
在用統(tǒng)計(jì)分析方法研究這個(gè)多變量的課題時(shí),變量個(gè)數(shù)太多就會增加課題的復(fù)雜性。人們自然希望變量個(gè)數(shù)較少而得到的信息較多。在很多情形,變量之間是有一定的相關(guān)關(guān)系的,當(dāng)兩個(gè)變量之間有一定相關(guān)關(guān)系時(shí),可以解釋為這兩個(gè)變量反映此課題的信息有一定的重疊。主成分分析是對于原先提出的所有變量,建立盡可能少的新變量,使得這些新變量是兩兩不相關(guān)的,而且這些新變量在反映課題的信息方面盡可能保持原有的信息。
主成分分析(Principal Component Analysis,PCA), 將多個(gè)變量通過線性變換以選出較少個(gè)數(shù)重要變量的一種多元統(tǒng)計(jì)分析方法。又稱主分量分析。在實(shí)際課題中,為了全面分析問題,往往提出很多與此有關(guān)的變量(或因素),因?yàn)槊總€(gè)變量都在不同程度上反映這個(gè)課題的某些信息。主成分分析首先是由K.皮爾森對非隨機(jī)變量引入的,爾后H.霍特林將此方法推廣到隨機(jī)向量的情形。信息的大小通常用離差平方和或方差來衡量。
人們到醫(yī)院就診時(shí),通常要化驗(yàn)指標(biāo)來協(xié)助醫(yī)生的診斷。診斷就診人員是否患腎炎時(shí)通常要化驗(yàn)人體內(nèi)各種元素含量,主要包括鋅(Zn)、銅(Cu)、鐵(Fe)、鈣(Ca)、鎂(Mg)、鉀(K)及鈉(Na)。表1是確診病例的化驗(yàn)結(jié)果,其中1~30號病例是已經(jīng)確診為腎炎病人的化驗(yàn)結(jié)果,31~60號病例是已經(jīng)確定為健康人的結(jié)果[2]。在論文中列出的數(shù)據(jù)是原始數(shù)據(jù)中1~10號病例及31~40號病例的數(shù)據(jù),運(yùn)用主成分計(jì)算時(shí)以所有數(shù)據(jù)為初始數(shù)據(jù)。

1 主成分分析模型
主成分分析是設(shè)法將原來眾多具有一定相關(guān)性(比如P個(gè)指標(biāo)),重新組合成一組新的互相無關(guān)的綜合指標(biāo)來代替原來的指標(biāo)。通常數(shù)學(xué)上的處理就是將原來P個(gè)指標(biāo)作線性組合,作為新的綜合指標(biāo)。最經(jīng)典的做法就是用F1(選取的第一個(gè)線性組合,即第一個(gè)綜合指標(biāo))的方差來表達(dá),即Var(F1)越大,表示F1包含的信息越多。因此在所有的線性組合中選取的F1應(yīng)該是方差最大的,故稱F1為第一主成分。如果第一主成分不足以代表原來P個(gè)指標(biāo)的信息,再考慮選取F2即選第二個(gè)線性組合,為了有效地反映原來信息,F(xiàn)1已有的信息就不需要再出現(xiàn)在F2中,用數(shù)學(xué)語言表達(dá)就是要求Cov(F1, F2)=0,則稱F2為第二主成分,依此類推可以構(gòu)造出第三、第四,……,第P個(gè)主成分。

2 模型應(yīng)用
2.1 問題分析解決

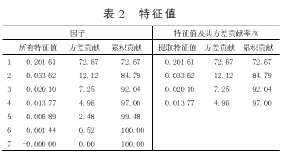
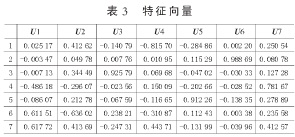
因C1=[X1 X2 … X7]*[U11 U12 … U17]T,因?yàn)樘卣髦档姆讲钬暙I(xiàn)率為72.67 %,表明C1包含原變量中的絕大部分信息,則在原來7個(gè)因子的基礎(chǔ)上引入C1作為第8個(gè)因子,C1=[0.70502、0.6341、0.87415、0.80724、0.4212、0.62897、0.37992、0.85489、0.57495、0.71527、-0.74635、0.03003、-0.30047、-0.03826、-0.80605、-1.32826、-0.5588、-0.00363、0.37216、-3.19199].再將其做標(biāo)準(zhǔn)化變化,再次通過主成分分析并結(jié)合SPSS軟件確定B第一主成分F1、第二主成分F2和綜合主成分F.根據(jù)對這8個(gè)因子通過SPSS的因子分析如表4、表5所示。

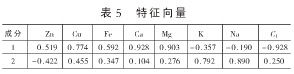
由表5可知C1與5種元素有著顯著的相關(guān)性,可見許多變量之間直接的相關(guān)性比較強(qiáng),證明它們存在信息上的重疊。
2.2 主成分表達(dá)式
主成分個(gè)數(shù)提取原則為主成分對應(yīng)特征值>1的前m個(gè)主成分。特征值在某種程度上可以被看成是表示主成分影響力度大小的指標(biāo),如果特征值<1,說明該主成分的解釋力度還不如直接引入原變量的平均解釋力度,因此一般可以用特征值>1作為納入標(biāo)準(zhǔn)。通過表4可知,提取2個(gè)主成分,即m=2.從表5可知C1、Zn、Cu、Fe、Ca、Mg在B第一主成分上有較高的載荷,說明B第一主成分基本反映了這些指標(biāo)的信息,K、Na在B第二主成分上有較高的載荷,說明B第二主成分基本反映了K、Na 2個(gè)指標(biāo)的信息。所以提取2個(gè)主成分是基本反映全部指標(biāo)的信息,所以決定用2個(gè)新的變量來代替原來的8個(gè)變量。通過SPSS將表5中的數(shù)據(jù)除以主成分相對應(yīng)的特征值開平方根,得到兩主成分中每個(gè)指標(biāo)所對應(yīng)的系數(shù)。將得到的特征向量與標(biāo)準(zhǔn)化后的數(shù)據(jù)相乘,然后就可以得到主成分表達(dá)式:
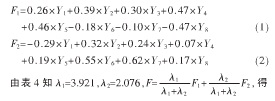
![]()
由(1)、(2)、(3)式得到B第一主成分F1、B第二主成分F2和綜合主成分F的數(shù)據(jù)及排名,如表6所示。
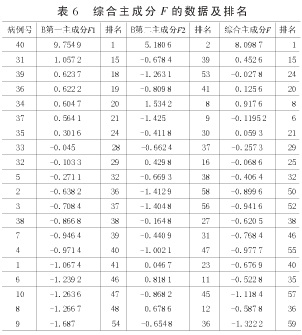
由表6可以看出第一主成分中以0為臨界值,0.1為修正值,即(-0.1,0.1)為不穩(wěn)定狀態(tài),此狀態(tài)下的就診人員將隨機(jī)被確定為患者和健康者中的1個(gè)。而當(dāng)F1>0.1時(shí),將此時(shí)對應(yīng)的就診人員確定為健康者;當(dāng)F1<-0.1時(shí),將此時(shí)的就診人員確定為患者。經(jīng)此方法判定的患者與健康者與表1中的患者與健康者基本一致,并且與用綜合主成分分析得到的結(jié)果基本一致。其判定的準(zhǔn)確性可以達(dá)到95%以上,因此具備很強(qiáng)的可信性與科學(xué)性。
本文創(chuàng)新點(diǎn)在于模型中連續(xù)做了2次主成分分析,即二次主成分分析,并伴有大量的數(shù)據(jù)處理和數(shù)據(jù)分析,合理的結(jié)論背后擁有強(qiáng)大的理論支持和數(shù)據(jù)支持,具有很強(qiáng)的科學(xué)性和可信性。不過,確診病人還是需要通過醫(yī)生的具體分析,以達(dá)到所需效果。