
介紹
隨著消費(fèi)者對(duì)智能電話需求的日益增長以及無線平板電腦的廣泛普及,當(dāng)今的移動(dòng)因特網(wǎng)需要連接越來越多的用戶,從而要求移動(dòng)網(wǎng)絡(luò)實(shí)現(xiàn)顯著的容量增長。長期演進(jìn)(4GLTE)能夠以更低的成本提供更高的頻譜效率與更大的容量。不斷演進(jìn)的LTE-Advanced(LTE-A)能夠可實(shí)現(xiàn)具有更高帶寬、更強(qiáng)吞吐能力與更高級(jí)天線技術(shù)的異構(gòu)網(wǎng)絡(luò)。同時(shí),WCDMA標(biāo)準(zhǔn)也在不斷演進(jìn)發(fā)展,具有更高的帶寬以及更強(qiáng)大的吞吐能力。毋庸置疑,市場需要推出多標(biāo)準(zhǔn)title="基站" target="_blank">基站。其結(jié)果是,部署在基站中的片上系統(tǒng)(SoC)器件不僅需要支持LTE,還需要同時(shí)支持WCDMA及其它原有標(biāo)準(zhǔn)。作為當(dāng)今無線基站部署所采用無線基站SoC的領(lǐng)先供應(yīng)商,德州儀器(TI)在該市場領(lǐng)域擁有長期成功的歷史。在本白皮書中,我們將與大家分享我們10余年積累的“學(xué)習(xí)周期”體驗(yàn)和我們最新開發(fā)的無線基站SoC——TMS320CTCI6616和TMS320CTCI6618。
10年凝練精湛的基站專業(yè)技能
自無線網(wǎng)絡(luò)誕生以來,其數(shù)據(jù)吞吐能力已實(shí)現(xiàn)快速增長。對(duì)營運(yùn)商來說,最終的衡量標(biāo)準(zhǔn)是頻譜每赫茲承載的比特?cái)?shù),以及實(shí)現(xiàn)特定吞吐能力所需的相關(guān)成本及功耗。一直以來,在無線標(biāo)準(zhǔn)升級(jí)的每一個(gè)轉(zhuǎn)折點(diǎn),TI都無一不為基站設(shè)備帶來價(jià)值與創(chuàng)新。如今,TI的基站SoC只需少量電路系統(tǒng)即可處理無線基帶第1層(L1)、第2層(L2)與傳輸功能。TI10余年的豐富經(jīng)驗(yàn)建立在成功的部署周期之上,主要體現(xiàn)在在以下方面積累的豐富知識(shí):
1.TI在最新的半導(dǎo)體工藝技術(shù)節(jié)點(diǎn)上成功推出眾多器件,不僅能夠?qū)崿F(xiàn)顯著的性能提升,同時(shí)還能大幅降低成本及功耗;
2.TI在DSP技術(shù)領(lǐng)域擁有穩(wěn)固的領(lǐng)先地位。毋庸置疑,無線基站需要為全球無線標(biāo)準(zhǔn)的傳輸與接收提供充分的數(shù)字信號(hào)處理能力。TI擁有強(qiáng)大的實(shí)力,能夠利用其行業(yè)領(lǐng)先的半導(dǎo)體工藝技術(shù)持續(xù)推出數(shù)字處理性能不斷飛速發(fā)展的未來產(chǎn)品。各種優(yōu)勢(shì)全面結(jié)合,即能為市場推出高性價(jià)比的解決方案;
3.TI始終致力于改進(jìn)其高性能多內(nèi)核SoC。雖然無線基站的大多數(shù)功能都能夠由DSP執(zhí)行,但DSP最為擅長的則是與目標(biāo)加速器相結(jié)合來實(shí)現(xiàn)各種優(yōu)化目標(biāo),其中包括實(shí)現(xiàn)極高的單位頻率吞吐能力、單位功率吞吐能力以及低系統(tǒng)成本等。在將硬件加速與業(yè)界領(lǐng)先DSP相結(jié)合以減輕無線標(biāo)準(zhǔn)的處理方面,TI極為成功,能夠以極低的成本與低功耗實(shí)現(xiàn)前所未有的吞吐能力。
TI基站創(chuàng)新的第三個(gè)主要部分是本文的重點(diǎn)所在,即TI為基站SoC創(chuàng)建可配置硬件加速器的成功戰(zhàn)略。在決定將無線信號(hào)處理鏈上的哪些部分轉(zhuǎn)移到可配置硬件加速模塊中時(shí),有若干關(guān)鍵問題需要考慮,其中包括:
1.無線信號(hào)鏈的哪些部分發(fā)生重大變化的可能性最小,而且哪些應(yīng)基于成熟的標(biāo)準(zhǔn)之上?
2.在候選功能中,設(shè)備制造商能否添加其自己的知識(shí)產(chǎn)權(quán)(IP),以提供高級(jí)功能與差異化?
3.無線信號(hào)鏈上的哪個(gè)部分具有最高的處理強(qiáng)度(如果在DSP的軟件中實(shí)施時(shí),需要最高的DSPMIPS)?
4.分配在硬件中的哪些功能可以簡化并加快開發(fā)與測(cè)試?
5.為確保全面的多內(nèi)核能力與峰值加速器性能,需要何種類型的SoC基礎(chǔ)局端?
要解決上述的第一個(gè)問題,需要確保無線處理標(biāo)準(zhǔn)的這些部分(無論仍處于開發(fā)中還是處于實(shí)驗(yàn)階段)都將由DSP負(fù)責(zé)處理,這樣營運(yùn)商或OEM廠商才能實(shí)現(xiàn)解決方案的差異化。在對(duì)各種信號(hào)鏈功能及使用模型的MIPS要求進(jìn)行分析后,就可以確定哪些功能應(yīng)被移入硬件加速器,從而在降低成本和加快投產(chǎn)進(jìn)度方面獲得顯著優(yōu)勢(shì)。
除了各種基于硬件的加速器外,TI還創(chuàng)建了一種可確保實(shí)現(xiàn)高效率零復(fù)制數(shù)據(jù)流的創(chuàng)新型KeyStone架構(gòu),從而能夠在內(nèi)核、加速器以及外設(shè)之間實(shí)現(xiàn)非阻塞的系統(tǒng)互連。此外,該架構(gòu)還能確保協(xié)處理器得到充分利用。它還可以減少中斷及軟件上下文環(huán)境的切換次數(shù),以最大限度地實(shí)現(xiàn)所有內(nèi)核的最佳利用,從而使所有系統(tǒng)組件都能得到全面利用。
確定系統(tǒng)優(yōu)化的機(jī)會(huì)
確定新基站SoC設(shè)計(jì)方法的第一步,是考慮新一代基站的預(yù)期性能要求并理解其對(duì)SoC設(shè)計(jì)的影響。
TCI6618具備一系列針對(duì)新一代基站的用例目標(biāo)參數(shù)。由于TITCI6488是目前應(yīng)用于基站的領(lǐng)先SoC,因而其是一種非常適用于基線分析的器件。
下列各參數(shù)基于LTE系統(tǒng)中TCI6488器件的性能:
l天線:2x2發(fā)送與接收
l帶寬:20MHz
l數(shù)據(jù)率:150Mbps下行,75Mbps上行
LTE物理層概覽
LTE物理層需要對(duì)每個(gè)物理層通道進(jìn)行高強(qiáng)度的信號(hào)處理。主要的物理層通道如下:
下行通道:
lPDSCH:物理下行共享通道
lPDCCH:物理下行控制通道
上行通道:
lPUSCH:物理上行共享通道
lPUCCH:物理上行控制通道
lPRACH:物理隨機(jī)訪問通道
對(duì)于每個(gè)數(shù)據(jù)和控制通道而言,可將物理層處理分為兩個(gè)主要的功能模塊:比特率與IQ采樣處理。
圖1顯示的PDSCH信號(hào)鏈由如下方面構(gòu)成:
IQ采樣處理—處理LTE物理資源,將其映射到天線的不同層并轉(zhuǎn)換為OFDM符號(hào)以用于空中傳輸。
比特率處理—處理來自L2的傳輸模塊,通過計(jì)算循環(huán)冗余校驗(yàn)(CRC)并將其附加給傳輸模塊來啟動(dòng)處理進(jìn)程。如果傳輸模塊大于6,144位的最大允許代碼模塊尺寸,則執(zhí)行代碼模塊分段。在進(jìn)行通道編碼前,要進(jìn)行新的CRC計(jì)算并將其附著于每個(gè)代碼模塊上。
圖1介紹了LTE下行鏈路中的主要功能模塊。
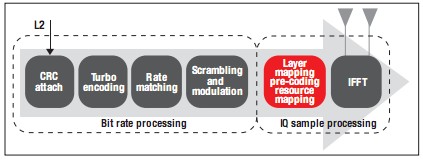
圖1-FDSCH信號(hào)處理鏈
PUSCH是PDSCH的反向過程,同樣含有下列IQ樣本與比特率處理:
IQ樣本處理——處理接收到的OFDM符號(hào)物理資源。這涉及通道估算與最大比率合并(MRC)/多輸入、多輸出(MIMO)均衡,以從各個(gè)天線分離用戶數(shù)據(jù)。
比特率處理——為在L2內(nèi)實(shí)現(xiàn)進(jìn)一步處理而進(jìn)行的通道解調(diào)、解多路復(fù)用、錯(cuò)誤校正與解碼。
圖2所示為PUSCH的信號(hào)處理鏈:
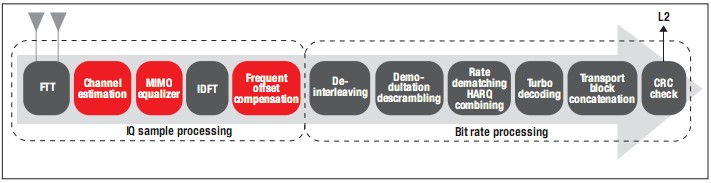
圖2-PUSCH信號(hào)處理鏈
分析TMS320TCI6488中的LTE物理層處理
TCI6487/8是TI最新系列的多內(nèi)核SoC,由三個(gè)C64x+TMCPU內(nèi)核構(gòu)成。采用這種SoC的運(yùn)營商已有數(shù)百家,年出貨量數(shù)百萬片。通過分析TCI6488的LTE性能,可以深入了解如何構(gòu)建新一代的高性能SoC。圖3所示為在TCI6488上采用2x2MIMO、150Mbps下行吞吐速率及75Mbps上行吞吐速率時(shí),20MHzLTE的周期占用數(shù)及分布。
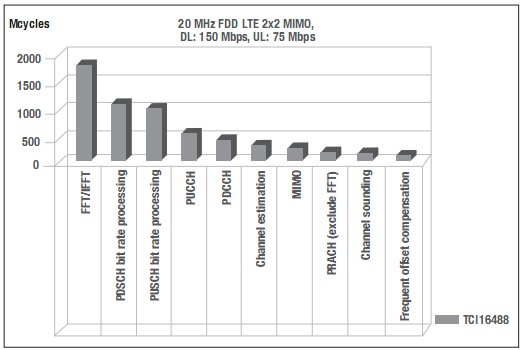
圖3-TCI6488上的LTE物理層處理
從圖上可以明顯看出,F(xiàn)FT/IFFT、PDSCH比特率處理、PUSCH比特率處理與PUCCH占用了總DSP周期中的大部分。
為進(jìn)一步改進(jìn)總體系統(tǒng)性能,滿足新一代LTE系統(tǒng)的要求,必須設(shè)計(jì)出具備良好均衡性且可擴(kuò)展的架構(gòu),以便最大限度地發(fā)揮SoC的多內(nèi)核計(jì)算性能。這就要求最大限度地提高系統(tǒng)的互連吞吐量,并將存儲(chǔ)器存取與數(shù)據(jù)傳輸時(shí)延降到最小。
通過對(duì)LTE要求的總處理周期進(jìn)行分析,我們發(fā)現(xiàn)通過增強(qiáng)DSP內(nèi)核的信號(hào)處理能力,不僅能夠減少處理周期的總數(shù)量,而且還能增大系統(tǒng)容量、提升性能。最新推出的C66xDSP內(nèi)核通過將C64x+的乘/累加(MAC)能力銳升四倍可實(shí)現(xiàn)這一目標(biāo)。此外,新內(nèi)核還同時(shí)集成了定點(diǎn)與浮點(diǎn)功能,并可為矢量處理與矩陣處理提供新的指令。
如快速傅里葉變換(FFT)與快速傅里葉逆變換(IFFT)等特定函數(shù)需要在LTE信號(hào)鏈上的許多地方執(zhí)行,并且用于在時(shí)域與頻域之間進(jìn)行數(shù)據(jù)轉(zhuǎn)換。FFT與離散傅立葉變換(DFT)已屬成熟算法,因此它們有可能作為硬件加速的候選以用于釋放CPU周期,這樣DSP內(nèi)核就可用于執(zhí)行客戶差異化功能。
LTE的上行與下行比特率處理及其他無線技術(shù)包含眾多標(biāo)準(zhǔn)算法,適用于調(diào)制、解調(diào)、交錯(cuò)、解交錯(cuò)、速率匹配、解速率匹配、加擾與去擾等運(yùn)算。TI新型比特率協(xié)處理器(BCP)是一種可為多種標(biāo)準(zhǔn)釋放所有比特率處理功能的加速器,它可大幅度提升系統(tǒng)容量,從而簡化軟件編程、減少系統(tǒng)時(shí)延。
這些就是可以在TCI6616及TCI6618基站SoC中實(shí)現(xiàn)創(chuàng)新與性能飛躍提升的系統(tǒng)優(yōu)化機(jī)會(huì)的示例。
TIKeyStone架構(gòu)
KeyStone多內(nèi)核SoC架構(gòu)是業(yè)界同類架構(gòu)中率先可提供基礎(chǔ)局端以確保所有內(nèi)核都能得到充分利用的架構(gòu)。KeyStone可實(shí)現(xiàn)對(duì)所有處理內(nèi)核、外設(shè)、協(xié)處理器及I/O的非阻塞訪問。可實(shí)現(xiàn)這類多內(nèi)核能力的部分KeyStone創(chuàng)新技術(shù)包括:多內(nèi)核導(dǎo)航器、TeraNet、多內(nèi)核共享存儲(chǔ)控制器(MSMC)及超鏈接。
TI多內(nèi)核導(dǎo)航器是一種基于分組的創(chuàng)新型管理器,能夠在提取不同子系統(tǒng)間連接的同時(shí),控制8,192個(gè)隊(duì)列。它可為實(shí)現(xiàn)通信、數(shù)據(jù)傳輸及工作管理提供統(tǒng)一接口。通過采用“一次性完成,零復(fù)制”的設(shè)計(jì)理念,多內(nèi)核導(dǎo)航器能夠以更少的中斷及更低的軟件復(fù)雜度實(shí)現(xiàn)更高的系統(tǒng)性能。
舉例來說,多內(nèi)核導(dǎo)航器能夠進(jìn)行任務(wù)調(diào)度,且在無需外部管理的情況下即能指示下一個(gè)空閑DSP內(nèi)核讀取并處理任務(wù)。這樣通過提供下列功能,即可簡化SoC軟件架構(gòu),進(jìn)而提升基站的性能:
l動(dòng)態(tài)資源/負(fù)載共享
l減輕與子系統(tǒng)間通信相關(guān)的CPU開銷/延遲
l基于硬件的任務(wù)優(yōu)先級(jí)排序
l動(dòng)態(tài)負(fù)載平衡
l針對(duì)所有IP模塊(軟件、I/O及加速器)的通用通信方法
多內(nèi)核導(dǎo)航器能夠在無CPU干預(yù)的情況下控制數(shù)據(jù)流,可從移動(dòng)數(shù)據(jù)中釋放CPU周期并將片上通信速率提升至每秒2,000萬條消息。此外,其還能夠使用更為簡單的軟件架構(gòu)以縮短開發(fā)周期并提高資源利用率。
TeraNet能夠提供層級(jí)交換結(jié)構(gòu),可在SoC內(nèi)為數(shù)據(jù)傳輸提供超過2Tbit的總帶寬。這樣幾乎可確保不會(huì)出現(xiàn)內(nèi)核與協(xié)處理器沒有數(shù)據(jù)可處理的情況,從而使他們?cè)谌魏涡枰奈恢煤蜁r(shí)間都可以發(fā)揮其最大的處理功效。由于交換結(jié)構(gòu)采用了層級(jí)架構(gòu)而非扁平縱橫式結(jié)構(gòu),因此總體功耗能在空閑狀態(tài)下實(shí)現(xiàn)大幅度下降且能以最低時(shí)延實(shí)現(xiàn)高性能,從而充分滿足新一代基站的這種關(guān)鍵要求。
多內(nèi)核共享存儲(chǔ)控制器(MSMC)是一種可增強(qiáng)性能的獨(dú)特架構(gòu)。MSMC可以讓內(nèi)核在不占用任何TeraNet帶寬的情況下直接訪問共享存儲(chǔ)器。MSMC可以協(xié)調(diào)內(nèi)核及其他IP模塊對(duì)共享存儲(chǔ)器的訪問,以避免發(fā)生存儲(chǔ)器爭用的情況發(fā)生。DDR3外部存儲(chǔ)器接口(EMIF)可直接連接至MSMC,從而降低因發(fā)生外部存儲(chǔ)器存取而導(dǎo)致的時(shí)延,并為基站應(yīng)用提供所需的高速訪問與支持。
超鏈接具有50Gbps的總吞吐能力,是一種互連機(jī)制,能夠以極少的協(xié)議實(shí)現(xiàn)與其它KeyStone、FPGA及ASIC器件的高速通信與連接。其可為主器件上的配套器件提供透明的存儲(chǔ)器映射訪問,從而不僅可大幅簡化軟件編程,同時(shí)還能為OEM廠商提供實(shí)現(xiàn)可擴(kuò)展解決方案的無縫路徑。
全新DSP內(nèi)核
TCI66xSoC解決方案包含性能顯著增強(qiáng)的全新處理內(nèi)核。其是業(yè)界首款同時(shí)集成了定點(diǎn)和浮點(diǎn)功能的基站DSP內(nèi)核。增強(qiáng)的性能可幫助OEM廠商構(gòu)建極富差異化功能的軟件,從而滿足高級(jí)操作人員的要求。
TMS320C66x內(nèi)核
作為TI的新一代定點(diǎn)及浮點(diǎn)DSP,新型C66x內(nèi)核具備集成了8個(gè)功能單元和64個(gè)通用32位寄存器的高級(jí)VLIW架構(gòu)。全新系列器件基于TI前代C64x+內(nèi)核架構(gòu)之上,擁有屢獲殊榮的指令集架構(gòu)和眾多功能強(qiáng)大的特性,如每個(gè)周期能夠執(zhí)行8個(gè)指令,從而可實(shí)現(xiàn)高度的并行性能。
全新的C66xDSP內(nèi)核實(shí)現(xiàn)眾多特性改進(jìn),其中包括:
l原生浮點(diǎn)處理,可逐指令地與定點(diǎn)實(shí)現(xiàn)無縫協(xié)作。通過以業(yè)界領(lǐng)先的定點(diǎn)DSP速度提供原生浮點(diǎn)支持,實(shí)現(xiàn)了浮點(diǎn)處理領(lǐng)域的重大進(jìn)步;
lMAC實(shí)現(xiàn)了4倍的性能提升,每周期可提供32個(gè)16x16位MAC;
l專為復(fù)雜算法、線性代數(shù)和矩陣運(yùn)算而精心優(yōu)化;
l全流水線雙精度浮點(diǎn)乘法器;
l減少雙精度乘法時(shí)延。
所有這些改進(jìn)都能大幅提升L1和L2的總體處理性能。4G基站解決方案具備MIMO和波束成形等算法,可充分利用多天線信號(hào)處理實(shí)現(xiàn)性能提升。這些算法通常需要矩陣逆轉(zhuǎn)技術(shù),從本質(zhì)上來說非常容易遭受與定點(diǎn)處理相關(guān)的量化及擴(kuò)展問題的影響。這些多天線技術(shù)仍在不斷演進(jìn)發(fā)展,具備可幫助客戶實(shí)現(xiàn)差異化功能的實(shí)施靈活性至關(guān)重要。將最新的C66x增強(qiáng)功能用于矩陣運(yùn)算和浮點(diǎn)支持,能夠同時(shí)顯著提高系統(tǒng)的速度和準(zhǔn)確度,從而為移動(dòng)電話用戶帶來更精彩的體驗(yàn)。
采用C66x內(nèi)核增強(qiáng)MIMO接收機(jī)
我們同時(shí)在LTE和LTE-A中采用了眾多高級(jí)接收機(jī)算法。例如,在LTE-A新技術(shù)中可實(shí)現(xiàn)更先進(jìn)的多用戶MIMO(MU-MIMO)預(yù)編碼方案。此外,單用戶MIMO(SU-MIMO)還可支持更高的數(shù)據(jù)速率。增強(qiáng)型C66x內(nèi)核不僅可幫助設(shè)計(jì)團(tuán)隊(duì)在上述領(lǐng)域?qū)崿F(xiàn)差異化特性,而且最終還能幫助他們實(shí)現(xiàn)操作人員所需的高級(jí)特性。
MIMO解碼在算法上非常復(fù)雜,往往需要使用客戶IP來提升效率和性能。復(fù)雜度隨天線數(shù)量的增加而相應(yīng)增加。雖然大多數(shù)專家都一致認(rèn)為第二種傳輸天線至少在最近幾年都不會(huì)獲得廣泛使用,但當(dāng)前的系統(tǒng)仍以2xN(2路傳輸,N路接收)配置為主。實(shí)施MIMO接收機(jī)算法的方式有很多種,其中包括較低復(fù)雜側(cè)的線性MMSE和較高復(fù)雜端的球狀解碼。在OEM廠商測(cè)試不同算法的時(shí)候,進(jìn)行高效率的軟件實(shí)施使他們能夠在部署LTE系統(tǒng)的同時(shí)適配并測(cè)試不同的構(gòu)想方案。這種高靈活性在基礎(chǔ)局端部署的最初幾年非常關(guān)鍵,直到新的網(wǎng)絡(luò)落實(shí),工程師才能更好地理解問題所在。
C66x架構(gòu)具備擴(kuò)展指令集,可用于加速DSP內(nèi)核的MIMO處理。浮點(diǎn)可以實(shí)現(xiàn)高效的矩陣反轉(zhuǎn)算法,從而較定點(diǎn)實(shí)施相比能夠?qū)崿F(xiàn)更高的性能,而且與硬件加速相比能夠?qū)崿F(xiàn)更高的靈活性。通過充分發(fā)揮浮點(diǎn)功能和4倍的MAC性能改進(jìn),C66xDSP內(nèi)核中的MIMO處理量與前代DSP相比降低了5倍。
全新的加速功能
通過分析LTE和WCDMA系統(tǒng)要求,我們已確定了一些需要改進(jìn)的功能,并按重要性進(jìn)行如下排序:
lFFT/IFFT/DFT
l下行鏈路比特率處理
l上行鏈路比特率處理
l上行鏈路控制通道接收機(jī)
lMIMO接收機(jī)
lWCDMA傳輸碼片率IQ采樣處理(TAC)
lWCDMA接收碼片率IQ采樣處理(RAC)
此外,4G較高的數(shù)據(jù)速率和高速3G系統(tǒng)都需要大量的改進(jìn)才能完成turbo解碼功能。
TCI6616AcceleraTIonPacs
為了更好地滿足高速發(fā)展的3G和4G市場需求,TI為TCI6616開發(fā)了眾多新的加速器。
傳輸碼片率協(xié)處理器(TAC)
TAC能為多達(dá)256個(gè)下行鏈路WCDMA用戶執(zhí)行傳輸碼片率擴(kuò)展運(yùn)算。該加速器可將符號(hào)率處理的數(shù)據(jù)作為輸入,然后再將芯片擴(kuò)展序列輸出到基站的各個(gè)天線輸出端。
TAC能夠執(zhí)行下列運(yùn)算:
l符號(hào)調(diào)制
l開環(huán)分集處理,其中包括空間時(shí)間傳輸分集(STTD)和時(shí)間交換傳輸分集(TSTD)
l閉環(huán)處理,其中包括閉環(huán)分集、用于HSDPA的MIMO、下行鏈路功率控制、上行鏈路功率控制、隨機(jī)訪問采集指示傳輸、E-DCH相對(duì)授權(quán)和混合ARQ指示傳輸
l各個(gè)通道的增益應(yīng)用
l支持壓縮模式
l擴(kuò)展和加擾
l功耗測(cè)量
l媒體流失調(diào)和延遲
l波束成型
l媒體流匯總
TCA支持所有WCDMA下行鏈路通道:
lP-SCH:主同步通道
lS-SCH:次同步通道
lP-CPICH:主通用導(dǎo)頻通道
lS-CPICH:次通用導(dǎo)頻通道
lP-CCPCH:主通用控制物理通道
lPICH:傳呼指示器通道
lAICH:采集指示器通道
lHS-SCCh:高速共享控制通道
lHS-PDSCH:高速物理下行鏈路共享通道
lE-AGCH:E-DCH絕對(duì)授權(quán)通道
lE-RGCH:E-DCH相對(duì)授權(quán)通道
lE-HICH:E-DCH混合ARQ指示器通道
lMICH:MBMS指示器通道
lDPCH:專用物理通道
lF-DPCH:部分專用物理通道
如RNC和Node-B之間的NBAP(Node-B應(yīng)用部分)協(xié)議所示,TAC可實(shí)現(xiàn)靈活的通道配置和重配置。
接收加速器協(xié)處理器(RAC)RAC能為多達(dá)256個(gè)WCDMA用戶執(zhí)行上行鏈路碼片率解擴(kuò)運(yùn)算。其包含基于矢量的高靈活性可配置關(guān)聯(lián)引擎,能夠支持大量的同步關(guān)聯(lián)。
RAC支持下列模式的運(yùn)算:
lFD:用于生成原始符號(hào)的徑解擴(kuò)
lFT:用于執(zhí)行EOL(過早、按時(shí)、延遲)測(cè)量的徑跟蹤
lFPE:用于執(zhí)行徑干擾關(guān)聯(lián)的徑功耗估算
lPM:在天線上執(zhí)行脈沖響應(yīng)曲線以進(jìn)行徑探測(cè)的路徑監(jiān)控器
lPD:在簽名上執(zhí)行脈沖響應(yīng)曲線以進(jìn)行前導(dǎo)碼檢測(cè)
lSPE:執(zhí)行寬帶媒體流功耗測(cè)算的媒體流功耗估算功能
下面是RAC支持的上行鏈路物理通道:
lDPCCH:專用物理控制通道
lDPDCH:專用物理數(shù)據(jù)通道
lHS-DPCCH:高速專用物理控制通道
lE-DPCCH:增強(qiáng)型專用物理控制通道
lE-DPDCH:增強(qiáng)型專用物理數(shù)據(jù)通道
lPRACH:物理隨機(jī)訪問通道
Turbo解碼器3(TCP3d)
Turbo解碼器3協(xié)處理器(TCP3d)是前代Turbo解碼器2的改進(jìn)版本。TCP3d可支持WCDMA、TD-SCDMA、LTE和WiMAX,是一種在上行鏈路處理中對(duì)Turbo代碼進(jìn)行解碼的可配置外設(shè)。TCP3d的輸入是系統(tǒng)位和校驗(yàn)位的軟決策,而輸出既可為軟決策,也可為硬決策。為了最大限度地減少與使用該協(xié)處理器相關(guān)的開銷,TCP3d可生成Turbo交錯(cuò)表,并能在除執(zhí)行解碼之外還支持基于代碼模塊的CRC計(jì)算。其結(jié)果是TCP3d的開銷比TCP2低7倍。TCP3d在TCI6616上的吞吐量在6次迭代后為389Mbps。
Turbo編碼器(TCP3e)
Turbo編碼器協(xié)處理器3(TCP3e)是用于Turbo代碼編碼的協(xié)處理器,可支持WCDMA、TD-SCDMA、LTE和WiMAX。輸入TCP3e的是信息位,輸出的則是編碼后的系統(tǒng)位和校驗(yàn)位。它支持基于代碼模塊的CRC、turbo編碼和turbo交錯(cuò)表生成,最大吞吐能力為643Mbps。
快速傅立葉轉(zhuǎn)換協(xié)處理器(FFTC)
快速傅立葉轉(zhuǎn)換協(xié)處理器(FFTC)可實(shí)施用于LTE和WiMAX的FFT/iFFT和DFT/iDFT。多內(nèi)核導(dǎo)航器(MulticoreNavigator)使數(shù)據(jù)能夠直接在協(xié)處理器端進(jìn)行輸入和輸出路由,并傳輸?shù)絀/O。此外,其還能執(zhí)行周期性的前綴移除和插入以及頻率轉(zhuǎn)換,從而進(jìn)一步降低DSP上的處理負(fù)載。FFTC的吞吐能力為每秒12.72億個(gè)副載波。
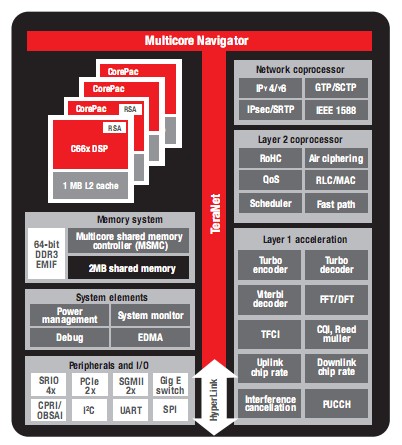
圖4-TCI6616方框圖
全面集成——TCI6616
圖4顯示了TCI6616的方框圖。
TCI6616具有創(chuàng)新型KeyStone架構(gòu)、增強(qiáng)型C66x內(nèi)核并新增了LTE和WCDMA協(xié)處理器,能夠?yàn)闊o線基站應(yīng)用實(shí)現(xiàn)較其他SoC高5倍的性能提升。
TCI6618AcceleraTIonPacs
TCI6618為TCI6616增添了加速特性,可將LTE性能翻番。由于TCI6618能夠與TCI6616實(shí)現(xiàn)引腳兼容,因而OEM廠商可通過選擇系統(tǒng)適用的器件輕松靈活地進(jìn)行平臺(tái)優(yōu)化。
由于LTE系統(tǒng)能夠處理比3G系統(tǒng)高得多的數(shù)據(jù)速率,因而加速測(cè)重于對(duì)比特率的處理。
比特率協(xié)處理器
比特率協(xié)處理器(BCP)是一種多標(biāo)準(zhǔn)的協(xié)處理器,其能夠大幅減輕DSP的所有比特率處理任務(wù),從而使信號(hào)鏈的位處理部分無需占用任何DSP周期。它能夠顯著簡化了軟件設(shè)計(jì),并能實(shí)現(xiàn)極低的系統(tǒng)時(shí)延。BCP可執(zhí)行以下功能:
l調(diào)制/解調(diào)
l交錯(cuò)/解交錯(cuò)
l速率匹配/解速率匹配
•加擾/解擾
•LTE的PUCCH解碼
•Turbo和卷積編碼
•CRC連接和校驗(yàn)
BCP不僅能夠針對(duì)MIMO均衡實(shí)現(xiàn)turbo干擾消除,而且還實(shí)現(xiàn)了高性能PUCCHformat2解碼。當(dāng)LTE達(dá)到最大下行鏈路2.2Gbps的吞吐量、上行鏈路1.1Gbps的吞吐量時(shí),BCP可減輕大約15GHz的DSPMIPS。對(duì)于WCDMA而言,最大下行鏈路吞吐量可達(dá)800Mbps,最大上行鏈路吞吐量達(dá)400Mbps。
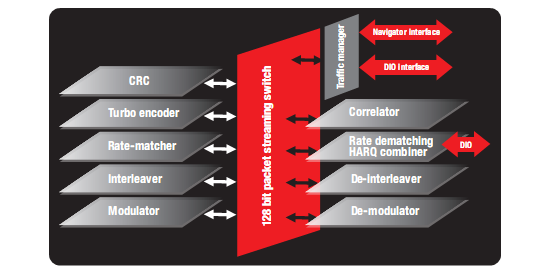
圖5-BCP體系架構(gòu)
在BCP內(nèi)部,數(shù)據(jù)可通過一個(gè)內(nèi)部交換結(jié)構(gòu)從一個(gè)子模塊流入另一個(gè)子模塊。分組DMA流量管理器可通過128位的BCP導(dǎo)航器或直接I/O接口將流量從BCP進(jìn)行輸入與輸出路由。BCP以分組為單位進(jìn)行數(shù)據(jù)處理,并能同時(shí)處理不同的標(biāo)準(zhǔn)。當(dāng)將任務(wù)請(qǐng)求發(fā)送至BCP時(shí),該任務(wù)首先被置入BCP導(dǎo)航器隊(duì)列中。BCP調(diào)度程序依據(jù)任務(wù)優(yōu)先級(jí)選擇需要處理的任務(wù)。接著,由子模塊處理該任務(wù)。最后,可將BCP結(jié)果寫入緩沖器,并將描述符置入完整的隊(duì)列上有待進(jìn)一步處理。因?yàn)闃O少需要軟件的介入,因此對(duì)DSP的周期需求顯著減少,同時(shí)LTE處理時(shí)延也會(huì)大幅降低。
我們?cè)诖藢⒔榻B另一種可簡化DSP處理需求的方法,通過諸如連續(xù)或并行干擾消除(SIC或PIC)等高級(jí)接收機(jī)技術(shù)來提升接收機(jī)的MIMO性能。這些算法需要功能強(qiáng)大的比特率協(xié)處理器才能高效地實(shí)現(xiàn)。解碼算法的迭代特征要求對(duì)數(shù)據(jù)進(jìn)行多次解碼、處理、重新編碼和解碼,這對(duì)一般普通的系統(tǒng)而言可謂巨大的計(jì)算負(fù)擔(dān),但對(duì)于TCI6618卻能輕松處理。
TurboPIC/SIC的性能改進(jìn)意義重大。例如,在2x2MIMO方案中,一個(gè)調(diào)制為QPSK的典型的城域信道中,turboPIC/SIC能產(chǎn)生超過3dB的信噪比(SNR)性能增益,從而與一般的接收機(jī)方法相比可提升高達(dá)40%的頻譜利用率。這不僅對(duì)運(yùn)營商的意義重大,同時(shí)也是TCI6618與其他產(chǎn)品的重要差別點(diǎn)。
圖6顯示了Turbo干擾消除的數(shù)據(jù)流。BCP和FFTC可從反饋路徑分擔(dān)絕大多數(shù)的Turbo均衡周期。
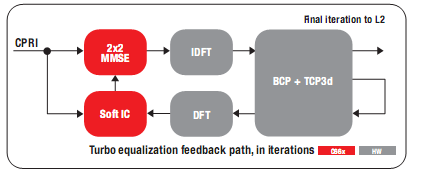
圖6-Turbo干擾消除數(shù)據(jù)流
控制信道解碼器
作為LTE物理上行鏈路控制信道,PUCCH可承載上行鏈路的控制信息,例如調(diào)度請(qǐng)求、確認(rèn)、重傳請(qǐng)求、信道狀態(tài)信息以及信道質(zhì)量指示(CQI)等信息。信道信息解碼會(huì)消耗很大的處理資源。(見圖3)
PUCCHCQI通過ReedMuller(20,A)模塊代碼進(jìn)行編碼。各種不同類型的算法均可對(duì)此信息進(jìn)行解碼。一種非常實(shí)用的基于MRC的算法可在軟件內(nèi)實(shí)施,但其性能不高。BCP針對(duì)PUCCHformat2、2a、2b實(shí)現(xiàn)了高級(jí)的聯(lián)合信道均衡和解碼算法。這與其他更為基礎(chǔ)性的算法相比,可實(shí)現(xiàn)更高的性能。圖7顯示了分別采用TCI6488和TCI6618的實(shí)施周期比較。在該例中,我們對(duì)帶5個(gè)資源模塊的系統(tǒng)進(jìn)行了仿真,每個(gè)系統(tǒng)均有12個(gè)UE,并且使用ReedMuller(20,13)進(jìn)行編碼。在具備雙天線的情況下,對(duì)于從DSP內(nèi)核上的軟件到硬件加速器的傳輸處理中,BCP承擔(dān)了98%的總PUCCHformat2處理量。
與典型算法相比,使用聯(lián)合檢測(cè)算法能將信噪比(SNR)性能提高1到3分貝。這種增強(qiáng)的性能不僅將顯著改進(jìn)鏈路預(yù)算,而且還能減少UE的干擾,并提高下行頻譜利用率,從而提高整個(gè)LTE系統(tǒng)的性能,以為移動(dòng)用戶帶來更精彩的體驗(yàn)。
全面集成——TCI6618
除了BCP協(xié)處理器無與倫比的性能外,TCI6618還添加了額外的FFTC和TCP3d協(xié)處理器,能夠?qū)崿F(xiàn)SoC功能的完美平衡。因此,在6個(gè)迭代中,F(xiàn)FTC的總吞吐量為1,908Mbps,TCP3d的總吞吐量則為582Mbps。與TCI6616相比,TCI6618憑借均衡CPU內(nèi)核和協(xié)處理器將LTE的能力提升了2倍以上。TCI6618通過2x2MIMO天線配置且利用高級(jí)接收機(jī)算法,可以支持兩個(gè)20MHz的LTE區(qū),下行吞吐量總計(jì)可達(dá)300Mbps,而上行吞吐量總計(jì)則可達(dá)150Mbps。
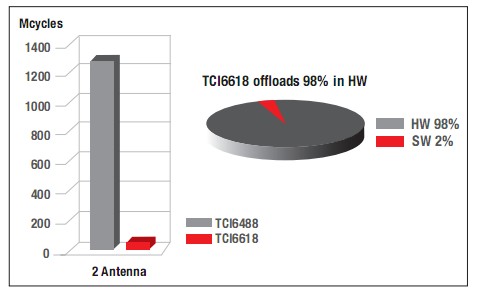
圖7-TCI6618可實(shí)現(xiàn)高級(jí)PUCCH接收機(jī)
圖8顯示了TCI6618的方框圖:
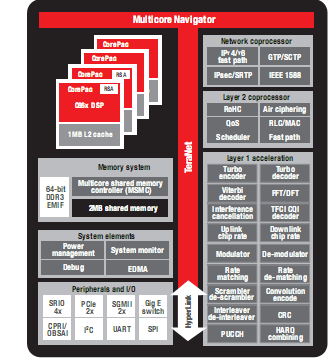
圖8-TCI6618方框圖
憑借KeyStone架構(gòu)、高級(jí)C66x內(nèi)核以及新型BCP等高吞吐量加速器,TCI6618與此前系列的SoC器件相比,可實(shí)現(xiàn)顯著的性能提升。圖9顯示了以圖3為基礎(chǔ)而生成的柱狀圖,闡述了TCI6488與TCI6618兩者之間在DSP周期方面的比較結(jié)果。運(yùn)行條件仍然是20MHz的LTE、2X2MIMO、150Mbps的下行吞吐量以及75Mbps的上行吞吐量。
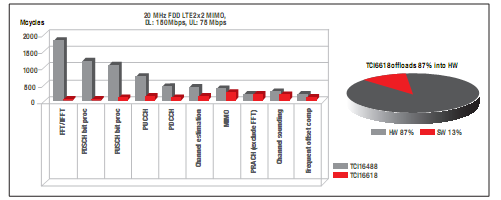
圖9-TCI6618在LTE上的性能飛躍
我們從該圖中看到,大約有90%的TCI6488DSP處理任務(wù)被移至協(xié)處理器,從而實(shí)現(xiàn)了數(shù)量級(jí)的改進(jìn)!
圖10顯示了LTE下行處理(PDSCH)的詳細(xì)結(jié)構(gòu)圖,其中使用協(xié)處理器承擔(dān)了幾乎95%的處理任務(wù)。
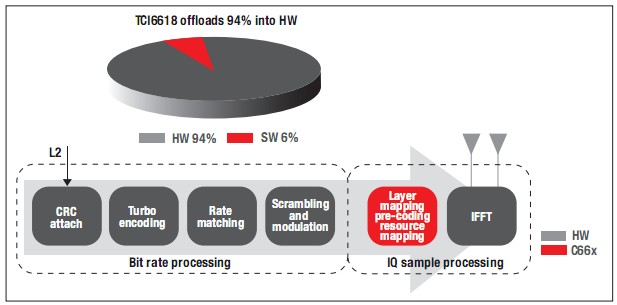
圖10-TCI6618中的PDSCH處理
圖11顯示了LTE上行鏈路方框圖及相關(guān)的協(xié)處理,其中大約90%的處理均由硬件加速器負(fù)責(zé)。
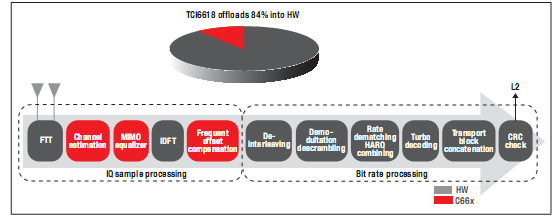
圖11-TCI6618中的PUSCH處理
這些圖清晰地表明,BCP可顯著提高LTE的性能。由于所有比特率處理均被自動(dòng)路由到BCP,因而可大大簡化軟件設(shè)計(jì)并降低時(shí)延。在這樣的數(shù)據(jù)速率(150Mbps的下行/75Mbps的上行)下運(yùn)行,處理時(shí)延還不足70微秒。
BCP不僅可以為LTE實(shí)現(xiàn)上述優(yōu)勢(shì),而且也能為WCDMA分擔(dān)比特率處理任務(wù)。與針對(duì)碼片級(jí)擴(kuò)頻/解擴(kuò)的RAC與TAC結(jié)合使用,可實(shí)現(xiàn)HSDPA信道幾乎完全在硬件中處理。圖12顯示了TCI6618中的HS-PDSCH信號(hào)處理鏈。
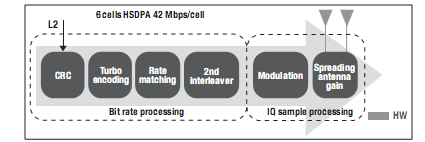
圖12-TCI6618中的HSDPAHS-PDSCH處理
TCI6618能夠支持如下方案:具備6個(gè)使用2x2MIMO的HSDPA單元,且每個(gè)單元的下行吞吐量為42Mbps。在該例中,有超過相當(dāng)于9GHz的DSP處理任務(wù)被分配到專為HS-PDSCH信道設(shè)計(jì)的硬件中處理。
同樣,對(duì)于WCDMA上行信道處理,圖13顯示了HSUPAE-DPDCH處理的信號(hào)鏈與周期分布。
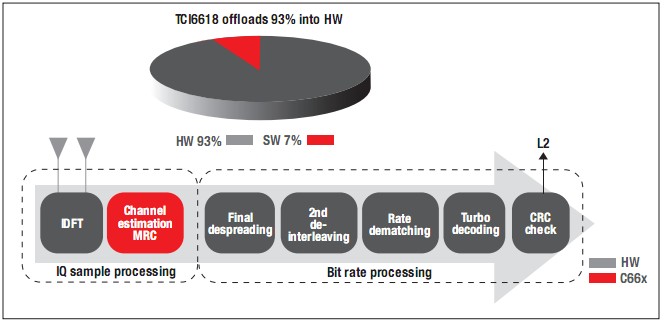
圖13-TCI6618中的HSUPAE-DPDCH處理
結(jié)論
業(yè)界最佳的TMS320TCI6618與TMS320TCI6616SoC經(jīng)過精心設(shè)計(jì),可支持無線數(shù)據(jù)的發(fā)展變革,以及從以語音為中心到以數(shù)據(jù)為中心的處理的演變過度。新的比特率協(xié)處理器(BCP)及KeyStone架構(gòu)可為無線基站提供可實(shí)現(xiàn)最高性能的SoC。集成定點(diǎn)與浮點(diǎn)功能的C66x內(nèi)核能夠?yàn)槭袌錾瞎δ茏顝?qiáng)大的DSP提供系統(tǒng)所需的靈活性。TI借助多年來在無線基站基礎(chǔ)局端領(lǐng)域積累的廣博的專業(yè)知識(shí)和豐富的系統(tǒng)和現(xiàn)場經(jīng)驗(yàn)成就了卓越的設(shè)計(jì)方法,能夠?qū)崿F(xiàn)業(yè)界最可靠、最高級(jí)的解決方案。在基于協(xié)處理器實(shí)現(xiàn)的加速功能和在DSP內(nèi)核中實(shí)現(xiàn)的靈活處理功能之間,TMS320C6618/6架構(gòu)實(shí)現(xiàn)了完美的平衡,不僅能夠?yàn)槎鄻踊幕臼袌鰧?shí)現(xiàn)所需的差異化功能,而且還能繼續(xù)幫助備選解決方案實(shí)現(xiàn)巨大的性能改進(jìn)。