
摘 要: 在分析傳統(tǒng)的網(wǎng)絡(luò)蜘蛛搜索特點的基礎(chǔ)上,充分利用Web資源分布的特點,提出了基于在線增量自適應算法的搜索策略。該算法一方面避免了過早陷入Web搜索最優(yōu)子空間的陷阱;另一方面不斷對爬蟲數(shù)據(jù)庫更新,以提高其對鏈接主題的判斷能力。通過對四所著名大學計算機網(wǎng)站做的搜索實驗,表明新的算法可以有效地提高網(wǎng)絡(luò)蜘蛛的搜索性能。
關(guān)鍵詞: 網(wǎng)絡(luò)蜘蛛;搜索策略;在線增量自適應
隨著Internet的快速發(fā)展,Web上的信息資源也呈指數(shù)級增長,搜索引擎已經(jīng)成為網(wǎng)絡(luò)用戶獲取各種信息的必備工具。對于搜索引擎來說,要抓取互聯(lián)網(wǎng)上的所有信息幾乎是不可能的,從公布的數(shù)據(jù)來看,容量最大的搜索引擎也只不過是抓取了整個網(wǎng)絡(luò)信息的40%左右。傳統(tǒng)的搜索引擎(如Google、Baidu、Yahoo等)大多數(shù)都是面向所有信息的搜索引擎,是一種通用搜索引擎。這種通用搜索引擎已經(jīng)不能滿足特定用戶更深入的查詢需求,他們對信息的需求往往是面對特定領(lǐng)域和特定主題的。面對挑戰(zhàn),適應特定人群需要的專業(yè)搜索引擎逐漸引起研究學者的重視。
主題網(wǎng)絡(luò)蜘蛛是最近幾年興起的研究熱點,它針對某個專門的領(lǐng)域進行搜索,以滿足特定人群的個性化需求。網(wǎng)絡(luò)蜘蛛研究的核心是解決頁面和URL的主題相關(guān)性判別的問題,因此如何評價鏈接價值就成了網(wǎng)絡(luò)蜘蛛爬進效率的關(guān)鍵。鏈接價值可以分為兩類,即基于立即回報價值和基于未來回報價值。
立即回報價值算法是依據(jù)搜索時在線獲得的文本或Web結(jié)構(gòu)來對鏈接的頁面重要程度進行預測,進而決定鏈接訪問順序。這類方法理論基礎(chǔ)好,計算簡單,在距離相關(guān)頁面比較近的時候表現(xiàn)出良好的性能。但它很難反映Web的整體情況,網(wǎng)絡(luò)蜘蛛在距離相關(guān)頁面比較遠的時候容易迷失方向。基于未來價值的算法利用Web上的信息分布在某種程度的相似性,對網(wǎng)絡(luò)蜘蛛先進行訓練,使其具有一些經(jīng)驗信息,對未來搜索具有一定的預測性。但其預測能力有限,而且需要用戶選擇種子集,搜索時不靈活,容易引起主題漂移[1-4]。
本文基于兩類評價方法,提出了一種在線學習的自適應綜合價值的網(wǎng)絡(luò)蜘蛛搜索算法,利用Web資源分布的某些相似性和鏈接價值的關(guān)系,將立即價值和未來價值的評價方法相結(jié)合,在爬行過程中不斷自身提高鏈接主題相關(guān)性的判斷能力,從而改進網(wǎng)絡(luò)蜘蛛的性能。
1 主題爬行策略
根據(jù)評價鏈接價值所采用的不同方法,現(xiàn)有的網(wǎng)絡(luò)蜘蛛的搜索策略分為兩大類:基于立即回報價值評價的搜索策略和基于未來回報價值的搜索策略。本文采用基于內(nèi)容評價的策略(基于立即價值)和基于鞏固學習的搜索策略(基于未來價值)。
基于內(nèi)容評價的搜索策略,主要是根據(jù)主題與鏈接文本“語義”的相似度來評價鏈接價值的高低。鏈接文本是指周圍的說明文字和和鏈接URLs上的文字信息。相似度的評價一般采用下面的公式:
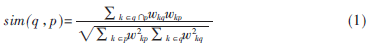
其中,q代表主題關(guān)鍵詞集合,p代表頁面鏈接文本集合,Wkp代表d中單詞對某一主題的重要程度,Wkp通常采用tf×idf公式計算。
基于鞏固學習的搜索策略,鞏固學習的優(yōu)勢在于能預測遠期的回報價值(也稱未來價值)。未來價值用Q來表示,這種方法的核心就是如何計算鏈接的Q價值。為此,搜索過程被分為訓練和搜索兩個階段。訓練階段用鞏固學習算法計算每個鏈接的Q價值,按價值的大小分為若干類,并用每一類中的文本信息訓練一個Naive Bayes分類器;在搜索階段,面對價值未知的鏈接,則根據(jù)鏈接文本,用Naive Bayes分類器計算鏈接落在每一類中的概率,并以這個概率為權(quán)值來計算鏈接的Q價值。因為Q價值反映的是未來的回報預測值,所以當搜索的頁面與主題不相關(guān)時,網(wǎng)路蜘蛛也可以根據(jù)未來回報的預測值來確定正確的搜索方向。
該模型的核心就是如何計算鏈接的Q價值。Q價值的計算公式[5]:

2 在線增量自適應算法網(wǎng)絡(luò)蜘蛛搜索策略
2.1 Web資源分布和鏈接價值的關(guān)系
雖然整個網(wǎng)絡(luò)資源的分布是無序的,但近年來的研究表明,與某一主題相關(guān)的頁面以不同群聚群體的方式分散在網(wǎng)絡(luò)中,把這些群體稱為Web社區(qū)[6]。圖1中顯示了這種Web社區(qū)的分布關(guān)系。在網(wǎng)頁的設(shè)計過程中不可能把所有相關(guān)的網(wǎng)頁鏈接在一起,網(wǎng)頁中只包含了極少部分與該主題相關(guān)的網(wǎng)頁鏈接,這些資源信息一起構(gòu)成了一個與某一主題相關(guān)的Web社區(qū)。在某一站點附近有很多緊密聯(lián)系的站點,它們都能基本地反映某個主題。但在網(wǎng)頁的發(fā)布過程中,可能會出現(xiàn)與之有一定關(guān)聯(lián)但又與主題不相關(guān)的無關(guān)網(wǎng)頁,這些無關(guān)網(wǎng)頁在網(wǎng)絡(luò)蜘蛛的爬行過程中會導致中心主題發(fā)生漂移。正是由于這些無關(guān)網(wǎng)頁的“干擾”,使得網(wǎng)絡(luò)蜘蛛在爬行的過程中隨著時間的推移,爬行出來的鏈接會與最初鏈接的主題相關(guān)性差別越來越大,系統(tǒng)爬行到的網(wǎng)頁也越來越少。這就要求在網(wǎng)絡(luò)蜘蛛的爬行過程中,一方面能盡可能地覆蓋所有相關(guān)網(wǎng)頁;另一方面又要在爬行的過程中不斷“更新”,以提高主題相關(guān)性的判斷能力。這就要求網(wǎng)絡(luò)蜘蛛在不同的階段采用不同的搜索策略,同時不斷“自我更新”,以提高爬行的效率和精度。

2.2 算法思想
根據(jù)Web資源的分布信息,本文把網(wǎng)絡(luò)蜘蛛爬行的過程人為地分為兩個階段:挖掘和探索。在Web社區(qū)內(nèi),由于和主題相關(guān)的網(wǎng)頁比較多,立即價值比較大,這個時候就要求能盡快地挖掘Web社區(qū)內(nèi)與主題相關(guān)的網(wǎng)頁信息。這個時候適合選取注重發(fā)掘立即價值的搜索策略。而在Web社區(qū)之間,由于存在大量與主題無關(guān)的網(wǎng)頁,這個時候要注重探索,盡可能地探索到與主題相關(guān)的Web社區(qū)。但這個時候鏈接的立即價值會很小,適合選取基于未來價值的搜索策略,本文采用基于鞏固學習的搜索策略。同時為減少網(wǎng)絡(luò)蜘蛛在爬行過程中的主題漂移,提高主題相關(guān)性的判斷能力,在每爬完N個Web社區(qū)后(本文用爬行一個固定時間段來表示),系統(tǒng)選取爬蟲數(shù)據(jù)庫中爬行到的與主題相關(guān)度高前100名的頁面,與其對應的正向鏈接信息組成的實例加入鏈接分類器的訓練數(shù)據(jù)。鏈接分類器一旦訓練完成,就可以對新產(chǎn)生的鏈接進行相關(guān)度分析。自身通過爬蟲數(shù)據(jù)庫新進的主題相關(guān)度高的頁面和頁面正向鏈接信息不斷修正,提高主題相關(guān)性的判斷能力。
2.3 在線增量自適應算法的設(shè)計和實現(xiàn)
在線增量自適應算法的本質(zhì)是:通過網(wǎng)路蜘蛛的爬行,在Web社區(qū)內(nèi)盡可能地挖掘和主題相關(guān)的頁面,而在社區(qū)外獲取那些具有較高的未來Q價值的鏈接。反過來,在搜索時又根據(jù)鏈接文本的Q價值估算出鏈接的價值,決定選擇行動的概率。同時,不斷通過爬蟲數(shù)據(jù)庫新進的主題相關(guān)度高的頁面和頁面的正向鏈接信息修正,提高鏈接主題相關(guān)性判斷能力。本文利用Java技術(shù),算法實現(xiàn)過程如下:
ZX-ZL(topic,startUrls){
Link_1=fetch link(startUrls);
While(visited<MAX_PAGES){
//小于爬蟲最大訪問量
score_r1=sim(topic, doc); //計算立即價值
If(socre_r1>r1)
enqueue_1(frontier,extract_links(doc),score_1);
else{
score_r2=Q(topic, doc); //計算未來價值
if(score_2>r2)
continue;
else
enqueue_2(links);
}
}
}
2.4 算法過程描述
(1)網(wǎng)絡(luò)蜘蛛首先從一個“種子集”出發(fā),并選擇其中的一個鏈接訪問。
(2)按照式(1)計算鏈接節(jié)點的立即價值。
(3)判斷所得的立即價值是否大于系統(tǒng)給定的閾值r1,如果大于給定閾值,則將該鏈接加入到候選URL列表里。如果小于給定的閾值r1,就利用式(2)計算此鏈接的未來價值。
(4)如果經(jīng)計算所得未來價值大于系統(tǒng)給定的閾值r2,系統(tǒng)就并發(fā)另一個線程從此節(jié)點開始,返回步驟(2)。
(5)如果所得的未來價值小于給定的閾值r2,將該鏈接列入被舍棄的URL列表里。結(jié)束此線程。
另外每隔T的時間后,手動選擇與主題相關(guān)度高前100的頁面加入鏈接分析器進行訓練,對爬蟲數(shù)據(jù)庫進行更新[7]。
3 實驗與結(jié)果分析
3.1 實驗背景
本文選取了如表1所示的美國四所大學的計算機網(wǎng)站做了實際的搜索實驗,搜索目的是尋找本地服務器中的計算機論文,以PDF和.PS結(jié)尾的計算機論文定義為相關(guān)文檔。采用基于立即價值、未來價值和基于本文所描述的在線增量學習的自適應算法三種不同搜索策略的網(wǎng)絡(luò)蜘蛛,在線統(tǒng)計Web上與計算機相關(guān)的論文數(shù),并計算各自的查全率和查準率。本文采用FOLDOC在線計算機字典作為主題關(guān)鍵字集合[8]。其中包括13 000個計算機專業(yè)詞匯,并進行了一些擴充。從站點的主頁出發(fā),對上述四所大學Web服務器進行了實際的搜索測試,共找到了15 034篇與計算機相關(guān)的論文。

3.2 實驗結(jié)果和性能分析
圖2中,三種不同搜索策略在不同階段的查全率不同。其原因在于,基于立即價值的搜索策略在相關(guān)社區(qū)中的搜索率很高,可以很快地找到相關(guān)網(wǎng)頁,所以其增長率很快。但在找無關(guān)網(wǎng)頁集合時容易迷失方向,從一個Web社區(qū)搜索完畢后進入另一個Web社區(qū)的能力較弱,查全率會降低;基于未來價值的搜索策略,在尋找無關(guān)頁面集合中,未來價值對預見遠期回報很有幫助,它可以很快地找到論文的目錄所在,但早期的回報率不高;基于在線增量自適應算法采用綜合的搜索策略,除在搜索初期其回報略低于基于立即價值的網(wǎng)絡(luò)蜘蛛外,其增長率很快超過兩種算法。不論是在社區(qū)內(nèi)的搜索還是過度無關(guān)網(wǎng)頁來獲取遠期回報,它都表現(xiàn)出了優(yōu)異的性能。

圖3中基于在線增量自適應算法的網(wǎng)絡(luò)蜘蛛查準率顯然高于其他兩種。除了最初的階段外,其余時間的查準率都高于50%。其原因在于每隔一定的時間,爬蟲數(shù)據(jù)庫不斷自我更新,提高主題相關(guān)性的判斷能力。在Web社區(qū)外,在一定程度上避免了采集大量的無關(guān)文檔;在主題相關(guān)的Web社區(qū)內(nèi)又提高了其搜索能力,因此其查準率很高。而基于立即價值的網(wǎng)絡(luò)蜘蛛在跨越Web社區(qū)時常常會發(fā)生主題偏移,容易導致局部最優(yōu)。基于未來價值的網(wǎng)絡(luò)蜘蛛在跨越Web社區(qū)時采集了大量與主題無關(guān)的文檔,同時在主題相關(guān)社區(qū)內(nèi)的搜索能力又比較低,因此查準率不高。

本文將基于改進的鞏固學習方法的行動策略的在線增量自適應算法引入搜索引擎中,避免了過早陷入Web搜索局部最優(yōu)子空間的陷阱。同時,不斷更新爬蟲數(shù)據(jù)庫,提高了其對主題相關(guān)性的判斷能力,從而提高了搜索引擎的查準率。實驗表明,該算法的查全率不但大大高于兩種傳統(tǒng)的單一算法,同時也整體提高了搜索引擎的性能。
參考文獻
[1] MURRAY B H, MOORE A. Sizing the internet[M]. A White Paper: Cyveillance, Inc. 2000.
[2] LAWRENCE S, GILES L. Accessibility and distribution of information on the Web[J]. Nature, 1999, 400(8): 107-109.
[3] BREWINGTON B E, CYBENK G. How dynamic is the Web[J]. Computer Networks, 2000, 33(1-6). 257-276.
[4] ESTER M, GROB M, KRIEGEL H. Focused Web crawling: a generic framework for specifying the user interest and for adaptive crawling strategies[Z]. Proceeding of the International Conference on Very Large Database (VLDB’01), 2001.
[5] 陳治平.智能搜索引擎理論與應用研究[D].長沙:湖南大學,2003.
[6] 傅向華,馮博琴,馬兆豐,等.可在線增量自學習的聚焦爬行方法[J].西安交通大學學報,2004,38(6):599-602.
[7] HOWE D. Free on-line dictionary of computer[WZ]. http: //www. foldoc. org/. 2010.
[8] CHO J, GARCIA-M H, PAGE L. Efficient crawling through URL ordering[J]. Computer Networks, 1998, 30(1-7): 161-172.