shè)置優(yōu)先級或屏蔽等。
由于ADSP2181以上的特點(diǎn),使得該芯片構(gòu)成的系統(tǒng)體積小、性能高、成本和功耗低,能較好地實(shí)現(xiàn)語音識別算法
2.2 系統(tǒng)的硬件結(jié)構(gòu)
在構(gòu)成語音識別電路時,我們采用了ADSP2181的主從結(jié)構(gòu)設(shè)計方式,通過IDMA口由CPU裝載程序。語音識別系統(tǒng)的硬件結(jié)構(gòu)如圖2所示。
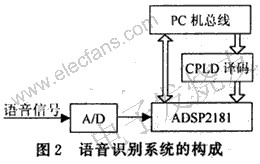
在這種結(jié)構(gòu)中,PC機(jī)為主CPU,ADSP2181為從CPU,由PC機(jī)通過IDMA口將程序裝載到ADSP2181的內(nèi)部存儲器中。PC機(jī)總線通過CPLD譯碼,形成IRD,IWR,IAL,IS等控制信號,與ADSP2181的IDMA口相連。這樣,在ADSP2181全速運(yùn)行時,主機(jī)可以查詢從機(jī)的運(yùn)行狀態(tài),可以訪問到ADSP2181內(nèi)部所有的程序存儲器和數(shù)據(jù)存儲器。這對程序的編譯和調(diào)試,以及語音信號的實(shí)時處理帶來了極大的方便。
3 語音識別的DSP實(shí)現(xiàn)技術(shù)
3.1 浮點(diǎn)運(yùn)算的定點(diǎn)實(shí)現(xiàn)
在語音識別的算法中,有許多的浮點(diǎn)運(yùn)算。用定點(diǎn)DSP來實(shí)現(xiàn)浮點(diǎn)運(yùn)算是在編寫語音識別程序中需要首先解決的問題。這個問題可以通過數(shù)的定標(biāo)方法來實(shí)現(xiàn)。數(shù)的定標(biāo)就是決定小數(shù)點(diǎn)在定點(diǎn)數(shù)中的位置。Q表示法是一種常用的定標(biāo)方法。其表示機(jī)制是:
設(shè)定點(diǎn)數(shù)是J,浮點(diǎn)數(shù)是)/,則Q法表示的定點(diǎn)數(shù)與浮點(diǎn)數(shù)的轉(zhuǎn)換關(guān)系為:
浮點(diǎn)數(shù))/轉(zhuǎn)換為定點(diǎn)數(shù)x:x= (int)y×2Q;
定點(diǎn)數(shù)z轉(zhuǎn)換為浮點(diǎn)數(shù)y:y =(float)x×2-Q。
3.2 數(shù)據(jù)精度的處理
用16b的定點(diǎn)DSP實(shí)現(xiàn)語音識別算法時,雖然程序的運(yùn)行速度提高了,但是數(shù)據(jù)精度比較低。這可能由于中間過程的累計誤差而引起運(yùn)算結(jié)果的不正確。為了提高數(shù)據(jù)的運(yùn)算精度,在程序中采用了以下的處理方法:
(1)擴(kuò)展精度
在精度要求比較高的地方,將計算的中間變量采用32b,甚至48b來表示。這樣,在指令條數(shù)增加不多的情況下卻使運(yùn)算精度大大提高了。
(2)采用偽浮點(diǎn)法來表示浮點(diǎn)數(shù)
偽浮點(diǎn)法即用尾數(shù)+指數(shù)的方法來表示浮點(diǎn)數(shù)。這時,數(shù)據(jù)塊的尾數(shù)可以采用Q1.15數(shù)據(jù)格式,數(shù)據(jù)塊的指數(shù)相同。這種表示數(shù)據(jù)的方法有足夠大的數(shù)據(jù)范圍,可以完全滿足數(shù)據(jù)精度的要求,但是需要自己編寫一套指數(shù)和尾數(shù)運(yùn)算庫,會額外增加程序的指令數(shù)和運(yùn)算量,不利于實(shí)時實(shí)現(xiàn)。
以上兩種方法,都可以提高運(yùn)算精度,但在實(shí)際操作時,要根據(jù)系統(tǒng)的要求和算法的復(fù)雜度,來權(quán)衡考慮。
3.3 變量的維護(hù)
在高級語言中,有全局變量與局部變量存儲的區(qū)別,但在DSP程序中,所有聲明的變量在鏈接時都會分給數(shù)據(jù)空間。所以如果按照高級語言那樣定義局部變量,就會浪費(fèi)大量的DSP存儲空間,這對數(shù)據(jù)空間較為緊張的定點(diǎn)DSP來說,顯然是不合理的。為了節(jié)省存儲空間,在編寫DSP程序時,最好維護(hù)好一張變量表。每進(jìn)入一個DSP子模塊時,不要急于分配新的局部變量,應(yīng)優(yōu)先使用已分配但不用的變量。只有在不夠時才分配新的局部變量。
3.4 循環(huán)嵌套的處理
語音識別算法的實(shí)現(xiàn),有許多是在循環(huán)中實(shí)現(xiàn)的。對于循環(huán)的處理,需要注意以下幾個問題:
(1)ADSP2100系列DSP芯片中,循環(huán)嵌套最多不能超過4重,否則就會發(fā)生堆棧溢出,導(dǎo)致程序不能正確執(zhí)行。但在語音識別的DSP程序中,包括中斷在內(nèi)的嵌套程序往往超過4重。這時不能使用DSP提供的do…unTIl…指令,只能自己設(shè)計出一些循環(huán)變量,自己維護(hù)這些變量。由于這時沒有使用DSP的循環(huán)堆棧,所以也不會導(dǎo)致堆棧溢出。另外,如果采用jump指令從循環(huán)指令中跳出,則必須維護(hù)好PC,LOOP和CNTR三個堆棧的指針。
(2)盡量減少循環(huán)體內(nèi)的指令數(shù)。在多重循環(huán)的內(nèi)部,減少指令數(shù)有利于降低程序的執(zhí)行次數(shù)。這樣有利于減少程序的執(zhí)行時間、提高操作的實(shí)時性。
3.5 采用模塊化的程序設(shè)計方法
在語音識別算法的實(shí)現(xiàn)中,為了便于程序的設(shè)計和調(diào)試,采用了模塊化的程序設(shè)計方法。以語音識別的基本過程為依據(jù)進(jìn)行模塊劃分,每個模塊再劃分為若干個子模塊,然后以模塊為單元進(jìn)行編程和調(diào)試。在編寫程序之前,首先用高級語言對每個模塊進(jìn)行算法仿真,在此基礎(chǔ)上再進(jìn)行匯編程序的編寫。在調(diào)試時,可以采用高級語言與匯編語言對比的調(diào)試方式,這樣可以通過跟蹤高級語言與匯編語言的中間狀態(tài),來驗(yàn)證匯編語言的正確性,并及時的發(fā)現(xiàn)和修改錯誤,縮短編程周期。另外,在程序的編寫過程中,應(yīng)在關(guān)鍵的部分加上必要的注釋與說明,以增強(qiáng)程序的可讀性。
在總調(diào)時,需要在各模塊中設(shè)置好相應(yīng)的人口參數(shù)與出口參數(shù),維護(hù)好堆棧指針與中間變量等。
3.6 利用C語言與匯編語言的混合編程
現(xiàn)在,大多數(shù)的DSP芯片都支持匯編語言與C或C++語言的混合編程,ADSP2181也不例外。用C語言開發(fā)DSP程序具有縮短開發(fā)周期、降低程序復(fù)雜度的優(yōu)點(diǎn),但是,程序的執(zhí)行效率卻不高,會增加額外的機(jī)器周期,不利于程序的實(shí)時實(shí)現(xiàn)。為此,在用C語言編寫語音識別算法時,我們采用了定點(diǎn)化處理技術(shù)。ADSP2181是16位定點(diǎn)處理器,定點(diǎn)化處理應(yīng)注意以下幾個問題:
(1)ADSP2181支持小數(shù)和整數(shù)兩種運(yùn)算方式,在計算時應(yīng)選擇小數(shù)方式,使計算結(jié)果的絕對值都小于1;
(2)用雙字定點(diǎn)運(yùn)算庫代替C語言的浮點(diǎn)庫,提高運(yùn)算精度;
(3)注意在每次乘加運(yùn)算之后進(jìn)行飽和操作,防止結(jié)果的上溢和下溢;
(4)循環(huán)處理后的一組數(shù)據(jù)可能有不同的指數(shù),要進(jìn)行歸一化處理,以便后續(xù)定點(diǎn)操作對指數(shù)和尾數(shù)部分分別處理。
4 結(jié) 語
用定點(diǎn)DSP芯片構(gòu)成的語音識別系統(tǒng)有著廣泛的應(yīng)用前景,在編寫語音識別算法時,對其進(jìn)行定點(diǎn)化處理以及一些原則和方法對其他類似的算法也有著現(xiàn)實(shí)指導(dǎo)意義。在實(shí)際應(yīng)用中,應(yīng)注意根據(jù)DSP芯片的特點(diǎn),對算法進(jìn)行優(yōu)化,使得DSP芯片的性能得到充分的發(fā)揮。