
自動指紋識別系統(tǒng)
指紋識別是自動個人識別技術中使用的最常見,、最可靠的技術。大體上,,實現(xiàn)的技術將自動指紋識別(AFAS) 劃分為在不同時間和不同條件下執(zhí)行的兩個階段:登記和識別,。
登記流程中,用戶向系統(tǒng)提供指紋,,系統(tǒng)隨即執(zhí)行一系列需要高強度計算的圖像處理步驟,,以提取所有具有相關性、永久性和獨特性的信息,,從而使系統(tǒng)明確識別指紋的真正主人。這一系列特性就構成了用戶ID(身份識別號碼),,由系統(tǒng)存儲在數(shù)據(jù)庫中,。這一過程一般在安全的環(huán)境中,在專業(yè)人員的指導下離線執(zhí)行,。
指紋識別是查看其是否與數(shù)據(jù)庫中的經認可的用戶一致,。在登記過程中執(zhí)行的各種處理工作將反復進行,以從當前指紋采樣本中提取出獨特的特征,。系統(tǒng)隨后將這些特征與數(shù)據(jù)庫中存儲作為為用戶模版的信息進行對比,,以確認當前指紋采樣是否與登記的模版相符。根據(jù)數(shù)據(jù)庫大小,,識別分為兩種模式:一對一或一對多匹配,。識別一般是在安全度較低的環(huán)境中,,且在實時約束的條件下完成的。
這里的每一步被細分為一系列彼此獨立的任務,,以從指紋圖像中抽取出用戶獨特的信息,。以此為目的,系統(tǒng)將進行一系列具體的運算,,如圖像處理(2D 卷積,、形態(tài)學運算)、三角運算(正弦,、余弦,、反切、開方)[1] 或者統(tǒng)計(平均值,、方差),。
因此,生物識別應用是由一系列按順序流程執(zhí)行的任務構成的,。因為在這個鏈條上某個給定任務的輸出數(shù)據(jù)是下一項任務的輸入數(shù)據(jù),,一項任務的開始需要等待前一項任務的完成。另外,,在登陸階段和識別階段,,有許多任務是反復執(zhí)行的。
圖1列舉了目前算法中發(fā)生的任務,。第一項是圖像獲取,。根據(jù)傳感器的尺寸,系統(tǒng)可以一次性地獲得整個圖像(全圖像傳感器),,也可以分片獲取(掃描傳感器),。在第二種情況下,即我們正在使用的這種情況,,需要額外經過一次圖像重構階段,。完整的指紋圖像是由連續(xù)且部分重疊的圖像條所組成的[2]。

我們獲得整個重構的圖像之后,,下一步是在背景中對前景(即指紋皮膚的凸凹形成的關注區(qū)域)分割,。我們采用由 5x5 像素的 Sobel邊緣檢測濾波器逐像素完成圖像卷積。完成后,,我們以特定的均值和方差進行圖像標準化,。
下一步,我們通過各向同性濾波來增強標準化圖像,。該步驟使用 13x13 像素,,從之前在采集階段因噪聲而導致圖像丟失或者干擾的圖像區(qū)域恢復相關信息[3]。圖像強化步驟完成之后的下一步是計算指紋矢量圖 (field orientation map),以確定圖像前景中脊線和谷線的主要方向,。生成的方向場 (eld orientation) 隨后被提交給新的濾波步驟(5x5像素),,以獲得精細化的矢量圖。
此時圖像仍為 8 位灰度,。在二值化處理中,,由 7x7 像素的 Gabor 方向濾波器進行灰度圖像卷積,以提升脊線和谷線的清晰度,,并把每個灰度像素轉化為 1 位二進制(黑或白)點,。合成的脊線和谷線圖像再次進行經過平滑處理和重繪。隨后,,通過細化或骨架化,,將黑白圖像的黑色走線變?yōu)橐粋€像素寬。從這個圖像上不難提取指紋的特性或者細節(jié),,即紋線端點和紋線分叉點,。
最后,在獲取到指紋細節(jié)和方向場數(shù)據(jù)后,,就可以進行指紋模板和樣本的對比,。這里采用一種比較直接的算法,在考慮到轉換和旋轉動作以及采集階段因皮膚彈性導致的圖像變形引起的誤差可接受的情況下,,讓兩者實現(xiàn)最理想的重合[4],。下一步是進行樣本和模板的匹配,獲知兩者之間的相似度,,隨后自動化系統(tǒng)可以根據(jù)相似度來確定兩個圖像是否屬于同一人[5],。
在如圖3所示的整個處理過程中,使用的指紋圖像分辨率為 500dpi,,灰度為 8 位,,圖像大小為 280x512 像素。圖像獲取采用的是Atmel公司的熱敏指紋傳感器 FingerChip 掃描技術,,運算采用的是賽靈思 Virtex-4 XC4VLX25 FPGA 器件,。
系統(tǒng)架構
Virtex-4 FPGA 器件是 AFAS 平臺的計算單元,其中采用 Flash(閃存)作為系統(tǒng)數(shù)據(jù)庫,,存儲FPGA配置數(shù)據(jù),,以及如用戶指紋模板或生物識別算法配置設置等特定于應用的數(shù)據(jù)。此外,,該系統(tǒng)還使用 DDR-SDM 存儲器來暫時保存從每個處理階段中獲得的中間數(shù)據(jù)或圖像,。我們采用的是串行通信,,在我們的案例中是連接至 UART 控制器的 RS-232 收發(fā)器 — 后者可在 FPGA 資源中進行綜合 — 以用于調試目的,。其目的是將每個階段生成的結果圖像傳輸?shù)?PC 上,以便以圖形化的方式察看每步的指紋圖像或者結果。最后,,使用掃描式指紋傳感器來獲取用戶的生物識別特性,,并作為識別算法的輸入,如圖 2 所示,。
作為計算單元,,F(xiàn)PGA 被劃分為兩個區(qū)域,一個是靜態(tài)區(qū),,由完整的多處理器 CoreConnect 總線系統(tǒng)構成;另一個是可重配置區(qū),,用于根據(jù)需要放置定制的生物識別協(xié)處理器或IP(知識產權),以執(zhí)行識別算法的各種順序任務,,并隨處理的進展進行復用,。多處理器 CoreConnect 總線系統(tǒng)主要由賽靈思 MicroBlaze 處理器及其它標準外設構成,同時還擁有一個鏈接至 ICAP (內部配置訪問通道)端口的重配置控制器,。
如圖1所示,,所有的處理任務都按照順序執(zhí)行的次序從 0(靜態(tài))到 B 進行枚舉。定制的硬件協(xié)處理器負責在 PRR (部分重配置區(qū)域)中實現(xiàn)所有的任務,,由 MicroBlaze 在軟件中完成的指紋采集過程除外,。
軟硬件特定的劃分是由于掃描傳感器需要 5μs的積分時間來獲得連續(xù)的圖像條(SLICE)。這種速度下無需采用定制的硬件協(xié)處理器,,采用MicroBlaze軟件采集和重構圖像不僅速度足夠,,而且更簡單經濟。
圖像采集按每個 SLICE 5μs的速率采集 100 個SLICE,,每個 SLICE 的大小為 280x8 像素,。每兩個連續(xù)的圖像 SLICE 之間的像素重疊部分交由軟件進行探測,從而完成圖像的實時重構,。
由于實時的要求,,剩余的任務我們交由 FPGA 的 PRR 的定制硬件協(xié)處理器來實現(xiàn)。一旦每個特定的任務完成之后,,位于器件靜態(tài)區(qū)的重配置控制器在 MicroBlaze 處理器的控制下,,載入下一個任務的工作模塊。重配置控制器通過 ICAP 接口將新模塊的配置數(shù)據(jù)從 DDR-SDM 中直接傳輸?shù)絻炔康?FPGA 配置存儲器中,,從而完成此項任務,。
值得一提的是,我們使用的是靜態(tài)區(qū)和可重配置區(qū)之間基于 FIFO(先進先出)存儲器和觸發(fā)寄存器構成的標準界面,。這樣我們就可以在 PRR 中開發(fā)標準的生物識別協(xié)處理器或 IP,,而無需理會系統(tǒng)使用的是哪種多處理器總線,無論其是 AMBA,、CoreConnect,、Wishbone 還是其它均如此,,如圖 2 所示。這一點具有根本性的意義,,因為這樣才能確保生物識別算法跨不同平臺的標準化和便攜性,。

重配置控制器
設計高效的重配置控制器是部署面向單一環(huán)境 FPGA 的 PR (部分重配置)系統(tǒng)的成功關鍵。雖然在重配置 PRR 期間,,F(xiàn)PGA 的非重配置區(qū)域仍然處于工作狀態(tài),,但 PRR 資源此時并沒有處于工作狀態(tài),故應盡量加快重配置過程,,以便最大限度地降低開銷,。重配置的時間取決于三個因素:數(shù)據(jù)總線寬度、重配置頻率以及比特流大小,。前兩個因素與接口特性有關,,而最后一個與 PRR 的大小及其中的部分重配置模塊 (PRM) 的設計復雜程度有關。
我們的工作實現(xiàn)了一個重配置控制器,,其能在運行時將部分比特流以高帶寬從外部存儲器傳輸?shù)?FPGA 的片上配置存儲器中,。在不限制部分比特流大小,同時將外部存儲作為共享資源(各種處理器可通過系統(tǒng)總線同時訪問)的條件下,,仍然可以達到Virtex-4最高重配置帶寬,。
在系統(tǒng)初始化階段,部分比特流將在運行中被下載到 FPGA 配置存儲中,,并從外部的Flash中傳輸?shù)酵獠?DDR-SDRAM,。該存儲器與多端口存儲控制器 (MPMC) 相連接,因而成為系統(tǒng)中任何主從處理器都可以訪問的資源,??梢允褂?CoreConnect PLBv46 總線等不同類型的總線連接到 MPMC,這些總線可用作通用系統(tǒng)總線,,而賽靈思 Cachelink (XCL) 總線則用于 CPU 的快速指令和數(shù)據(jù)緩存,。系統(tǒng) CPU (MicroBlaze) 實際上是與這兩個總線相連接的。
不過我們的重配置解決方案是建立在新總線基礎之上的,,即專用于快速鏈接外部 DDR-SDRAM 存儲庫和 ICAP 接口之間的原始端口界面 (NPI),。作為我們重配置控制器的組成部分,我們設計了可用來處理 NPI 協(xié)議的主系統(tǒng)存儲管理單元 (MMU),。外部 DDR-SDRAM(部分比特流)和 ICAP 原始之間的連接需要經過一個內部 FIFO 存儲器,。借助這種方法,我們可以實現(xiàn)兩個不同的定制界面,,它們各自擁有獨立的數(shù)據(jù)總線大小和速度,,一個與 NPI 協(xié)議耦合,另一個則與 ICAP 協(xié)議進行耦合,。
FIFO 的寫入端口與 NPI 相連接,,并使用 64 位數(shù)據(jù)總線;而 FIFO 的讀取端口則連接到 ICAP,,使用 32 位數(shù)據(jù)寬度,這是 ICAP 在 Virtex-4 器件中的最高數(shù)據(jù)寬度,。FIFO 的讀取端口和寫入端口(在 NPI 側和 ICAP 側)的運行頻率為 100MHz。為使傳輸時延降至最低,,主系統(tǒng) MMU 負責以 64 字(32 位)突發(fā)傳輸向內部 FIFO 傳輸配置數(shù)據(jù),,從而完成模塊的重配置。這是可接受的最大突發(fā)長度,,因而所有的重配置數(shù)據(jù)傳輸都能夠以最低突發(fā)時延完成,。在另一側,只要 FIFO 不為空,,重配置控制器就能讀取已存儲的 FIFO 數(shù)據(jù),,并將其以 32 位格式傳輸給 ICAP 接口。重配置控制器(就是主 MMU)負責處理對大型 DDR-SDM 存儲器進行直接存儲器存取 (DMA),。為了實現(xiàn),,我們定制了一個從MMU,并在其中設置了多個控制寄存器,,將這個MMU掛在PLBv46總線上并由CPU直接控制,。
采用這種方式,CPU 僅需做兩件事情:配置在 PRR 中下載的部分比特流的初始地址和大小;向主系統(tǒng) MMU 發(fā)出執(zhí)行指令,,以啟動重配置過程,。而后,主系統(tǒng) MMU 開始將比特流以 DMA(直接內存存儲)的方式直接傳輸給內部的 FIFO,,隨后再從該 FIFO 傳輸給 ICAP 接口,。一旦傳輸完畢,重配置控制器就會通知 CPU,。
結果,,即使在 CPU 通過 XCL 或 PLBv46 總線訪問 DDR-SDRAM 的同時,我們也能實現(xiàn)部分比特流傳輸?shù)淖畲笸掏铝?。其最終原因在于 CPU 在內部 BM(block-M)高速緩存中運行程序流,,將對外部 DDS-SDRAM 的訪問釋放給了重配置控制器。值得重點指出的是,,這個為部分比特流和軟件應用分配的 DDR-SDRAM 存儲器并非專用資源,,而是共享資源。即使如此,,該方案與其它現(xiàn)有的重配置控制器方案相比性能也有顯著的改善,,因為其能夠實現(xiàn) Virtex-4的最大重配置吞吐量(通過 32 位數(shù)據(jù)總線以 100MHz 的頻率或 3.2 Gbps 的速率將部分比特流傳輸給 ICAP)。
實驗結果
從本質上講,,文中所述的嵌入式自動指紋識別系統(tǒng)是一種高性能圖像處理應用,,因為它擁有大量的并行性,,且需要實時認證響應。從人機工程角度上講,,此系統(tǒng)可使每位用戶的認證時間不超過 2 s或3s,。
該設計流程涉及多個開發(fā)環(huán)路。首先,,我們在 PC 平臺上的 MATLAB 的軟件里開發(fā)算法,。隨后,我們將軟件代碼用 C 編程語言導入到嵌入式軟件中,,并且首先在同一 PC 上執(zhí)行,,以確認我們能夠獲得同樣的結果,然后在 FPGA 器件內合成的 MicroBlaze 嵌入式微處理器上執(zhí)行,。
通過這種方式,,Virtex-4 器件可在不使用任何定制硬件協(xié)處理器和不達到實時性能要求的情況下實施基于 MicroBlaze 的純軟件解決方案。為縮短運行時間,,我們根據(jù)任務概要,,下一步工作是引入 PRR,并在上面構建各種定制生物識別協(xié)處理器,,使用硬件/軟件協(xié)同設計解決方案,。此刻,我們已經采用 C 編程語言和 VHDL 硬件描述語言完成了此系統(tǒng)的開發(fā)工作,。
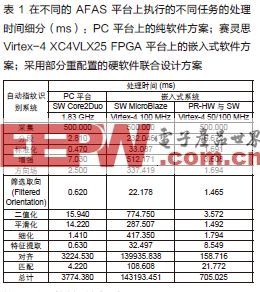
我們采用 268x460 像素的 8 位灰度指紋圖像進行了一些識別測試,。同時,我們在基于 Virtex-4 的 PR 系統(tǒng)上和運行速度為 1.83GHz 的 Intel Core 2 Duo T5600 處理器的個人電腦上也進行了相同的測試,。然后,,我們運行相同的算法,包括純軟件實施方式和軟硬件混合實施方式,,以比較登錄和識別階段的性能,。
如果不考慮采集工作(由于掃描傳感器的性能限制,需以 5ms 積分時間采集 100 片并在運行中重構圖像,,故采集時間固定為 500ms),,PR 方法可以把運行其他處理任務所形成的延遲降低到 205ms。與在 PC 上運行純軟件方法的 3,274ms 的延遲相比,,PR 方法可提高 16 倍速度,。
因此,表 1 說明運用并行和流水線技術進行軟硬件協(xié)同設計,,同時配合低重配置延遲的 PR 技術,,明顯實現(xiàn)實時認證是可行的。另外,,在動態(tài)重配置時,,可以指定模塊運行的頻率,,這個頻率是由新模塊的特性所決定。在我們的設計中,,所有模塊運行在50MHz或者100MHz的頻率下,。
此外,重配置流程一直以 100MHz 運行,,在每個時鐘周期里傳輸 32 位比特,,從而保證 Virtex-4 上的最低重配置延遲。根據(jù)每個 PRR 硬件環(huán)境的比特流復雜性,,每個重配置流程花費的時間在 0.8ms(例如標準化)和 1.1ms(例如二進制化)之間。與生物識別應用的總體運行時間相比,,該重配置時間可忽略不計,。
由于我們已經成功完成了概念驗證工作,我們準備把原型導出到新一代賽靈思低端具有 PR 功能的 28 納米FPGA 器件中(Artix-7 系列),。我們的目標是以最低的成本設計出一款能夠在任何消費類電子產品中嵌入高性能且真正安全的生物識別系統(tǒng),。