(北京郵電大學(xué) 計(jì)算機(jī)學(xué)院體系結(jié)構(gòu)中心,北京 100876)
1 引言
互聯(lián)網(wǎng)已成為人們低成本高效率獲取信息的平臺,隨著各站點(diǎn)訪問量和信息交流量的迅猛增長,網(wǎng)絡(luò)接入邊緣的瓶頸阻塞日益嚴(yán)重。因此,必須提高網(wǎng)絡(luò)中核心設(shè)備的性能,以滿足網(wǎng)絡(luò)流量日益增長的需要。常見的通信網(wǎng)由電路交換系統(tǒng)和基于分組的交換系統(tǒng)構(gòu)成,整個網(wǎng)絡(luò)由一系列小網(wǎng)絡(luò)、傳輸和終端設(shè)備組成,網(wǎng)絡(luò)間互通性差、可管理性不強(qiáng),網(wǎng)絡(luò)業(yè)務(wù)不靈活。隨著電子商務(wù)、多媒體業(yè)務(wù)和VoIP等對帶寬的要求較高的業(yè)務(wù)的出現(xiàn),設(shè)計(jì)并實(shí)現(xiàn)高性能的網(wǎng)絡(luò)設(shè)備" title="網(wǎng)絡(luò)設(shè)備">網(wǎng)絡(luò)設(shè)備更加重要。為了滿足越來越多的網(wǎng)絡(luò)業(yè)務(wù)對網(wǎng)絡(luò)帶寬的需求,有研究機(jī)構(gòu)和企業(yè)提出采用X86+FPGA/ASIC的系統(tǒng)架構(gòu),這種架構(gòu)帶有明顯的數(shù)據(jù)平面和控制平面相分離的特征,因此能夠?qū)崿F(xiàn)高性能目標(biāo)。但由于FPGA或ASIC技術(shù)需要很大的研發(fā)投入,且進(jìn)行功能擴(kuò)展的性能較差,產(chǎn)品更新?lián)Q代的速度很慢。因此,這里提出在網(wǎng)絡(luò)設(shè)備中應(yīng)用多核" title="多核">多核多線程處理器,繼續(xù)分離數(shù)據(jù)平面和控制平面,滿足用戶對網(wǎng)絡(luò)業(yè)務(wù)豐富和性能增長同步發(fā)展的需求。
2 框架設(shè)計(jì)及實(shí)現(xiàn)
RMI公司的XLR系列是基于RMI增強(qiáng)型MIPS64" title="MIPS64">MIPS64內(nèi)核,可同時支持32個線程的獨(dú)特構(gòu)架的處理器,工作頻率達(dá)1.5 GHz,同時支持高度集成的獨(dú)立硬件安全引擎和網(wǎng)絡(luò)應(yīng)用加速器。XLR系列處理器采用多核多線程技術(shù),具有很高的數(shù)據(jù)處理能力,可以在復(fù)雜的網(wǎng)絡(luò)環(huán)境中承擔(dān)網(wǎng)絡(luò)設(shè)備高速轉(zhuǎn)發(fā)任務(wù)。為了平衡高速的數(shù)據(jù)轉(zhuǎn)發(fā)和復(fù)雜的業(yè)務(wù)處理之間的矛盾,本系統(tǒng)在XLR系列器件的32個線程上運(yùn)行Linux和VxWorks兩種操作系統(tǒng),并使用VxWorks完成高速的數(shù)據(jù)轉(zhuǎn)發(fā),使用Linux進(jìn)行復(fù)雜的業(yè)務(wù)處理。
如果Linux和VxWorks兩種操作系統(tǒng)運(yùn)行在不同的CORE上,則兩種操作系統(tǒng)不會競爭中斷和BUCKET等硬件資源,但卻對業(yè)務(wù)部署帶來很大麻煩,導(dǎo)致業(yè)務(wù)的劃分粒度也很粗獷。因此,本文提出Linux和VxWorks共CORE,通過共享內(nèi)存區(qū)快速通信的方案,細(xì)化業(yè)務(wù)劃分粒度,并優(yōu)化XLR器件驅(qū)動程序框架,充分發(fā)揮軟硬件資源優(yōu)勢,提升網(wǎng)絡(luò)核心設(shè)備性能。
從硬件配置、網(wǎng)絡(luò)驅(qū)動、軟件結(jié)構(gòu)3個層次構(gòu)建網(wǎng)絡(luò)中核心設(shè)備框架,其中硬件配置用于配置XLR器件硬件資源分布,包括每個CORE相應(yīng)站內(nèi)的桶的深度以及GMAC/SPl4與CORE通過FMN總線通信所需的credits,以支持上層業(yè)務(wù)需要;網(wǎng)絡(luò)驅(qū)動的主要作用是屏蔽操作系統(tǒng)對底層硬件資源的競爭,正確區(qū)分控制業(yè)務(wù)報(bào)文和轉(zhuǎn)發(fā)數(shù)據(jù)報(bào)文,每個網(wǎng)口的網(wǎng)絡(luò)加速引擎將報(bào)文地址和長度信息封裝成FMN消息并提交給相應(yīng)模塊進(jìn)行處理;軟件層的主要作用是更好地利用不同操作系統(tǒng)的優(yōu)點(diǎn),分離控制平面和數(shù)據(jù)平面,實(shí)現(xiàn)兩種操作系統(tǒng)間的通信,以實(shí)現(xiàn)復(fù)雜的業(yè)務(wù)控制和高速的數(shù)據(jù)轉(zhuǎn)發(fā)。圖1為該網(wǎng)絡(luò)核心設(shè)備系統(tǒng)架構(gòu)。
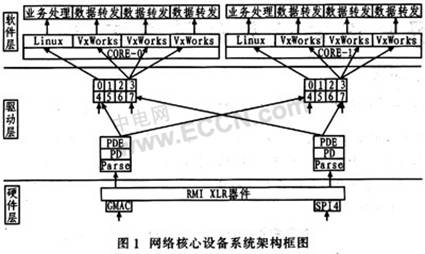
2.1硬件配置
XLR系列處理器通過快速消息網(wǎng)絡(luò)FMN(Fast MessageNetwork)將系統(tǒng)的CPU CORE、報(bào)文處理單元PDE、加密單元Cypto引擎、多處理器互聯(lián)的HT接口(HyperTransport)、PCI-X等互聯(lián)。默認(rèn)情況下,F(xiàn)MN總線上每個站內(nèi)包含8個桶,每個桶的深度為32。每個桶都有其固定的ID,系統(tǒng)中共有128個桶,其中CORE使用前64個桶(0~63號桶)。
為了區(qū)分控制報(bào)文信息和數(shù)據(jù)報(bào)文信息,并結(jié)合網(wǎng)絡(luò)驅(qū)動程序?qū)?bào)文送至正確目的地,使能每個CORE內(nèi)的0,3,4,7號桶,禁用1,2,5,6號桶。每個桶內(nèi)含有64個entry。其中0號桶用于存放目的地是Linux的數(shù)據(jù)報(bào)文,而3號桶用于存放目的地是VxWorks的數(shù)據(jù)報(bào)文。4號桶用于存放Linux操作系統(tǒng)發(fā)送消息后產(chǎn)生的freeback消息,7號桶用于存放VxWorks操作系統(tǒng)發(fā)送消息后產(chǎn)生的freeback消息。為了實(shí)現(xiàn)GMAC/SP14和CORE能夠通過FMN總線通信,必須在每個站維護(hù)一定的credits數(shù),表1列出系統(tǒng)credits分布情況。
2.2 網(wǎng)絡(luò)驅(qū)動
根據(jù)不同的網(wǎng)絡(luò)環(huán)境,可設(shè)計(jì)不同的網(wǎng)絡(luò)驅(qū)動類型。如果網(wǎng)絡(luò)環(huán)境中流量較小,使用網(wǎng)絡(luò)處理器中的一個或幾個硬件線程即可滿足網(wǎng)絡(luò)帶寬要求,則可設(shè)計(jì)集中式網(wǎng)絡(luò)驅(qū)動程序。在集中式網(wǎng)絡(luò)驅(qū)動程序中,一個或少數(shù)幾個VCPU作為數(shù)據(jù)轉(zhuǎn)發(fā)的代理,大部分?jǐn)?shù)據(jù)報(bào)文由這組代理VCPU接收、處理并轉(zhuǎn)發(fā);如果這組代理VCPU收到控制報(bào)文,則判斷報(bào)文目的地,并通過IPI中斷將控制報(bào)文轉(zhuǎn)發(fā)給相應(yīng)VCPU處理。這種驅(qū)動程序設(shè)計(jì)徹底分離數(shù)據(jù)平面和控制平面,但其缺點(diǎn)是代理VCPU的壓力很大,如果網(wǎng)絡(luò)流量變大,則很可能因?yàn)閿?shù)據(jù)報(bào)文擁塞而導(dǎo)致代理VCPU癱瘓,這時整個系統(tǒng)就必須重啟。為了能夠適應(yīng)更大的網(wǎng)絡(luò)流量,這里設(shè)計(jì)分布式網(wǎng)絡(luò)驅(qū)動。分布式網(wǎng)絡(luò)驅(qū)動中,所有VCPU都會接收數(shù)據(jù)報(bào)文和控制報(bào)文,并進(jìn)行相應(yīng)的處理和轉(zhuǎn)發(fā)。分布式網(wǎng)絡(luò)驅(qū)動程序的優(yōu)點(diǎn)是所有VCPU平均分擔(dān)網(wǎng)絡(luò)流量,不會因?yàn)槟硯讉€VCPU癱瘓而導(dǎo)致系統(tǒng)重啟。而分布式驅(qū)動程序使數(shù)據(jù)平面和控制平面的隔離不夠徹底,一定程度上影響數(shù)據(jù)轉(zhuǎn)發(fā)性能。
這里的應(yīng)用場景為網(wǎng)絡(luò)中的核心設(shè)備,因此網(wǎng)絡(luò)流量非常大,可以采用分布式驅(qū)動程序設(shè)計(jì)。GMAC或SPI4接口收到數(shù)據(jù)后,數(shù)據(jù)通過NA的DMA直接存入內(nèi)存區(qū),而NA將收到報(bào)文的信息封裝成FMN消息格式送到CORE0的0號桶。在分布式驅(qū)動程序設(shè)計(jì)中,所有VCPU都要相應(yīng)中斷,中斷掩碼為0xffffffff。每個站內(nèi)的桶接收到消息會隨機(jī)發(fā)送中斷信號到4個VCPU中的一個,收到中斷信號的VCPU響應(yīng)中斷到桶內(nèi)收消息,收到消息后,判斷消息是否需其本身處理,如果無需自己處理,就發(fā)送IPI中斷到目的VCPU,通知目的VCPU處理該消息。圖2為分布式驅(qū)動程序框架。
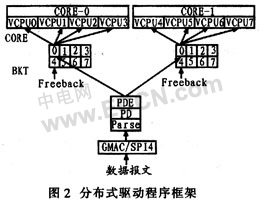
由于每個硬件線程都運(yùn)行獨(dú)立的操作系統(tǒng),而且由于操作系統(tǒng)的差異性,操作系統(tǒng)會競爭資源,因此必須提出一種方案,使資源競爭對Linux和VxWorks操作系統(tǒng)透明。因?yàn)橹袛嘈盘柕捻憫?yīng)單位是CORE,并且CORE內(nèi)4個硬件線程響應(yīng)此中斷是隨機(jī)的,所以硬件線程對中斷的競爭是不可避免的。為此,提出通過下列方案實(shí)現(xiàn)消息發(fā)送到指定的目的地,也即保證Linux不會取走目的地是VxWorks的數(shù)據(jù)報(bào)文。
方案如下:①用某個GMAC網(wǎng)口接收控制消息,用其余GMAC和SP14接口處理數(shù)據(jù)報(bào)文;②每個CORE內(nèi)8個桶,使能4個,禁用4個。分別使能0號桶,3號桶,4號桶,7號桶,禁用1,2,5,6號桶。每個桶內(nèi)含有64個entry。其中0號桶用于存放目的地是Linux的數(shù)據(jù)報(bào)文,而3號桶用于存放目的地是VxWorks的數(shù)據(jù)報(bào)文。4號桶用于存放Linux操作系統(tǒng)發(fā)送消息后產(chǎn)生的freeback消息,7號桶用于存放VxWorks操作系統(tǒng)發(fā)送消息后產(chǎn)生的freeback消息;配置GMAC口NA中的pdeclass寄存器,將所有報(bào)文發(fā)送到CORE內(nèi)的0號桶。配置其余GMAC口和SPI4接口NA的pdeclass寄存器,將所有報(bào)文發(fā)送到CORE內(nèi)的3號桶。分別修改GMAC和SPl4發(fā)送函數(shù),將FREEBACK消息目的地設(shè)定為CORE內(nèi)的4號桶和7號桶。該方案通過優(yōu)化數(shù)據(jù)接收流程,使資源的競爭對操作系統(tǒng)透明,每個操作系統(tǒng)以為自己獨(dú)享全部資源。
由于本文的應(yīng)用環(huán)境網(wǎng)絡(luò)流量很大,其中數(shù)據(jù)流量占到90%左右,而控制信息只占約10%,所以在第1個CORE上,系統(tǒng)在VCPUO上運(yùn)行Linux操作系統(tǒng),負(fù)責(zé)處理控制消息;而其余3個VCPU運(yùn)行VxWorks,負(fù)責(zé)數(shù)據(jù)報(bào)文的轉(zhuǎn)發(fā)。
2.3 軟件結(jié)構(gòu)
網(wǎng)絡(luò)核心設(shè)備系統(tǒng)架構(gòu)軟件層完成操作系統(tǒng)部署方案。XLR系列器件有8個CORE,每個CORE內(nèi)有4個硬件線程,4個硬件線程共享一級高速緩存、桶、中斷等資源。如果以CORE為單位部署操作系統(tǒng),那么CORE內(nèi)4個硬件線程是SMP結(jié)構(gòu),不會競爭上述資源。但按CORE部署操作系統(tǒng)是一種粗粒度的劃分,是資源利用和系統(tǒng)性能的瓶頸。所以本文提出操作系統(tǒng)的部署以VCPU為單位,同一個CORE內(nèi)既可有Linux也可有VxWorks。
Linux和VxWorks的優(yōu)缺點(diǎn)比較:Linux的優(yōu)點(diǎn)有,模塊化設(shè)計(jì),可劃分細(xì)粒度業(yè)務(wù);無版權(quán),免費(fèi)獲取;功能豐富,可擴(kuò)展性強(qiáng);用戶進(jìn)程地址空間獨(dú)立;網(wǎng)絡(luò)資源豐富;系統(tǒng)穩(wěn)定性很高。其缺點(diǎn)為自旋鎖等機(jī)制導(dǎo)致實(shí)時性下降;可能導(dǎo)致中斷丟失;Linux系統(tǒng)管理復(fù)雜,培訓(xùn)需要較長時間。而Vx-Works的優(yōu)點(diǎn)有:實(shí)時性好;內(nèi)存碎片少;系統(tǒng)簡單,調(diào)試容易,有Tomado開發(fā)環(huán)境;商用操作實(shí)時系統(tǒng),提供的資源非常適合嵌入式應(yīng)用:BSP開發(fā)非常規(guī)范。其缺點(diǎn)為內(nèi)核保留的信息很少,導(dǎo)致很難開發(fā)復(fù)雜業(yè)務(wù)流程;網(wǎng)絡(luò)資源很少,技術(shù)支持只有WindRiver;系統(tǒng)穩(wěn)定性取決于開發(fā)者能力;內(nèi)核采用實(shí)存儲管理方式。
為了更好的結(jié)合Linux和VxWorks兩種操作系統(tǒng)的優(yōu)點(diǎn),這里使用Linux操作系統(tǒng)控制平面的業(yè)務(wù)處理,使用Vx-Works負(fù)責(zé)數(shù)據(jù)平面的轉(zhuǎn)發(fā)任務(wù)。
除了資源競爭帶來的問題外,還必須實(shí)現(xiàn)兩種操作系統(tǒng)之間的通信。由于兩種操作系統(tǒng)存在差異性,使兩者之間的交互不能通過簡單進(jìn)程間通信方式FIFO,PIPE等實(shí)現(xiàn)。為了解決兩者間的通信問題,本文提出通過共享內(nèi)存實(shí)現(xiàn)兩種操作系統(tǒng)之間通信的方案。首先,Linux和VxWorks將需要交互的數(shù)據(jù)放人共享內(nèi)存區(qū),然后發(fā)送IPI中斷到目標(biāo)操作系統(tǒng),通知目標(biāo)操作系統(tǒng)去共享內(nèi)存區(qū)取數(shù)據(jù)并進(jìn)行處理。實(shí)現(xiàn)步驟:①VxWorks通過TLB映射共享內(nèi)存區(qū)到虛擬地址。共享內(nèi)存區(qū)經(jīng)TLB映射后,VxWorks操作系統(tǒng)就可讀寫該區(qū)域。②Linux修改link腳本,在進(jìn)程運(yùn)行前預(yù)留共享內(nèi)存區(qū)。③注冊一個字符設(shè)備,用于管理共享內(nèi)存區(qū)。修改該設(shè)備的mmap函數(shù),該mmap函數(shù)實(shí)現(xiàn)共享內(nèi)存區(qū)物理地址到虛擬地址的映射。④如果Linux用戶態(tài)進(jìn)程運(yùn)行,首先打開該字符設(shè)備,調(diào)用mmap函數(shù)映射共享內(nèi)存區(qū)。這樣該用戶態(tài)進(jìn)程就可以操作該共享內(nèi)存區(qū)。⑤如果Linux內(nèi)核態(tài)進(jìn)程運(yùn)行,調(diào)用iormap調(diào)用映射共享內(nèi)存區(qū)物理地址到虛擬地址,這樣內(nèi)核態(tài)進(jìn)程就可以操作該共享內(nèi)存。通過以上5個步驟,建立Linux和VxWorks兩種操作系統(tǒng)之間的共享內(nèi)存區(qū)。
3 性能分析
這里性能測試的目的是測試目標(biāo)網(wǎng)絡(luò)設(shè)備的網(wǎng)絡(luò)吞吐量,即在不丟包的前提下,該設(shè)備所能提供的最大傳輸速率。本次測試使用兩塊XLR系列器件級聯(lián)測試此系統(tǒng)性能,測試用兩塊器件均啟動一個VCPU,也即VCPU0,其上運(yùn)行Linux操作系統(tǒng),安裝netperf網(wǎng)絡(luò)性能測試工具。其中,第1塊器件的VCPU0使用netperf發(fā)送數(shù)據(jù)報(bào)文,另一塊的VCPU0接收并處理數(shù)據(jù)。表2為測試得到的轉(zhuǎn)發(fā)速率。
在數(shù)據(jù)轉(zhuǎn)發(fā)過程中,查看得到每個VCPU的CPU占用率為60%左右,通過優(yōu)化netperf工具,可進(jìn)一步提高轉(zhuǎn)發(fā)性能。
4 結(jié)束語
本文基于多核多線程的處理器,從硬件配置、網(wǎng)絡(luò)驅(qū)動程序、軟件結(jié)構(gòu)3個層次構(gòu)建一套網(wǎng)絡(luò)核心設(shè)備的系統(tǒng)架構(gòu)。該架構(gòu)對復(fù)雜的業(yè)務(wù)處理和高速的網(wǎng)絡(luò)流量轉(zhuǎn)發(fā)都做了優(yōu)化處理。給出3個層次的設(shè)計(jì)框架,并對關(guān)鍵問題提出解決方案。根據(jù)本文得到的實(shí)驗(yàn)數(shù)據(jù),得出利用多核多線程處理器并優(yōu)化硬件配置,在軟件層次優(yōu)化網(wǎng)絡(luò)流量處理流程,細(xì)粒度化業(yè)務(wù)模型,分離數(shù)據(jù)平面和控制平面,可以在完成復(fù)雜業(yè)務(wù)處理流程的前提下,大大提高網(wǎng)絡(luò)流量轉(zhuǎn)發(fā)速率。
