
??? 摘? 要:介紹一種Linux下的基于64位PCI總線和多片F(xiàn)PGA的高速計算平臺的設計和實現(xiàn),利用Altera公司的PCI軟核——PCI_mt64構建此平臺的PCI橋接口模塊,設計出一種兼容總線寬度64位/32位、時鐘66MHz的PCI規(guī)范的接口模塊,以及與此相配合的DMA狀態(tài)機,并給出Linux驅動的關鍵部分。?
????關鍵詞: PCI_mt64; 現(xiàn)場可編程門陣列; DMA; Linux驅動
?
??? PCI(Peripheral Component Interconnection)總線接口是目前一種應用廣泛、可兼容支持32/64位的局部總線接口,它同時支持多組外圍設備,不受制于處理器,數(shù)據(jù)吞吐量大(32位時峰值高達132MB/s,64位時峰值高達528MB/s)[1]。連接到PCI總線上的設備分為主設備和從設備,接口設計成為PCI總線與設備進行數(shù)據(jù)傳輸?shù)臉蛄骸5牵琍CI總線協(xié)議十分復雜,不容易實現(xiàn)。目前實現(xiàn)PCI接口的有效方案有兩種:使用專用總線接口器件和專用PCI軟核IP-core。?
??? 目前,業(yè)界基于32位PCI總線使用較多的接口芯片是AMCC公司的S59xx系列和PLX公司的PLX系列。而對于64位的PCI總線,目前PLX公司的9656芯片雖然可以支持,但在設備本地端,9656芯片只能提供32位的接口,并不是完全的64位PCI接口芯片,數(shù)據(jù)的處理速度因此而受到限制。?
??? 另一方面,Linux操作系統(tǒng)是一種基于GNU通用公共許可證(GPL)架構下、源碼公開的免費操作系統(tǒng),繼承了Unix穩(wěn)定有效的特點,采用先進的內存管理機制,能有效地利用物理內存;與Windows相比,Linux在安全性、漏洞修補上都具有其獨特的優(yōu)勢,因此,目前Linux在工業(yè)、政府部門都有著廣泛的應用。?
??? 本文介紹一種在Linux操作系統(tǒng)下的、64位66MHz高速PCI的FPGA通用并行計算平臺的設計與實現(xiàn)。該平臺采用Altera公司提供的IP軟核PCI_mt64[2-3],自行設計本地端64位橋接口;同時,采用多片F(xiàn)PGA運行不同的算法,并在FPGA內部實現(xiàn)算法的并行化,從而大大提高了PC機對大運算量的數(shù)字信號處理的能力。系統(tǒng)已成功應用到MD5 的快速解密。?
1 系統(tǒng)設計的目的?
??? 目前信號處理對于實時性要求的提高,雖然也使CPU的運算頻率日益提高,可以大大提高某些大運算量應用計算的速度,但是獨占CPU資源并不是一個很好的選擇;同時由于成本及其他因素的考慮,也不可能專門使用多臺小型機進行計算。在這種情況下,將信號處理算法并行化,運行于高性能的FPGA,并通過適當?shù)目偩€接口,可以達到既不占用CPU資源,同時又有多臺小型機同時運算的性能。?
??? 本硬件平臺的設計目的是將64位66MHz的PCI接口與FPGA結合起來,使得該硬件平臺既可以保證數(shù)據(jù)量的高速吞吐和數(shù)據(jù)處理的實時性要求,又可以在運算處理過程中不占用CPU資源。另外,由于采用多片高性能FPGA,因此也可以選擇在該平臺上同時運行多個算法,如陣列信號處理中的DOA算法、波束形成算法等。?
??? 以下對端口的定義及說明均是基于實現(xiàn)該算法,而整個系統(tǒng)平臺適用于多種大計算量的數(shù)字信號處理。?
2 系統(tǒng)硬件架構?
??? 本系統(tǒng)利用1片Altera 公司的EP1S20F780C7芯片作為橋芯片,負責加載本地橋模塊、配置算法FPGA、DMA操作、數(shù)據(jù)輪詢下發(fā)以及運算結果上行接收和中斷;采用4片Altera公司的 EP2S60F484C5作為數(shù)據(jù)處理芯片,可以加載不同的信號處理算法,從而實現(xiàn)平臺的通用化。?
??? 在該系統(tǒng)架構中,PCI橋模塊的設計實現(xiàn)、DMA狀態(tài)機的操作流程和中斷的處理是其中的重點和難點,下面分別予以說明。?
2.1 PCI橋模塊的設計?
??? 在本系統(tǒng)中,為了縮短開發(fā)周期,采用了Altera公司的IP軟核PCI_mt64,這樣系統(tǒng)的設計就規(guī)避了PCI局部總線規(guī)范和PCI配置寄存器的實現(xiàn),而能夠集中精力進行本地橋模塊的設計。本地橋模塊結構如圖1所示,其基本設計思想如下:?
?

?
??? (1)橋模塊要實現(xiàn)對I/O空間與Memory空間的管理、各種控制信號(包括中斷)的產(chǎn)生和數(shù)據(jù)流的處理。其中,I/O空間定義一般寄存器和中斷寄存器;Memory空間則包括了DMA寄存器和FIFO初始地址寄存器,其又包括以下子模塊:Interrupt模塊、FIFO管理模塊和DMA引擎(FIFO、Memory空間實現(xiàn)方式)。其中FIFO管理模塊又可根據(jù)功能劃分為三個部分:橋FIFO(Bridge FIFO)、結果數(shù)據(jù)FIFO(Result FIFO)和FPGA配置FIFO(FPGA Configure FIFO)。?
??? 中斷模塊發(fā)出DMA傳輸?shù)南嚓P控制中斷,如完成中斷、算法運算結果的相關中斷。在本系統(tǒng)中,算法結果中斷分為三種,分別對應于運算有結果、運算中斷查詢和運算無結果,這三種類型中斷由算法FPGA通過串行接口通知橋模塊。由于串行命令的可編碼,因此中斷種類可以根據(jù)不同的算法、不同的場合而更改。?
??? 在橋模塊中,最重要的部分是主從控制模塊的實現(xiàn),其功能是執(zhí)行與PCI-core的交互、響應PCI中的控制信號,并發(fā)出相應的、符合PCI時序的主從控制信號。?
??? (2)主從控制模塊中,Local Target部分只負責對32位寄存器的讀寫,功能較為簡單,不需要啟動DMA操作,在Linux驅動中可以在IOCTL中通過writeX( )和readX( )兩個函數(shù)對存儲空間進行讀寫,也可以通過inX( )和outX( )兩個函數(shù)對I/O空間讀寫寄存器。其中X表示數(shù)據(jù)類型:l表示long word,w表示short word,b表示byte[4]。?
??? (3) Local Master要進行大數(shù)據(jù)量讀寫,需要兼容32/64位,同時與DMA模塊配合完成DMA數(shù)據(jù)傳輸,因此功能較為復雜。具體說明如下:?
??? 數(shù)據(jù)上行:上行數(shù)據(jù)(解密結果)由算法FPGA通過串行通信發(fā)送至橋模塊,并經(jīng)過串并轉換存入Result FIFO,同時通知中斷產(chǎn)生模塊產(chǎn)生中斷。PC機接收到中斷后即準備讀取數(shù)據(jù):PC機端設置DMA寄存器(ACR、BCR、CSR),然后本地端根據(jù)DMA寄存器CSR的設置啟動DMA操作,完成Master寫的流程。?
??? 數(shù)據(jù)下行:由于下行數(shù)據(jù)(窮舉破解使用的密鑰)數(shù)據(jù)量大,而本地端的存儲空間有限,因此系統(tǒng)采用由PC機端設置DMA寄存器(一般設置為16KB),而本地端根據(jù)寄存器和存儲空間狀況,實現(xiàn)下列操作:啟動DMA、申請PCI總線、第一次PCI數(shù)據(jù)傳輸、傳輸完畢后判斷數(shù)據(jù)是否全部被傳輸,如未全部完成則再次申請PCI傳輸直到所有數(shù)據(jù)傳輸完成,此時申請DMA完成中斷。這個過程即是Master讀的流程。?
??? 在上下行的數(shù)據(jù)通路中,DMA的啟動首先是由PC機端寫入DMA控制寄存器(字節(jié)計數(shù)寄存器BCR,地址計數(shù)寄存器ACR)開始,再寫入控制狀態(tài)寄存器CSR中的啟動位。主從控制模塊檢測到啟動位置高后,即開始DMA主模式狀態(tài)機的實現(xiàn)。?
2.2 主模式下狀態(tài)機的實現(xiàn)?
??? 主動傳輸時DMA狀態(tài)機的實現(xiàn)如圖2所示,其各狀態(tài)說明(DMA狀態(tài)機的編號與圖2相對應,如表1所示。其中重要的狀態(tài)轉移條件說明如下:?
?

?

?
??? (1) WR_BUSY轉DONE:PC請求的數(shù)據(jù)全部傳輸完成,或上行FIFO空,或DMA從設備要求斷開。?
??? (2) RETRY轉DONE:當申請再一次的PCI數(shù)據(jù)傳輸時,檢查下一次需要傳輸?shù)臄?shù)據(jù)量是否滿足PCI傳輸?shù)囊螅鐥l件不滿足,轉入DONE。?
??? (3) RD_BUSY轉DONE:PCI數(shù)據(jù)傳輸尚未結束,下行FIFO已滿,或本次PCI傳輸結束,并且DMA_BCR要求的數(shù)據(jù)已全部傳輸結束,或DMA從設備要求斷開?
??? (4) RD_BUSY轉RETRY:當本次PCI進入傳輸期、PCI總線要求重新申請時,或者當前PCI的數(shù)據(jù)傳輸結束,而未傳完DMA_BCR要求的數(shù)據(jù)量。?
??? (5) IDLE轉LOAD:DMA_CSR寄存器啟動位置位,DMA_BCR符合DMA傳輸要求,本地端下行FIFO可寫或上?
行FIFO內有數(shù)據(jù)。?
2.3 DMA方式?
??? Altera公司的PCI_mt64對進行內存讀寫的單次PCI傳輸數(shù)據(jù)量的限制:如果用總線Memory Read命令,則每次僅可以傳輸16個字節(jié)的數(shù)據(jù);如果總線用Memory Read Multiple命令,則每次最多可以傳輸4 096B的數(shù)據(jù)。由于本系統(tǒng)的目的在于運行MD5快速解密算法,PC經(jīng)PCI下發(fā)到設備的數(shù)據(jù)量是巨大的(GB量級),若由PC機端來進行多次寫DMA寄存器然后啟動DMA,則其軟件耗時不可忍受;而當該平臺應用于實時數(shù)據(jù)處理時,軟件耗時必須盡可能減小。因此,需要設計一種新的DMA傳輸方式:即由PC機端寫一次DMA寄存器,而由本地端進行多次DMA申請。?
??? 圖3給出了當PC機申請16KB數(shù)據(jù)傳輸時,一次PCI傳輸即4 096字節(jié)傳輸完、等待7個時鐘周期后(狀態(tài)Retry,mst_state = 6),再次申請總線并開始PCI傳輸?shù)倪^程。?
?

?
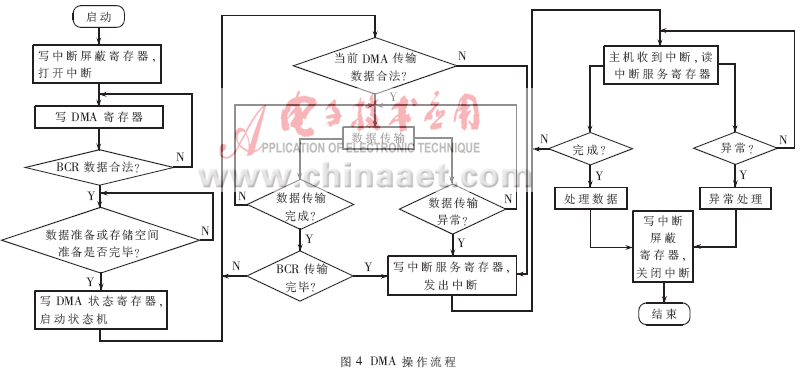
??? 鏈式DMA可以認為是一組DMA的進行,并且每次DMA的數(shù)據(jù)包大小和地址可以不同[5]。同樣這里采用的DMA也可以認為是一組DMA的進行,與鏈式DMA的區(qū)別在于DMA的讀寫地址必須是連續(xù)的,而相同點在于與每次傳輸?shù)臄?shù)據(jù)包的大小也是可以調節(jié)的。在DMA數(shù)據(jù)地址是連續(xù)的情況下,與鏈式DMA要寫入多次DMA描述符相比,本系統(tǒng)采用的DMA方式只需要寫一次DMA描述符,因此可以更有效率地完成DMA操作,其操作流程參如圖4所示。同時由于本系統(tǒng)狀態(tài)機中已存在的LOAD狀態(tài),若該狀態(tài)用于從DMA描述符FIFO中讀取描述符,則本文的DMA狀態(tài)機也可以用來實現(xiàn)鏈式DMA。?
?
?
2.4 Linux中斷處理?
??? Linux對于中斷的處理與Windows是不同的,比較靈活,下面作簡單介紹。?
??? Windows中斷處理,首先在中斷響應函數(shù)中對PCI中斷做判斷,如果是本設備的中斷則做簡單操作(非數(shù)據(jù)處理),然后調用DPC(延時過程調用)例程,在中斷處理函數(shù)中做中斷處理中未完成的操作,如將數(shù)據(jù)由內核緩沖區(qū)拷貝到用戶緩沖區(qū)。
??? 對比Windows,Linux的中斷設計采用頂半部和底半部兩部分實現(xiàn):頂半部相當于中斷響應函數(shù);底半部相當于Windows中的延時過程調用;Linux的底半部可以使用多種方式實現(xiàn),使用tasklet或者workqueue即可以實現(xiàn)操作。?
??? 普通的Linux中斷函數(shù)為void Demo_interrupt(int irq, void * dev_id, struct pt_regs * regs),如需要實現(xiàn)底半部(bottom half)時,首先使用頂半部中斷處理函數(shù):?
??? Irqreturn_t Demo_bh_interrupt (int irq, void * dev_id,struct pt_regs * regs) {?
??? /* …… */?
??? Tasklet_schedule(&Demo_tasklet);?//調用Demo_do_tasklet?
??? /* …… */?
??? Return IRQ_HANDLED;??? }?
??? 底半部函數(shù):void Demo_do_tasklet (unsigned long)。?
??? 在使用tasklet之前,首先需使用DECLARE_TASKLET(Demo_tasklet, Demo_do_tasklet, data)申明tasklet,但也可以使用struct work_queue Demo_wq申明work queue(工作隊列);申明之后需要將后半部處理函數(shù)Demo_do_tasklet ( )放入工作隊列中,可以使用下面的函數(shù):INIT_WORK(&Demo_wq, Demo_do_tasklet, NULL)。工作隊列的后半部函數(shù)與tasklet相同。?
3 設計結果與實測性能分析?
??? 使用VHDL編寫代碼,利用邏輯分析儀對運行在實際硬件上的PCI橋代碼進行分析,圖5為邏輯分析儀上所截得時序圖、PCI關鍵信號(包括被動模式和主動模式的)。?
?

?
??? 使用Altera的Quartus II 7.1對程序進行設計綜合,PCI接口最低時鐘頻率為80MHz。綜合生成網(wǎng)表文件,下載到FPGA,經(jīng)過實際測試,系統(tǒng)運行正常,其橋模塊占用4 913邏輯單元和557 056位的存儲單元。用安捷倫1 681AD型邏輯分析儀分析測試PCI關鍵信號,其結果:系統(tǒng)每傳輸16KB數(shù)據(jù)的總時間為164.487μs,數(shù)據(jù)傳輸時間為130.975μs,系統(tǒng)開銷為33.512μs,效率為79.5%。而與普通非鏈式DMA傳輸16KB數(shù)據(jù)的總時間比較,以32位66MHz頻率的PCI系統(tǒng)為測試平臺,可以得到如表2所示的結果。?
?

?
??? 從表2可以看出,本文所設計的DMA方法之所以效率會比傳統(tǒng)的非鏈式DMA的方法要高,在于軟件響應的時間大大縮短,當要傳送的數(shù)據(jù)量越大時,DMA的平均數(shù)據(jù)率就會越高。?
??? 本文設計的系統(tǒng)平臺已經(jīng)成功地應用于MD5的解密。通過實際性能的測試,基于IP-core的64位接口設計完全達到了預期的性能目標,并且該平臺可以滿足大運算量、實時性要求高的數(shù)字信號處理算法的要求。下一階段的工作,將在該平臺上實現(xiàn)陣列信號處理的算法,以達到高速實時處理,減少資源耗費的目的。?
參考文獻?
[1]?Altera Corporation. PCI local bus?specification revison 2.2. 1998.?
[2]?Altera Corporation. PCI megacore?function user guide. 2003.?
[3]?Altera Corporation. PCI-MT64 megacore function reference design. 2003.?
[4] CORBET J,RUBINI A,HARTMAN?G K. Linux?device driver 3rd. O′Reilly, 2005.?
[5]?張浩,徐寧儀,周祖成.基于PCI Core的鏈式DMA控制器設計. 計算機應用, 2005,(3).