
MP3是MPEG-1國(guó)際標(biāo)準(zhǔn)中音頻壓縮層3的簡(jiǎn)稱,,單聲道比特率一般取64kbps,在采樣率44.1kHz的情況下,,其壓縮比可達(dá)12倍以上,,被廣泛應(yīng)用于互聯(lián)網(wǎng)等許多場(chǎng)合。由于解碼比編碼過程簡(jiǎn)單很多,,MP3播放機(jī)或隨身聽已隨處可見,但MP3編碼在單片機(jī)定點(diǎn)DSP上實(shí)現(xiàn),,并要保證音質(zhì),,則鮮有耳聞??紤]到心理聲學(xué)模型在整個(gè)MP3音頻編碼算法中所占比例巨大,,筆者從簡(jiǎn)化該模型入手,采用快速算法減少了帶編碼的運(yùn)算量和數(shù)據(jù)量,,盡可能少量化編碼的迭代循環(huán)次數(shù),,從而在一片美國(guó)德州儀器公司的TMS320C549芯片上實(shí)現(xiàn)了MP3的實(shí)時(shí)壓縮,,用標(biāo)準(zhǔn)解碼軟件回放,主觀評(píng)定,,對(duì)于通常的音頻能達(dá)到接近CD的音質(zhì),。

1 MP3編碼算法及處理
圖1是MP3編碼器的系統(tǒng)方框圖。每聲道以1152個(gè)采樣值為一幀進(jìn)行處理,。首先,,分析子帶濾波器采用正交鏡像濾波器組,將20kHz左右?guī)挼男盘?hào)劃分成相等帶寬的32個(gè)子帶,。然后對(duì)子樣值作MDCT以補(bǔ)償子帶濾波的不足,,主要是為提高頻率分辨率、消除由子帶濾波引起的帶間混迭,。 同時(shí)采樣值通過心理聲學(xué)模型計(jì)算出各頻帶的掩蔽閾值,。
失真控制循環(huán)和非歸一化量化控制循環(huán)是量化編碼循環(huán)過程,它通過量化減少各MDCT系數(shù)的精度,,使編碼比特?cái)?shù)得以降低,。不同系數(shù)采用不同的量化階,從耳敏感的頻率量化精度高,,不敏感的頻率量化精度低,,量化誤差則不會(huì)被人耳察覺。選擇量化階的依據(jù)就是心理聲學(xué)模型計(jì)算出的掩蔽閥值,。
最后將量化階等信息以及霍夫曼碼打包成比特流,,供解碼用。
那么為什么掩蔽閾值能反映人耳的聽覺特點(diǎn)呢,?
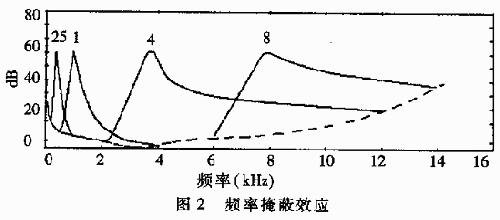
人耳的聽覺特性涉及生理聲學(xué)和心理聲學(xué)方面的問題,。例如人耳對(duì)不同頻率的聲音感覺不同就是生理方面的問題,其中對(duì)2kHz~4kHz的聲音最敏感,,且低頻較高頻敏感,。敏感程度具體體現(xiàn)為靜態(tài)掩蔽閾值,如圖2虛線所示,,表示在安靜的情況下,,各種頻率的聲音剛好被聽到的音量。與人的心理知覺有關(guān)的有掩蔽效應(yīng)等,。掩蔽效應(yīng)指一個(gè)聲音的聽覺感受受到另一個(gè)聲音影響的現(xiàn)象,,分為時(shí)間掩蔽(前向、后向掩蔽)和頻率掩蔽(同時(shí)掩蔽),。例如,,當(dāng)一個(gè)較強(qiáng)的聲音停止后,要過一會(huì)兒才能聽到另一個(gè)較強(qiáng)的聲音,,這就是時(shí)間掩蔽效應(yīng),。頻率掩蔽是指一個(gè)聲音對(duì)與其同時(shí)存在的臨近頻率的聲音產(chǎn)生的影響,,如圖2實(shí)線所示。其中標(biāo)志1的實(shí)線表示:當(dāng)1kHz的掩蔽聲音為60dB時(shí),,不同頻率的聲音剛好被聽到的分貝值,,可見越臨近頻率被掩蔽得越厲害,且低頻更易掩蔽高頻,。
因此心理聲學(xué)模型就先用FFT分析信號(hào)中包含的頻率分量,,將每個(gè)頻率處受到其他所有頻率分量掩蔽的值加起來,連線得到的曲線就是掩蔽閾值,,是頻率的函數(shù),。當(dāng)某頻率分量的能量處曲線下方時(shí),不能被人耳感覺到,,則該頻率分量可用零比特編碼,;另一方面,選擇量化階時(shí)若能保證量化噪聲低于掩蔽曲線,,也不被人耳察覺,,所以掩蔽值越大的頻率分量量化階可以越大。因此用掩蔽閾值作為量化編碼的依據(jù),,就能夠信證壓縮后的聲音質(zhì)量,。由于聲音信號(hào)隨時(shí)間改變,因此每幀信號(hào)都要計(jì)算兩次心理聲學(xué)模型,,其中要用到大量的實(shí)驗(yàn)測(cè)試數(shù)據(jù),,運(yùn)算量之在是可想而知的。
2 算法的簡(jiǎn)化和優(yōu)化
2.1 分析子帶濾波器的快速算法
分析子帶濾波器的輸入是32個(gè)采樣值,,輸出是32個(gè)頻率等間隔的子帶樣值,。它首先將32個(gè)采樣值放入一個(gè)長(zhǎng)度512的先進(jìn)先出(FIFO)緩存;對(duì)該緩存加窗,;然后512個(gè)緩存中每8個(gè)值累加,,轉(zhuǎn)換成64個(gè)中間值;最后通過(1)或?qū)?4個(gè)中間值變換成32個(gè)采樣值:
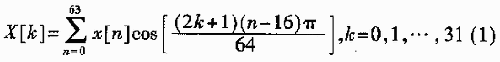
尋找快速算法的關(guān)鍵就是這最后一步,。將系數(shù)設(shè)數(shù)組:

可以發(fā)現(xiàn)該數(shù)組具有如下的對(duì)稱性: c[16+n]=c[16-n],n=0,1,…,,16 (3) c[48+n]=-c[48-n],n=0,1,…,15 (4) 所以合并系數(shù)相等或相反的項(xiàng),,(1)式變成:

其中,, 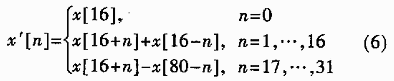
可見用(5)式代替(1)式可以減少一半的乘法運(yùn)算。又發(fā)現(xiàn)(5)式和標(biāo)準(zhǔn)的IDCT非常相似,,可以將Lee提出的快速IDCT算法稍加改動(dòng)推導(dǎo)(5)式的快速算法。所以又將32點(diǎn)變換分解成以下的兩個(gè)16點(diǎn)變換: 
其中,,
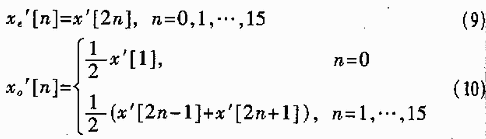
最終的子帶樣值是如下的蝶形組合: X[K]=Xe[k]+(1/cos[(2k+1)π/64]Xo[k],k=0,1,…,,15 (11) X[31-k]=Xe[k]-(1/cos[(2k+1)π/64])Xo[k],k=0,1,…,,15 (12) 直接計(jì)算(1)式需要32次乘法和32次加法,采用快速算法需2次乘法和15次加法,,運(yùn)算量原來的1/4,,而且數(shù)據(jù)表格所占用的存儲(chǔ)空間也減少為原來的1/8左右。
2.2 心理聲學(xué)模型的簡(jiǎn)化
根據(jù)試驗(yàn)觀察發(fā)現(xiàn)每幀的掩蔽閾值曲線大致相同,,所以考慮采用靜態(tài)聲學(xué)心理模型,,具體做法是:首先對(duì)某一具有代表性的音頻幀,
根據(jù)心理聲學(xué)模型計(jì)算出掩蔽閾值曲線,,在壓縮其它音頻源時(shí),,不再計(jì)算每幀的心理聲學(xué)模型,而是認(rèn)為每幀信號(hào)與上述被分析過的代表幀具有相同的掩蔽特性,。這樣,,雖然不是很準(zhǔn)確,但通常情況下,,誤差不會(huì)太大,,不易被人耳察覺,省去心理學(xué)模型需的巨大運(yùn)算量和存儲(chǔ)空間,。實(shí)踐證明編碼效果令人滿意,,而且對(duì)于要求不是很高的應(yīng)用場(chǎng)合,可以認(rèn)為掩蔽閾值是頻率的常數(shù)函數(shù),,每個(gè)頻帶采用相同的量化階,,也聽不出聲音質(zhì)量的明顯下降。
2.3 量化編碼迭代循環(huán)的簡(jiǎn)化
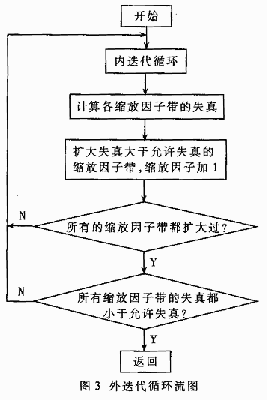
量化編碼迭代是兩重循環(huán)過程,,圖3是外迭代循環(huán)流圖,,迭代的目的是在可用比特?cái)?shù)的限制之內(nèi),以各頻帶的掩蔽值為依據(jù),,確定全局增益(體現(xiàn)了全局量化階)和各頻帶的縮放因子(體現(xiàn)了局部量化階),。內(nèi)循環(huán)逐步增加量化器步長(zhǎng),即全局增益,,直到MDCT系數(shù)量化后可被可用比特進(jìn)行霍夫曼編碼,,即通過增加全局量化階以降低編碼比特?cái)?shù);外循環(huán)依據(jù)掩蔽閾值檢測(cè)各縮放因子帶的失真,,若超過允許失真,,則擴(kuò)大該帶的MDCT系數(shù),即增大該帶的縮放因子,,以降低局部失真,;最后一次迭代的結(jié)果作為最終的霍夫曼碼。每一次循環(huán)都要用當(dāng)前量化階量化并霍夫曼編碼一次,,運(yùn)算量相當(dāng)大,。從外循環(huán)可以看出掩蔽閾值最終決定縮放因子,,為了能省去外控代循環(huán),將代表幀的縮放因子作成表格,,供每幀采用,。 由于上述三個(gè)模塊是最主要并且運(yùn)算量最大的模塊,通過對(duì)它們的簡(jiǎn)化和優(yōu)化,,程序大小和運(yùn)算量可得到極大的減少,。
3 用定點(diǎn)DSP實(shí)現(xiàn)MP3壓縮算法
為了實(shí)現(xiàn)MP3的實(shí)時(shí)編碼,必須采用高速DSP芯片,。采用美國(guó)德州儀器(TI)公司的主流定點(diǎn)DSP芯片TMS320C549,,其運(yùn)算速度100MIPS,調(diào)試開發(fā)的環(huán)境是TI公司的第三方Spectrum Digital公司的EVM評(píng)估板,,板上除了TMS320C549自帶32K字片上內(nèi)存外,,還有128K字片外內(nèi)存,數(shù)模轉(zhuǎn)換采用TI的TLC320AD55,,與PC機(jī)通過JTAG口實(shí)現(xiàn)數(shù)據(jù)與程序的加載和調(diào)試,。 由于評(píng)估板與主機(jī)的接口速度太慢,即使能做到實(shí)時(shí)壓縮,,將比特流傳給PC機(jī)存盤的速度也會(huì)跟不上,。因此筆者采用的辦法是:將原始PCM音頻數(shù)據(jù)從PC機(jī)的硬盤文件加載到板上的片外內(nèi)存,壓縮后的數(shù)據(jù)傳給PC機(jī)存盤,,再加載后續(xù)文件,,壓縮存盤,直到整個(gè)音頻文件全部壓縮完,,最后用C語言程序?qū)⒏鲾?shù)據(jù)塊拼成MP3文件,,用軟件解碼程序回放。是否能達(dá)到實(shí)時(shí)要求只能通過測(cè)試每幀運(yùn)行的指令數(shù)判斷,。
在運(yùn)用快速算法計(jì)算子帶分析濾波器時(shí),,考慮到DSP芯片的特點(diǎn),每分解一次,,要作一次加(10)式的加法,,勢(shì)必降低精度,另外(11)和(12)式的系數(shù)動(dòng)態(tài)范圍太大,,精度也會(huì)受到影響,,因此,只分解到16點(diǎn)DCT運(yùn)算,。
采用靜態(tài)心理聲學(xué)模型,,心理聲學(xué)模型和量化編碼外循環(huán)所需的運(yùn)算量就為零。代表幀的心理聲學(xué)模型和縮放因子采用C語言或MATLAB語言編程計(jì)算,或者將網(wǎng)上下載MP3文件中的縮放因子信息破譯出來加以利用,,子帶分析濾波器之后的MDCT全部采用長(zhǎng)塊,。表1是靜態(tài)縮放因子比特?cái)?shù)和縮放因子的一種設(shè)置方案。 表1 縮放因子數(shù)據(jù)表格 縮放因子帶 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 縮放因子比特?cái)?shù) 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 縮放因子 1 1 0 0 1 1 4 5 3 7 5 3 0 3 0 1 0 7 5 0 3 另外在內(nèi)循環(huán)中,,首先初步選擇一個(gè)全局增益使最大量化值小于碼表可編碼的最大值,標(biāo)準(zhǔn)推薦的作法是全局增益從小開始,,每循環(huán)一次量化后,,比較最大量化值,并調(diào)整一次全局增益,,直到滿足要求為止,。本程序省去了這一循環(huán),事先根據(jù)最大譜線值計(jì)算出應(yīng)有的全局增益,,作成數(shù)據(jù)表格,,程序中只需根據(jù)最大譜線值查表即可。初始化全局增益確定后,,要分區(qū),、量化、編碼并計(jì)算編碼比特?cái)?shù),,如果比特?cái)?shù)太大或太小都還要調(diào)整全局增益,。對(duì)這一迭代循環(huán)過程,采用折半搜索的辦法實(shí)現(xiàn),,也就是說第一次循環(huán)時(shí)全局增益取上述初始化值的一半,,若編碼比特?cái)?shù)超出要求,則再取一半作為新的全局增益,,否則增大一半,,如此不斷循環(huán)直到無法折半為止。這種折半搜索的方法比逐一搜索要快很多,。 采用了這些簡(jiǎn)化,、優(yōu)化措施以及編程技巧,整個(gè)編碼程序運(yùn)算量?jī)H需74MIPS左右,,片上存儲(chǔ)空間占用27K字左右,。用標(biāo)準(zhǔn)的MP3回放軟件解碼,通過主觀測(cè)評(píng),,音質(zhì)接收CD,。
由于本系統(tǒng)對(duì)心理聲學(xué)模型進(jìn)行了大量的簡(jiǎn)化,對(duì)于一般的音樂,,這種簡(jiǎn)化帶來的聲音質(zhì)量的下降并不明顯,,尤其是在要求不高的應(yīng)用場(chǎng)合完全可行。但是當(dāng)應(yīng)用到某些編碼難度較高的音頻信號(hào),例如響板時(shí),,聲音質(zhì)量下降較明顯,。因此如果采用更高運(yùn)算速度的DSP,可在該編碼系統(tǒng)中加入一個(gè)完備的或簡(jiǎn)化的動(dòng)態(tài)心理聲學(xué)模型,,編碼質(zhì)量可進(jìn)一步提高,,至于簡(jiǎn)化的動(dòng)態(tài)心理聲學(xué)模型還有待進(jìn)一步摸索。