
引言
說話人識別又稱聲紋識別,是通過說話人的聲音特征進行身份認證的一種生物特征識別技術(shù),。說話人識別經(jīng)過60多年的研究,,已經(jīng)逐步應(yīng)用到法律、銀行等各個領(lǐng)域,。說話人識別通過對語音信號進行處理,,提取說話人語音當(dāng)中的生物學(xué)個性特征,在特征空間建立不同個體的特征模型,,從而實現(xiàn)說話人的識別,。識別的關(guān)鍵算法包括特征提取和建立模型兩個方面,參考文獻從基本概念到特征提取,,再到模型建立,,對說話人識別中涉及的主要算法進行了詳細的綜述,并比較了各種算法的優(yōu)劣,。
實現(xiàn)基于嵌入式的實時說話人識別系統(tǒng)是說話人識別走向應(yīng)用的關(guān)鍵步驟,。隨著DSP技術(shù)的發(fā)展,DSP作為數(shù)字處理專用芯片在復(fù)雜數(shù)學(xué)算法的實現(xiàn)上起著越來越重要的作用,。參考文獻在DSP上實現(xiàn)了說話人確認,,并應(yīng)用于汽車聲紋鎖。本文以TI公司的TDSDM642EVM為平臺,,實現(xiàn)了實時的說話人身份識別系統(tǒng),。
1 系統(tǒng)組成
說話人識別系統(tǒng)是一個模式識別的過程,總體上分為兩個步驟:第一個步驟是訓(xùn)練說話人模型,,第二個步驟是通過比對模型庫對輸入的信號進行說話人識別,。其識別過程如圖1所示,。
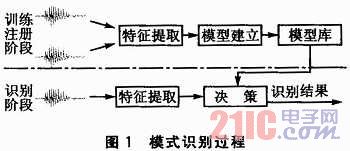
在訓(xùn)練注冊階段,系統(tǒng)主要完成說話人的特征提取以及模型特征庫的建立,。在識別階段,,系統(tǒng)根據(jù)輸入的語言信號提取相應(yīng)的特征,然后再與模型庫中的模型進行匹配判決,,最后給出識別結(jié)果,。
說話人識別在嵌入式系統(tǒng)中實現(xiàn)時主要完成語音采集、模型訓(xùn)練,、匹配識別3個任務(wù),。本文采用TDSDM642EVM平臺實現(xiàn)說話人識別系統(tǒng),其結(jié)構(gòu)框圖如圖2所示,。該系統(tǒng)通過AIC23實現(xiàn)語音信號采集和播放的功能,,輸入的語音信號經(jīng)過TDSDM642處理后,通過LED顯示識別結(jié)果,。 ROM中包含說話人識別程序和訓(xùn)練出的模型數(shù)據(jù),,并可以實時更新。SDRAM則提供了系統(tǒng)運行時所需的內(nèi)存,。

2 系統(tǒng)算法描述
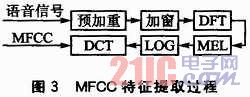
說話人識別的算法主要包括特征提取和模式識別兩個方面,。MFCC特征參數(shù)是從頻率域提取語音信號的特征參數(shù),并根據(jù)人耳的聽覺特性進行降維,,既可減小計算復(fù)雜度,,又能獲得良好的識別效果。MFCC特征提取過程如圖3所示,。
說話人識別建模的方法主要有矢量量化(VQ),、高斯混合模型(GMM)、支持向量基(SVM),、人工神經(jīng)網(wǎng)絡(luò)(ANN),,以及動態(tài)時間規(guī)整(DTW)等。綜合考慮嵌入式系統(tǒng)上算法的識別率和計算量,,本文采用DTW方法實現(xiàn)文本相關(guān)的說話人識別,。
3 定點算法實現(xiàn)和優(yōu)化
TDSDM642是TI公司推出的定點DSP芯片,,具有性價比高,、運算速度快的優(yōu)點,但是定點DSP對于浮點運算比較困難,,因此在系統(tǒng)實現(xiàn)時需要對算法進行浮點到定點的移植,。同時,為了使DSP上的代碼獲得最好的性能,,還應(yīng)該根據(jù)TDSDM642芯片片內(nèi)資源的特征進行優(yōu)化,。優(yōu)化的方法有編譯優(yōu)化,、軟件流水、內(nèi)聯(lián)函數(shù)等,。通過優(yōu)化可以明顯提高代碼執(zhí)行速度,,并減小代碼尺寸。
說話人識別當(dāng)中,,計算耗時最長的是MFCC參數(shù)的提取和參數(shù)模型的訓(xùn)練,,本文采用以下優(yōu)化方法。
3.1 編譯器優(yōu)化
TI公司的CCS編譯器可以對C代碼進行不同級別的優(yōu)化,,通過打開不同的優(yōu)化選項,,可以針對具體的硬件平臺進行不同程度的優(yōu)化,包括代碼的大小,、運行的速度等,。通常經(jīng)過CCS優(yōu)化的程序,運行速度已經(jīng)相當(dāng)快,,結(jié)構(gòu)設(shè)計良好的程序能實現(xiàn)90%的優(yōu)化,。如果還沒有達到系統(tǒng)設(shè)計的要求,則需要對代碼進行手工優(yōu)化,。
3.2 軟件流水優(yōu)化
TDSDM642處理器采用C64x系列芯片,,其內(nèi)部共有8條軟件流水線,可以8條指令并行執(zhí)行,,能夠大大提高系統(tǒng)性能,。恰當(dāng)?shù)卦O(shè)計軟件結(jié)構(gòu),并配合合適的編譯優(yōu)化選項,,可以充分利用芯片內(nèi)的軟件流水優(yōu)化提高系統(tǒng)性能,。CCS的編譯優(yōu)化一般只針對最內(nèi)層的循環(huán)進行流水
優(yōu)化,并且在循環(huán)中代碼應(yīng)該盡量簡單,,如果循環(huán)中含有大量判斷,、跳轉(zhuǎn)等指令,那么編譯出來的軟件流水會大打折扣,,有時甚至無法進行流水執(zhí)行指令,,這樣處理器的性能就不能充分地發(fā)揮出來。
3.3 循環(huán)展開優(yōu)化
循環(huán)展開是另一種優(yōu)化程序的方法,。為了充分利用芯片內(nèi)的硬件資源,,使盡可能多的指令同時并行執(zhí)行,可以采用將小循環(huán)展開的方式,,使片內(nèi)資源的性能得到最大的發(fā)揮,。CCS優(yōu)化編譯器通常情況下會根據(jù)程序的情況自動展開循環(huán),編程人員也可以采用編譯指令或手工方式展開循環(huán)優(yōu)化程序。
3.4 采用內(nèi)聯(lián)函數(shù)
TI公司的C6000編譯器含有大量的內(nèi)聯(lián)函數(shù),,支持從C語言里直接調(diào)用匯編程序,,從而大大提高程序的執(zhí)行速度。系統(tǒng)提供的內(nèi)聯(lián)函數(shù)還可以支持C64x系列DSP特有指令的執(zhí)行,,例如數(shù)據(jù)打包相乘等操作,,可以進一步提高系統(tǒng)數(shù)據(jù)處理能力。
4 實驗結(jié)果
本文在TDSDM642 EVM平臺上實現(xiàn)了實時的說話人識別系統(tǒng),。經(jīng)過對10個人的語音數(shù)據(jù)進行識別實驗,,正確率達到90%,可以達到實用水平,。通過改進算法和調(diào)整參數(shù),,可以進一步提高系統(tǒng)識別率,以滿足安全系統(tǒng)的更高要求,。