
0 引言
當(dāng)今社會(huì)已經(jīng)步入信息時(shí)代,傳統(tǒng)的信息載體和通信方式已經(jīng)無法滿足人們對信息的需求。而實(shí)驗(yàn)表明:相比較語音和抽象數(shù)據(jù),人類接受的信息更多是以圖片和視頻方式為載體的。其中視頻信息具有直觀、具體和高效的特點(diǎn),這也就決定了視頻通信技術(shù)將成為信息時(shí)代的重要技術(shù)之一。
由于視頻的數(shù)據(jù)量巨大,而存儲(chǔ)視頻的資源通常是非常有限的,因而對視頻進(jìn)行壓縮編碼,以減少存儲(chǔ)資源的消耗,非常必要。然而,通常情況下,使用的壓縮算法的復(fù)雜度越高,壓縮比率越高,視頻播放時(shí)的解碼速度就會(huì)越低。因而在提高編碼壓縮率的同時(shí),也需要對解碼器進(jìn)行相應(yīng)的優(yōu)化,以提高視頻解碼器在目標(biāo)平臺上的性能。本文就實(shí)現(xiàn)了ffmpeg解碼器在龍芯3B上的移植與向量化,提高了該解碼器在龍芯3B上的性能。
1 視頻編/解碼與龍芯3B
1.1 視頻編/解碼
目前,成熟的壓縮編/解碼方法有很多。其中H.261、MPEG-1、MPEG-3和H.263采用了第一代壓縮編碼方法,如預(yù)測編碼、變換編碼、熵編碼以及運(yùn)動(dòng)補(bǔ)償;而MPEG-4和H.264采用了第二代的壓縮編碼方法,如分段編碼和基于模型或?qū)ο蟮木幋a等。
視頻壓縮編碼的主要目的是減少存儲(chǔ)視頻所占用的資源,而解碼技術(shù)的目標(biāo)則是提高解碼的速度,從而提高視頻播放的流暢性。常見的基于H.264編碼方法的軟解碼器包括CoreAVC、ffmpeg和JM等。其中JM是H.264官方網(wǎng)站提供的編/解碼器,集合了各種編/解碼算法,而且代碼的結(jié)構(gòu)清晰,很適合應(yīng)用于對視頻編/解碼技術(shù)的研究。而CoreAVC解碼器則主要用于商用,其解碼速率比ffmpeg快50%以上。ffmpeg是開源的解碼器,而且性能相對較好,很多開源項(xiàng)目都直接或間接地使用了ffmpeg,如mplayer播放器等。通過對性能以及開源特性的綜合考慮,本文選擇ffmlpeg作為移植和向量化對象。
1.2 龍芯3B體系結(jié)構(gòu)
龍芯3B處理器在兼容了MIPS64指令集的同時(shí),實(shí)現(xiàn)了針對多媒體應(yīng)用的向量擴(kuò)展指令,這對視頻編/解碼應(yīng)用性能的提升有很大的幫助。
龍芯3B提供了256位的向量寄存器并實(shí)現(xiàn)包括256位向量訪存在內(nèi)的向量擴(kuò)展指令。使用向量指令可以一次完成32個(gè)字節(jié)寬度數(shù)據(jù)的操作。而這樣的結(jié)構(gòu)和指令集設(shè)計(jì),使得龍芯3B非常適合于實(shí)現(xiàn)大規(guī)模相同類型數(shù)據(jù)的相同運(yùn)算,比如矩陣乘法運(yùn)算和FFT運(yùn)算,以及視頻編/解碼運(yùn)算等。
不過由于ffmpeg并未實(shí)現(xiàn)對龍芯3B平臺的支持,因而需要完成ffmpeg到龍芯3B的移植工作。本文之前也有一些ffmpeg到其他平臺的移植工作和針對龍芯平臺的移植與優(yōu)化工作,都取得了不錯(cuò)效果。
2 基于龍芯3B的ffmpeg移植
2.1 ffmpeg的移植
ffmpeg解碼器提供了對不同目標(biāo)平臺的支持,而與這些平臺相關(guān)的文件都保存在以該目標(biāo)平臺命名的目錄下。例如,ffmpeg解碼器實(shí)現(xiàn)了對arm和sparc平臺,以及x86平臺的支持。
對于實(shí)現(xiàn)ffmpeg解碼器對龍芯3B的支持,主要完成以下5個(gè)步驟:
(1)修改configure配置文件,增加與龍芯體系結(jié)構(gòu)相關(guān)的配置選項(xiàng);
(2)新建龍芯專用文件夾godson,將龍芯體系結(jié)構(gòu)相關(guān)的文件都存放于該文件夾中;
(3)將godson文件夾下新增的需要編譯的文件添加到Makefile中;
(4)增加與dsputil_init類似的新的初始化函數(shù)dsputil_init_godson;
(5)在頭文件中添加新增函數(shù)的聲明。
針對龍芯3B的ffmpeg移植工作相對比較簡單,因而本文重點(diǎn)介紹針對龍芯3B的向量化工作。
2.2 移植后的ffmpeg的性能比較
本節(jié)對移植后的ffmpeg解碼器進(jìn)行了性能測試,對使用龍芯3B向量擴(kuò)展指令和不使用龍芯3B擴(kuò)展指令兩種情況下的性能進(jìn)行了比較。測試時(shí)使用支持龍芯3B擴(kuò)展指令集的GCC編譯器進(jìn)行編譯,并且開啟-ftree-vectorize和-march=godson3b編譯選項(xiàng)來支持龍芯 3B擴(kuò)展指令。使用的測試用例為視頻“walk_vag_640x480_qp26.264”,測試結(jié)果如表1所示。
從表1的測試結(jié)果中可以看出,使用龍芯3B的向量擴(kuò)展指令可以提高ffmpeg解碼器在龍芯3B上的性能,用來測試的視頻的解碼時(shí)間減少了約466s。盡管如此,由于GCC編譯器本身自動(dòng)向量化能力的限制,ffmpeg解碼器的性能提升還是比較有限的,因而針對龍芯3B的指令集對移植后的ffmpeg解碼器進(jìn)行向量化,就成為了進(jìn)一步提高性能的重要工作。

3 ffmpeg的向量化
3.1 ffmpeg的oprofile測試
使用oprofile對ffmpeg解碼視頻“問道武當(dāng)002.mkv”的過程進(jìn)行測試,測試結(jié)果如表2所示。表2列出了各個(gè)函數(shù)的調(diào)用過程以及運(yùn)行時(shí)間所占的比重。而針對ffmpeg解碼器進(jìn)行的向量化工作,則主要是針對oprofile測試結(jié)果中執(zhí)行時(shí)間較長、運(yùn)行比重較大的幾個(gè)函數(shù)的向量化。
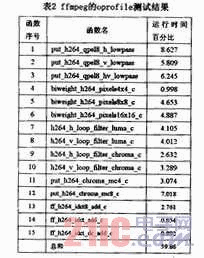
上述函數(shù)的執(zhí)行時(shí)間幾乎占據(jù)了ffmpeg解碼器執(zhí)行時(shí)間的60%,因而針對上述幾個(gè)函數(shù)進(jìn)行向量化,就完全可以達(dá)到提升ffmpeg整體解碼速度的目的。
3.2 針對龍芯3B的ffmpeg向量化
3.2.1 向量化方法
實(shí)現(xiàn)ffmpeg解碼器在龍芯3B上的向量化主要是使用龍芯3B擴(kuò)展的向量指令來改進(jìn)3.1節(jié)中oprofile測試結(jié)果中執(zhí)行時(shí)間比重較大的幾個(gè)函數(shù)。而且在向量化的同時(shí),同樣可以使用一些優(yōu)化策略,來提高向量化后的函數(shù)的性能。主要使用到的優(yōu)化方法包括:
(1)循環(huán)展開。循環(huán)展開是一種循環(huán)變換技術(shù),將循環(huán)體中的指令復(fù)制多份,增加循環(huán)體中的代碼量,減少循環(huán)的重復(fù)次數(shù)。需要說明的是,循環(huán)展開本身并不能直接提升程序的性能。
使用循環(huán)展開的主要目的是充分挖掘指令或者數(shù)據(jù)間的并行性。其中向量擴(kuò)展指令的使用就是利用了展開后的循環(huán)體內(nèi)數(shù)據(jù)的并行性;而在展開后的循環(huán)內(nèi)使用指令調(diào)度和軟件流水技術(shù)則是為了充分利用指令間的并行性。
(2)指令調(diào)度。循環(huán)展開后的循環(huán)體內(nèi)的指令數(shù)目增多,因而可以進(jìn)行指令調(diào)度,將不存在操作數(shù)相關(guān)性和不存在運(yùn)算部件相關(guān)性的指令調(diào)度到一起,這樣可以充分發(fā)揮龍芯3B的流水線性能,從而提高代碼在龍芯3B上的執(zhí)行速度。
除了使用龍芯3B的向量擴(kuò)展指令和使用上述兩種優(yōu)化方法以外,同樣還可以根據(jù)具體函數(shù)的特點(diǎn),使用其他一些優(yōu)化方法進(jìn)行優(yōu)化,比如使用邏輯運(yùn)算和移位運(yùn)算來代替乘法運(yùn)算等。針對每個(gè)函數(shù)的向量化優(yōu)化在3.2.2小節(jié)中介紹。
3.2.2 針對具體函數(shù)的向量化
3.2.1小節(jié)概述了向量化時(shí)用到的一些優(yōu)化方法,本節(jié)則針對oprofile測試中比重較大的幾個(gè)函數(shù)進(jìn)行有針對性的優(yōu)化。
對于表2中的函數(shù),我們可以根據(jù)函數(shù)名將其分類,函數(shù)命名類似的函數(shù)基本上都可以使用類似的優(yōu)化方法。
(1)簡單向量化。對于1號和2號函數(shù)的優(yōu)化,本文都采用了使用移位運(yùn)算來代替乘法運(yùn)算的策略,并且針對循環(huán)內(nèi)部運(yùn)算的有界特性,使用飽和向量運(yùn)算來改進(jìn)。不過對于2號函數(shù)的訪存操作,由于存在著數(shù)據(jù)非對齊的情況,因而使用額外的向量指令對數(shù)據(jù)進(jìn)行打包和回寫。而3號函數(shù)則是1號和2號函數(shù)的混合,因而對1號和2號函數(shù)的優(yōu)化間接提升了3號函數(shù)的性能。
而對于4號、5號和6號函數(shù),本文僅對其內(nèi)層循環(huán)使用了循環(huán)展開和指令調(diào)度策略,就能夠取得不錯(cuò)的運(yùn)算效果。
同樣,對于11和12號函數(shù)也可以比較直觀的進(jìn)行向量化,在此就不做詳述了。
(2)間接向量化。而對于比較難于向量化的7號和8號函數(shù),本文分別采用了使用掩碼和使用矩陣轉(zhuǎn)置運(yùn)算的策略來間接實(shí)現(xiàn)向量化。
其中針對函數(shù)h264 v loop filter luma的C語言實(shí)現(xiàn)中有很多判斷語句的問題,本文使用構(gòu)建掩碼的方式來消除這些判斷語句。

以圖1(a)中的循環(huán)為例介紹掩碼的構(gòu)建。而圖1(b)所示為代替該循環(huán)的向量指令。具體的運(yùn)算結(jié)果如圖1(c)所示:將p向量(數(shù)組)和q向量做飽和減法(結(jié)果為負(fù)的都置為0),得到的結(jié)果向量如Vsub所示。使用Vsub與零向量進(jìn)行比較來設(shè)置掩碼:結(jié)果為真,掩碼值為0xFF;反之,結(jié)果為假,掩碼為0。最后將掩碼值與p向量進(jìn)行與操作,就可以得到該循環(huán)的運(yùn)算結(jié)果。
使用構(gòu)建掩碼的方法來消除判斷語句,不但減少了由判斷引起的時(shí)間開銷,而且重要的是間接將循環(huán)進(jìn)行了向量化,提高了函數(shù)性能。而對于9號和10號函數(shù),可以使用同樣的方法來改進(jìn)。
而對于8號函數(shù),由于運(yùn)算處理的是連續(xù)的數(shù)據(jù),因而無法進(jìn)行向量化。使用矩陣轉(zhuǎn)置的方式,將數(shù)據(jù)重新打包后,就可以進(jìn)行相應(yīng)的向量運(yùn)算。

對于圖2(a)中的運(yùn)算,原始計(jì)算是P向量內(nèi)部的運(yùn)算,因而無法向量化,我們用向量指令將p向量轉(zhuǎn)置為q,其中q0存放p中標(biāo)號為1的數(shù)據(jù),q1存放P中標(biāo)號為2的數(shù)據(jù),依此類推。轉(zhuǎn)置得到的q向量就可以用圖2(b)中的向量指令運(yùn)算,得到的運(yùn)算結(jié)果與原來的運(yùn)算相同。
對于13~15號函數(shù)的優(yōu)化,同樣使用到了上面的轉(zhuǎn)置方法。而4.1節(jié)的測試結(jié)果則說明了各個(gè)函數(shù)的優(yōu)化效果。
4 實(shí)驗(yàn)結(jié)果
4.1 ffmpeg各函數(shù)加速比
本文分別對向量化后的各個(gè)函數(shù)進(jìn)行了測試,并且與未向量化之前的函數(shù)進(jìn)行了比較,各個(gè)函數(shù)向量化優(yōu)化后的加速比如圖3所示。其中圖中橫坐標(biāo)所示函數(shù)序號與表2中的各個(gè)函數(shù)一一對應(yīng)。
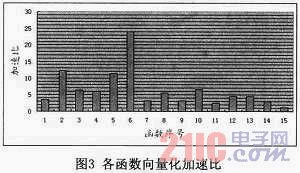
圖3中的函數(shù)的加速比所跨越的范圍較大,比如6號函數(shù)的加速比約有23.9左右,而最后一個(gè)函數(shù)的加速比只有1.2左右。之所以會(huì)出現(xiàn)上述情況,除了與改進(jìn)后的函數(shù)所使用的向量指令的數(shù)量和修改代碼的比重有關(guān)以外,也與運(yùn)算所使用的操作數(shù)的類型有關(guān)。對于6號函數(shù),其循環(huán)內(nèi)的運(yùn)算所使用的操作數(shù)的類型為字節(jié)類型,因而僅僅使用向量指令進(jìn)行優(yōu)化,理論加速比就可以達(dá)到32,不過本文僅僅對該函數(shù)的內(nèi)層循環(huán)進(jìn)行了向量化,而向量化后的內(nèi)層循環(huán)一次僅僅處理了 16個(gè)字節(jié)類型的數(shù)據(jù),即并未充分使用256位的向量寄存器。因而理論的加速比應(yīng)該為16,但是由于結(jié)合了循環(huán)展開和指令調(diào)度等其他優(yōu)化策略,因而實(shí)際的加速比可以達(dá)到23.9左右。同樣,對4號、5號和6號這三個(gè)同類型的函數(shù)進(jìn)行分析,我們也可以發(fā)現(xiàn):后一個(gè)函數(shù)的加速比均約為前一個(gè)函數(shù)加速比的兩倍。這是因?yàn)閷τ?號函數(shù),內(nèi)層循環(huán)向量化后一次可以同時(shí)計(jì)算4個(gè)字節(jié)類型的數(shù)據(jù),而5號函數(shù)可以同時(shí)計(jì)算8個(gè)字節(jié)類型的數(shù)據(jù),因而理論上的加速比也應(yīng)該是兩倍的等比數(shù)列形式,而實(shí)際結(jié)果與理論分析是一致的。
對于3.3.2小節(jié)中重點(diǎn)介紹的7號函數(shù)和8號函數(shù),其原函數(shù)無法進(jìn)行簡單向量化,而本文使用了掩碼以及矩陣轉(zhuǎn)置等優(yōu)化方法,使其能夠使用龍芯3B的向量擴(kuò)展指令,因而盡管性能提升不大,但是加速比也分別有3.2和5.5。
4.2 不同平臺上的向量化比較
本文同樣將ffmpeg解碼器分別在不同的平臺上進(jìn)行了測試,使用的兩個(gè)測試視頻分別為是“問道武當(dāng)002.mkv”(視頻A)和“walk_vag_ 640x480_qp26.264”(視頻B)。其中視頻A是問道武當(dāng)視頻(720p)中截取的片段,而后者是通過x264對walk_vag.yuv(480p)編碼生成的,編碼時(shí)選用的qp值為26。而測試平臺則分別選擇了AMD和Intel處理器平臺。

從表3的測試結(jié)果可以看出對于視頻A,在龍芯3B上的性能提升比其他兩個(gè)平臺上都高很多;而對于視頻B,在龍芯3B上的性能提升也與其它兩個(gè)平臺接近。實(shí)驗(yàn)結(jié)果表明:在龍芯3B上實(shí)現(xiàn)ffmpeg解碼器的向量化,對性能提升有很大幫助,而且解碼某些視頻時(shí),性能的提升甚至高于性能優(yōu)越的商用處理器。而通過與表1中使用GCC向量化編譯的結(jié)果進(jìn)行比較,也可以看出:手工對ffmpeg解碼器進(jìn)行向量化比使用GCC進(jìn)行向量化,性能有更大的提升。
5 總結(jié)和展望
本文實(shí)現(xiàn)了ffmpeg解碼器到龍芯3B的移植,并針對龍芯3B實(shí)現(xiàn)了對向量擴(kuò)展指令支持的特點(diǎn),對ffmpeg解碼器進(jìn)行了手工向量化。實(shí)驗(yàn)結(jié)果表明:手工向量化后的ffmpeg解碼器的性能比使用GCC向量化編譯后的ffmpeg解碼器性能要好很多,而且性能的提升也比Intel和 AMD平臺更多。
本文僅僅從代碼級實(shí)現(xiàn)了針對龍芯3B的ffmpeg解碼器的向量化移植,為了進(jìn)一步提高性能,還需要從整個(gè)算法層面上進(jìn)行優(yōu)化。另外,由于龍芯3B的多核特性,還可以考慮使用多核進(jìn)行解碼。