
摘 要: 通過對實(shí)時(shí)系統(tǒng)中采用軟硬件設(shè)計(jì)優(yōu)缺點(diǎn)的比較,提出使用FPGA作為協(xié)處理器來提高系統(tǒng)整體性能的觀點(diǎn),并且通過介紹直線提取中的相位編組算法的實(shí)現(xiàn)作為具體實(shí)例,進(jìn)一步闡述FPGA作為協(xié)處理器的結(jié)構(gòu)特點(diǎn)及設(shè)計(jì)原則。
關(guān)鍵詞: FPGA 協(xié)處理器 實(shí)時(shí)性 直線提取
實(shí)時(shí)系統(tǒng)一般都不是通用的,往往是針對具體的任務(wù)而設(shè)計(jì)的。軟件編程的優(yōu)點(diǎn)是設(shè)計(jì)調(diào)試靈活。無論多復(fù)雜的任務(wù),只要給出算法,我們一定能夠通過軟件編程的方式來實(shí)現(xiàn),而且調(diào)試、修改都容易得多。缺點(diǎn)是執(zhí)行指令的效率不高,單CPU只能串行地執(zhí)行指令(多CPU方案確實(shí)是克服這一缺點(diǎn)的有效辦法,但是大大增加了軟硬件的復(fù)雜度)。對于一項(xiàng)任務(wù),軟件都要將它不斷分解,最終變成CPU可執(zhí)行的機(jī)器語言,這種化整為零的指令方式正是軟件的優(yōu)點(diǎn),同時(shí)也成了它的缺點(diǎn)。執(zhí)行一條指令一般需取指令、解碼、取操作數(shù)、執(zhí)行四步。雖然CPU內(nèi)部有了cache,實(shí)行流水指令操作,但是如果語句中有大量的跳轉(zhuǎn)語句,就會使流水線頻繁中斷,并且使cache的命中率降低。專用硬件的特點(diǎn)是速度快,便于進(jìn)行并行性設(shè)計(jì),是滿足實(shí)時(shí)性要求最好的方法。其缺點(diǎn)在于設(shè)計(jì)周期長,調(diào)試修改不容易,受到可用器件的實(shí)際限制,復(fù)雜的算法難以完全用硬件來完成。從以上的分析中,我們看到軟硬件設(shè)計(jì)有各自的優(yōu)缺點(diǎn),能否將軟硬件各自的優(yōu)點(diǎn)結(jié)合起來呢?FPGA出現(xiàn)后,由于它設(shè)計(jì)輸入方式靈活,設(shè)計(jì)周期短,片內(nèi)資源豐富,可無限次加載等特點(diǎn),很適合對具體的任務(wù)進(jìn)行設(shè)計(jì)。我們可以用它來發(fā)揮硬件速度快的特點(diǎn)完成低層的、大量重復(fù)使用的任務(wù)。而處理器在上層實(shí)時(shí)調(diào)用FPGA。FPGA就象一個(gè)硬件函數(shù),這種結(jié)構(gòu)既可以發(fā)揮硬件的高速性,又利用了軟件的靈活性。兩者的結(jié)合可以極大地提高整體處理速度,而且開發(fā)周期短,修改方便。
下面以圖像處理中的直線提取算法的實(shí)現(xiàn)為例,來說明FPGA作為協(xié)處理器在實(shí)時(shí)系統(tǒng)中的應(yīng)用。
1 相位編組算法實(shí)現(xiàn)直線提取
1.1 相位編組算法實(shí)現(xiàn)直線提取的原理
直線提取就是將圖像中明暗變化的邊緣以輪廓線或邊界線的形式提取出來。相位編組算法是直線提取中比較有效的一種。其算法框圖如圖1。

一幀圖像的象素逐行輸入,計(jì)算梯度方向角是先對圖像的每個(gè)像素求x方向上的差分Dx和y方向上的差分Dy。arctg(Dy/Dx)是該點(diǎn)梯度的正切值。梯度方向代表了該點(diǎn)周圍明暗變化最劇烈的方向。接下來得到該點(diǎn)梯度的方向角θ和梯度的幅度M。
Dx=p[x-2,y+1]+p[x-1,y+1]×2+p[x,y+1]-p[x-2,y-1]-p[x-1,y-1]×2-p[x,y-1]
Dy=p[x,y-1]+p[x,y]×2+p[x.y+1]-p[x-2,y-1]-p[x-2,y]×2-p[x-2,y+1]
θ=arctg(Dy/Dx)
M=Dx+Dy
相位編組是將所有具有相同或相近方向角且?guī)缀挝恢眠B通(8連通或4連通)的點(diǎn)歸為一個(gè)點(diǎn)集,該集合就是直線的點(diǎn)集。實(shí)際上,圖像中大部分的點(diǎn)周圍明暗變化很小,我們只對M值大于一個(gè)給定的閥值Threshold的點(diǎn)進(jìn)行編組。為了減少下一步處理的數(shù)據(jù)量,我們把滿足M大于閥值的點(diǎn)寫成水平跑碼的形式,即把水平位置相鄰且方向值θ相同的點(diǎn)編為一個(gè)跑碼。然后每一行的跑碼與上一行的跑碼進(jìn)行比較,幾何位置連通且方向值相近的跑碼歸為一類。這樣,就得到整個(gè)圖像中的所有直線的點(diǎn)集合了。
得到直線的點(diǎn)集后,用最小二乘法對每個(gè)點(diǎn)集擬合出直線。
1.2 系統(tǒng)的軟硬件劃分
系統(tǒng)在實(shí)現(xiàn)算法的前提下對實(shí)時(shí)性有較為苛刻的要求,圖像大小為512×512,圖像數(shù)據(jù)的傳輸速率為5MByte/s,兩幀的間隔為0.6秒,要求系統(tǒng)提取直線的時(shí)間不得超過0.5秒。分析上面的框圖,要做的處理非常多,包括對圖像進(jìn)行求差、求和運(yùn)算、二維梯度場計(jì)算、相位編組、直線擬合等不同層次不同類別的處理和計(jì)算,如果完全由軟件做,為了達(dá)到所要求的實(shí)時(shí)性,CPU的主頻至少要250MHz以上,現(xiàn)有的高速DSP難以勝任。所以,必須考慮一部分任務(wù)由專用硬件來完成。經(jīng)過嚴(yán)密的論證,最后系統(tǒng)采用了圖2所示的結(jié)構(gòu)。

FPGA1和FPGA2選用XILINX公司的XC5210,DSP選用內(nèi)部主頻為20MHz的TMS320C40。求梯度、求反正切及編碼等步驟屬于像素級的處理,處理比較規(guī)則,而且隨著像素的流水輸入,一直到編碼完成,沒有中間數(shù)據(jù)需要存儲,可由前級FPGA1完成。其中求反正切可用查表法,查表的數(shù)據(jù)放在與FPGA1相連的RAM中。跑碼的數(shù)據(jù)結(jié)構(gòu)為:
typedef struct tagRUNCODE{
int x0;
int len;
unsigned char orientation;
}RUNCODE;
其中x0代表初始點(diǎn)的X坐標(biāo), len代表跑碼長度,orientation代表跑碼的方向值。剩下的就是相位編組和直線擬合了。直線擬合主要是浮點(diǎn)運(yùn)算,交給DSP完成比較合適。難度在于相位編組。相位編組約占直線提取整個(gè)工作量的70%,操作復(fù)雜,屬于全局性的處理,涉及到對RAM的管理及訪問,該部分無法由硬件獨(dú)立完成。我們必須對這一部分進(jìn)行軟硬件的分割,讓FPGA以協(xié)處理器的方式加快這部分的處理速度。現(xiàn)以表1所示跑碼數(shù)據(jù)為例說明相位編組的過程,其中Ai代表當(dāng)前行的第i個(gè)跑碼,Bj代表上一行的第j個(gè)跑碼,圖3是跑碼數(shù)據(jù)的位置示意圖。
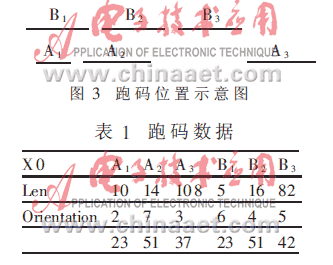
先從A1開始,拿它與上一行的各個(gè)跑碼比,A1與B1位置連通,且方向值也相同,所以A1與B1連通。將A1的點(diǎn)放入B1所屬的點(diǎn)集中。A1再與B2比,位置不連通,A1與B2不連通。由于B2在A2的后面,所以B2以后的跑碼一定不會與A1連通,不用再比較了。我們稱B2相對于A1越界。由此類推,A2與B1不連通,與B2連通,B3相對于A2越界。將A2的點(diǎn)放入B2所屬的點(diǎn)集中。A3從B3前一個(gè)跑碼開始比(這樣可以省去與B2前面的跑碼比較),A3與B2不連通,與B3也不連通。這樣,一行比較完畢。將當(dāng)前行上移,掃描下一行。一幀下來,就可以將所有直線的點(diǎn)集得到。相位編組的特點(diǎn)是數(shù)據(jù)結(jié)構(gòu)復(fù)雜,要對內(nèi)存進(jìn)行復(fù)雜的操作。顯然FPGA無法獨(dú)立完成,如果把它交給DSP去做,其中判斷Ai與Bj是否連通要經(jīng)常使用,是相位編組中相對簡單但大量重復(fù)使用的部分,可以寫成如下函數(shù):
int Is_Connect(RUNCODE runcodel,RUNCODE runcode2)
/*判決 位置連通性和梯度方向連通性/*
/* RETURN:255--連通0--不連通1--已經(jīng)越界(runcodel.x0+runcodel.len-runcode2.x0)<0*/
{
if(runcode 1.x0<=runcode2.x0)
{ if((runcodel.x0+runcodel.len-runcode2.x0)>0)
{ if(abs(runcodel.orientation-runcode2.orientation)<Threshold)
return 255;
}
else
{ return 1;
}
}
else
{ if(runcode2.x0+runcode1.len-runcode1.0x)>0)
if(abs(runcode1.orientation-runcode2.orientation)<Threshold)
return 255;
}
return 0;
}
可以看出,函數(shù)中主要的操作是判斷語句,判斷語句內(nèi)部的操作卻不多。也就是說,在該函數(shù)中,DSP相當(dāng)一部分時(shí)間里都在作判斷。判斷語句在匯編中對應(yīng)的是條件跳轉(zhuǎn)語句,這種頻繁的跳轉(zhuǎn)語句會使DSP內(nèi)部的指令流水線中斷,使cache命中率大為降低。實(shí)驗(yàn)表明,用DSP編程執(zhí)行這段代碼不能滿足系統(tǒng)實(shí)時(shí)性的需要。硬件電路完成條件跳轉(zhuǎn)指令只需要比較器和二選一開關(guān)即可,而且硬件電路實(shí)現(xiàn)多重判斷和單一判斷的速度是一樣的。因此,硬件電路實(shí)現(xiàn)該函數(shù)不僅比較容易,而且執(zhí)行速度只需一個(gè)時(shí)鐘周期。于是我們用FPGA2實(shí)現(xiàn)此函數(shù),讓DSP來調(diào)用它,并取得了較理想的效果。
2 對FPGA用于協(xié)處理器的幾點(diǎn)探討
通過以上實(shí)例我們可以探討一下FPGA用于協(xié)處理器的結(jié)構(gòu)特點(diǎn)和設(shè)計(jì)原則。
2.1 FPGA作為協(xié)處理器所需的結(jié)構(gòu)
硬件要完成某種應(yīng)用方式,必須依賴于相應(yīng)的系統(tǒng)硬件結(jié)構(gòu)。FPGA在數(shù)字信號處理設(shè)計(jì)中最典型的應(yīng)用有兩種:一種是作為整個(gè)數(shù)據(jù)處理流程中的一個(gè)“結(jié)點(diǎn)”,數(shù)據(jù)沿著線狀結(jié)構(gòu)被不斷加工處理,F(xiàn)PGA在這里作為處理單元,獨(dú)立地完成算法中的某些功能。如圖4。
圖中的PE一般為DSP或單片機(jī)。上例中的前級FPGA1就是作為處理單元來應(yīng)用的。另一種是作為協(xié)處理器,如圖5。
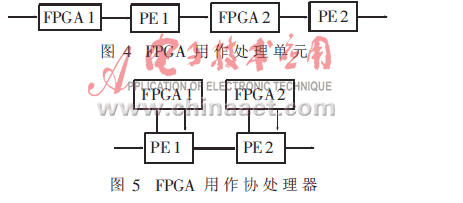
FPGA從屬于PE,PE的一部分任務(wù)由FPGA分擔(dān)。PE象調(diào)用軟件中的函數(shù)一樣來調(diào)用FPGA。只是函數(shù)內(nèi)部寫的不是完成該功能的語句,而是向FPGA送參數(shù),再從FPGA接收結(jié)果。硬件的速度相對于PE的指令操作來說一般要快得多,可以認(rèn)為將數(shù)據(jù)送出后馬上就可得到結(jié)果。如果使用得當(dāng),這種結(jié)構(gòu)可以大幅度提高PE的處理速度,需要指出的是,雖然硬件執(zhí)行起來要比軟件快,但是協(xié)處理器的開銷主要在PE與FPGA的接口上,要保證PE與FPGA有高速的雙向通道,否則就達(dá)不到高速性的目的。在提取直線的系統(tǒng)中,DSP是通過自身的兩個(gè)高速并行口(一發(fā)一收)與FPGA相連接的。實(shí)際上,如果想進(jìn)一步提高協(xié)處理器的效率,應(yīng)該考慮設(shè)計(jì)更快的接口。
2.2 FPGA作為協(xié)處理器的優(yōu)點(diǎn)
使用FPGA作為協(xié)處理器的最大優(yōu)勢在于可根據(jù)具體算法的實(shí)際需要來為PE定做合適的硬件函數(shù)。傳統(tǒng)的協(xié)處理器為了自身的通用性,實(shí)現(xiàn)的一般都是指令層次上的功能,如80387專門完成乘加運(yùn)算,而FPGA設(shè)計(jì)和使用更靈活,可以將協(xié)處理器建立在函數(shù)層上。如直線提取中協(xié)處理器完成的函數(shù),DSP本身不善長大量的邏輯判斷,如果不結(jié)合具體的算法,在指令層次上很難解決DSP的這一弱點(diǎn)。只有在具體的算法中,對邏輯判斷集中的一段程序進(jìn)行硬件設(shè)計(jì),才能做到比DSP高得多的效率。站在CPU的角度上看,CPU可以象調(diào)用軟件函數(shù)一樣來調(diào)用FPGA,而速度象匯編語句一樣快。這樣有效地克服了CPU的指令層次上效率低的弱點(diǎn)。又比如,矩陣乘法: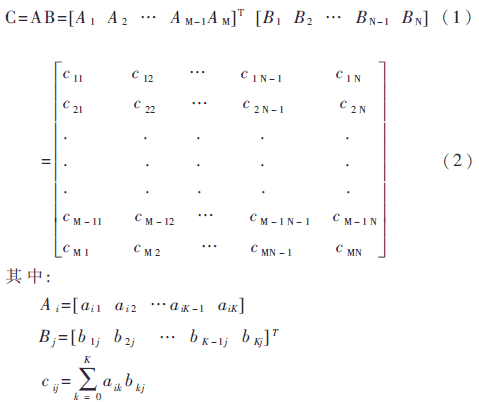
兩個(gè)矩陣相乘,可以先分解為兩個(gè)向量的乘法,如公式(1),繼續(xù)分解為兩個(gè)標(biāo)量的乘法,如公式(2)。CPU的指令集只能做標(biāo)量乘法,在這個(gè)層次上很難大幅度提高矩陣乘法的效率。如果用FPGA設(shè)計(jì)一個(gè)向量乘法器,則可以少M(fèi)N(2K-2)條指令。如果訂做一個(gè)矩陣乘法器,可以少NM(2K-1)-1條指令。
2.3 FPGA作為協(xié)處理器設(shè)計(jì)的原則
一般來講,F(xiàn)PGA適合完成函數(shù)級的任務(wù),比如矩陣乘法、查表法等。實(shí)際中,一個(gè)復(fù)雜的任務(wù)要做的處理比較多,我們不大可能把每個(gè)函數(shù)都硬件化,給FPGA分配怎樣的任務(wù)才算恰當(dāng)呢?在確定協(xié)處理器的任務(wù)時(shí)要整體把握,確定影響整體速度的瓶頸是哪部分,選擇最有潛力可挖的部分。硬件分擔(dān)的任務(wù)不是越多越好,這里面要綜合考慮FPGA設(shè)計(jì)的難度,系統(tǒng)的實(shí)際要求等。FPGA的任務(wù)太多,可調(diào)用性變差,如果只能被調(diào)用很少的幾次,它對整體速度的提高就不會有多少貢獻(xiàn),而且會增加FPGA設(shè)計(jì)的工作量。在直線提取的例子中,我們必須對算法框圖各部分有較清楚的認(rèn)識,看到判斷兩跑碼的連通性要經(jīng)常調(diào)用,而且DSP完成該函數(shù)效率不高,這兩點(diǎn)是采用協(xié)處理器完成該函數(shù)的兩個(gè)必要條件。C40的一個(gè)指令周期為50ns,如果不算調(diào)用函數(shù)時(shí)的堆棧操作,完成該函數(shù)至少需13個(gè)指令周期。而FPGA只需25.5ns就可完成。對于一幅512×512的圖像,設(shè)一行里有150個(gè)跑碼,平均每個(gè)跑碼調(diào)用3次該函數(shù),每調(diào)用一次FPGA比原來節(jié)省10個(gè)周期,則一幀圖像可節(jié)省:
512×150×3×10×50ns=0.115s
在實(shí)際測試中,整體的運(yùn)行時(shí)間比原來快了0.15s左右。
FPGA作為協(xié)處理器在相位編組算法的實(shí)現(xiàn)中得到了成功的應(yīng)用。在較為復(fù)雜的處理中,我們可以將任務(wù)分解為上下層關(guān)系,下層簡單而規(guī)則并且大量重復(fù)使用的工作交給FPGA完成,軟件在上層調(diào)用它,從而提高了系統(tǒng)整體的處理速度。這里面,F(xiàn)PGA與傳統(tǒng)協(xié)處理器相比更加靈活,這種靈活性不僅體現(xiàn)在FPGA可以更加帖近具體的算法進(jìn)行設(shè)計(jì)上,而且依據(jù)可重構(gòu)的思想,我們可以在不同的時(shí)間段上對FPGA加載不同的功能函數(shù),系統(tǒng)資源從而得到了充分利用。
參考文獻(xiàn)
1 朱傳乃.386/486微型計(jì)算機(jī)系統(tǒng)原理與維修.北京:民郵電出版社
2 王潤生.圖像理解.國防科技大學(xué)出版社
3 常 青,陳輝煌.可編程專用集成電路及其應(yīng)用與設(shè)計(jì)實(shí)踐.國防工業(yè)出版社
4 TEXAS INSTRUMENTS.TMS320C4X User's Guide.1991
5 XILINX.The Programmable Logic Data Book.1998