
摘 要: 通過對(duì)車牌定位、車牌字符分割和車牌字符識(shí)別進(jìn)行研究,提出了一種車牌識(shí)別系統(tǒng)的設(shè)計(jì)和實(shí)驗(yàn)仿真方法。該方法首先采用基于Canny 算子邊緣檢測(cè)和數(shù)學(xué)形態(tài)學(xué)相結(jié)合的方法定位出車牌,進(jìn)行二值化、濾波和形態(tài)學(xué)開運(yùn)算后使用投影二分法分割出7個(gè)車牌字符,最后使用模板匹配和特征統(tǒng)計(jì)相結(jié)合的方法識(shí)別出車牌字符。試驗(yàn)表明該方法是有效的、可行的,與傳統(tǒng)使用單一算法相比較,該方法大大提高了車牌識(shí)別系統(tǒng)的正確率。
關(guān)鍵詞: 圖像預(yù)處理; 車牌定位; 車牌字符分割; 車牌字符識(shí)別
隨著世界經(jīng)濟(jì)和科學(xué)技術(shù)的不斷發(fā)展,智能交通系統(tǒng)越來越多地被人們所關(guān)注。車牌識(shí)別LPR(License Plate Recognition)是智能交通系統(tǒng)中重要研究課題[1],已成為圖像處理和模式識(shí)別研究中的熱點(diǎn)。整個(gè)車牌識(shí)別系統(tǒng)主要包括圖像預(yù)處理、車牌定位、車牌字符分割、車牌字符識(shí)別4個(gè)模塊,其流程圖如圖1所示。

圖像預(yù)處理主要是將輸入的彩色圖像轉(zhuǎn)換為灰度圖像,再進(jìn)行灰度增強(qiáng),以達(dá)到較好的凸顯車牌字符的效果。這里首先將24位R、G、B的彩色圖像按式(1)轉(zhuǎn)換成256級(jí)的灰度圖,以減少存儲(chǔ)和計(jì)算量,圖2是轉(zhuǎn)換后的車牌灰度圖。

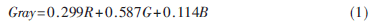
1 車牌定位
車牌定位是車牌識(shí)別系統(tǒng)中關(guān)鍵的一步,直接關(guān)系到車牌字符分割的準(zhǔn)確性和系統(tǒng)識(shí)別的正確率[2]。通過比較4種典型的邊緣檢測(cè)算子,選擇Canny算子對(duì)車牌進(jìn)行邊緣檢測(cè),然后對(duì)車牌進(jìn)行形態(tài)學(xué)處理,并統(tǒng)計(jì)圖像中白色像素點(diǎn)的個(gè)數(shù)定位出車牌區(qū)域。
1.1 4種典型的邊緣檢測(cè)算子
邊緣檢測(cè)的目的是標(biāo)識(shí)數(shù)字圖像中亮度變化明顯的點(diǎn),車牌識(shí)別4種典型的邊緣檢測(cè)算子有:Roberts算子、Prewitt算子、Sobel算子和Canny算子,圖3是這4種典型的邊緣檢測(cè)算子對(duì)車牌圖像的檢測(cè)效果圖。

實(shí)驗(yàn)結(jié)果表明,Roberts算子對(duì)邊緣定位比較準(zhǔn),但對(duì)噪聲過于敏感,在圖像噪聲較少的情況下分割效果相當(dāng)不錯(cuò)。Prewitt算子有一定的抗噪能力,但是這種抗噪能力是通過像素平均來實(shí)現(xiàn)的,相當(dāng)于低通濾波,所以圖像有一定模糊,其邊緣檢測(cè)時(shí)會(huì)受到一定影響。Soble算子對(duì)噪聲有抑制作用,但對(duì)邊緣的定位不是很準(zhǔn)確,不適合對(duì)邊緣定位的準(zhǔn)確性要求很高的應(yīng)用。Canny算子具有高定位精度,即能準(zhǔn)確地把邊緣點(diǎn)定位在灰度變化最大的像素上,同時(shí)較好地保留了原有車形的邊緣特征,并能抑制虛假邊緣的產(chǎn)生,因此本文選取Canny算子作為車牌圖像邊緣檢測(cè)算子。
Canny算子邊緣檢測(cè)的實(shí)現(xiàn)是由MATLAB圖像處理工具箱中edge函數(shù)來完成的。edge函數(shù)主要是在灰度圖像中查找圖像的邊緣,處理圖像的格式為BW=edge(I,′Canny′,thresh),其中I為灰度圖像;thresh是一個(gè)包含兩個(gè)閾值的向量,第一個(gè)元素是低閾值,第二個(gè)元素是高閾值,本文Canny算子邊緣檢測(cè)的MATLAB參數(shù)設(shè)置如下:
I2=edge(I1,′Canny′,[0.25,0.65]);
figure(3),imshow(I2);title(′Canny算子邊緣檢測(cè)′);
1.2數(shù)學(xué)形態(tài)學(xué)處理
數(shù)學(xué)形態(tài)學(xué)是由一組形態(tài)學(xué)的代數(shù)運(yùn)算算子組成的,用這些算子可以對(duì)圖像的形狀和結(jié)構(gòu)進(jìn)行分析及處理[3]。通過對(duì)圖像的腐蝕和膨脹運(yùn)算能使車牌區(qū)域連通,并最大限度地消除非車牌區(qū)域的噪聲干擾。腐蝕和膨脹后的車牌圖像如圖4所示。

圖像經(jīng)過膨脹以后依然存在許多連通的小區(qū)域,但這些小區(qū)域明顯不是車牌候選區(qū)域且形狀不規(guī)則。由車牌的先驗(yàn)信息知,我國(guó)車牌形狀為矩形,一般高14 cm,寬44 cm,寬高比3.14。根據(jù)我國(guó)車牌的特征很容易就能夠刪除這些干擾對(duì)象,即使用bwareaopen函數(shù)來處理干擾對(duì)象。bwareaopen函數(shù)的格式為BW2=bwareaopen(BW,P,conn),其作用是移除二值圖像BW中面積小于閾值P的對(duì)象。通過實(shí)驗(yàn)得閾值P取2 000~3 500之間效果較好,這里閾值P的取值為2 800。圖5是移除小對(duì)象后得到的車牌圖像。
1.3車牌剪切
通過數(shù)學(xué)形態(tài)學(xué)處理之后已大體上定位出車牌的位置,接下來就是從原彩色圖像中把車牌剪切出來,并去除車牌邊框。圖像中車牌位置可以通過統(tǒng)計(jì)圖像中的白色像素點(diǎn)的個(gè)數(shù)獲得[4],再使用MATLAB中imcrop函數(shù)剪切出車牌。針對(duì)車牌邊框可以通過設(shè)置不同的閾值來去除,以L1=Width/7為閾值對(duì)剪切出的車牌圖像按行掃描,如果有線段的長(zhǎng)度大于L1就可以認(rèn)為是牌照的上下邊框,再以L2=Height×3/5 為閾值對(duì)剪切出的車牌圖像按列掃描,如果有線段的長(zhǎng)度大于L2,則認(rèn)為是牌照的左右邊框。找到車牌的上、下、左、右邊框之后,重新剪切車牌圖像去除車牌邊框,完成車牌的定位, 如圖6所示。


2 車牌字符分割
車牌字符分割是指將單個(gè)字符從車牌圖像中分離出來。車牌字符分割方法主要有數(shù)學(xué)形態(tài)學(xué)法、投影法、松弛標(biāo)記法、連通分支法和顏色塊法[5]。本文綜合使用了數(shù)學(xué)形態(tài)學(xué)和投影法來分割車牌字符,其基本流程是:首先對(duì)定位出的車牌進(jìn)行二值化和形態(tài)學(xué)開運(yùn)算,以去除灰塵及鉚釘?shù)雀蓴_噪聲,然后利用投影二分法分割出7個(gè)車牌字符,并對(duì)字符進(jìn)行歸一化。
2.1二值化和形態(tài)學(xué)開運(yùn)算
二值化圖像的目的主要是找出一個(gè)合適的閾值或一個(gè)閾值范圍,將車牌區(qū)域劃分為前景和背景兩部分,以方便車牌字符的分割。常用的二值化方法有直方圖統(tǒng)計(jì)法、固定門限法、動(dòng)態(tài)閾值法、松弛法、抖動(dòng)矩陣二值法等。本文使用了迭代求圖像最佳分割閾值的算法,得到的二值化圖像如圖7所示。

2.2字符分割及歸一化
在車牌字符分割中,使用最多的是垂直投影法,該方法將灰度車牌圖像像素列方向上求和,這樣有字符的地方投影較高,而字符中間,理想情況下是沒有像素的,但現(xiàn)實(shí)圖像中由于噪聲的干擾會(huì)存在一定的像素。在現(xiàn)實(shí)環(huán)境中車牌圖像上往往有灰塵、鉚釘?shù)仍肼暎捎诖怪蓖队笆茉肼曈绊戄^大,易造成分割字符的粘連與斷裂,嚴(yán)重情況下會(huì)造成車牌字符之間的投影很難辨認(rèn),在一定程度上影響了車牌的識(shí)別率。針對(duì)傳統(tǒng)投影法的不足,冼允廷等提出了基于投影二分法的車牌字符分割方法[6]。該方法主要是通過迭代尋找最佳分割點(diǎn),能夠很好地解決車牌字符分割中存在的粘連和斷裂問題,因此本文選用投影二分法對(duì)車牌圖像進(jìn)行分割,通過投影二分法分割出的車牌字符圖像如圖9所示。

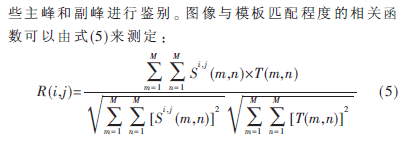
其中,R(i,j)為互相關(guān)算子,S為待檢測(cè)的圖像,S為待檢測(cè)的子圖,T為模板。將待識(shí)別的字符逐一和所有模板進(jìn)行匹配,并用上述相似度式子來計(jì)算車牌字符與每個(gè)模板字符的匹配程度,最相似的就是匹配結(jié)果,從而判斷并識(shí)別出待識(shí)別的字符。
計(jì)算二維圖像相似度可以用Matlab中提供的corr2函數(shù)來實(shí)現(xiàn)。corr2函數(shù)的調(diào)用方法是R=corr2(A,B),其中R是相關(guān)系數(shù),數(shù)據(jù)類型為雙精度,A、B為大小和數(shù)據(jù)類型相同的圖像矩陣。因?yàn)榍懊娴能嚺谱址指瞽h(huán)節(jié)中已把車牌字符大小歸一化為40×20的圖像,與模板圖像大小相同,所以模板匹配過程只需調(diào)用此函數(shù),將分割出來的每個(gè)字符與設(shè)置好的模板進(jìn)行相關(guān)運(yùn)算,然后使用MATLAB中max函數(shù)尋找出它們中的最大相關(guān)值,即最相似的匹配結(jié)果,就完成了模板匹配過程。
3.2 特征統(tǒng)計(jì)優(yōu)化識(shí)別
由于車牌字符中的個(gè)別英文字母與阿拉伯?dāng)?shù)字具有相似的結(jié)構(gòu)特征,投影點(diǎn)的歐氏距離相差較小,因此,需要對(duì)部分相似字符的識(shí)別結(jié)果進(jìn)行優(yōu)化識(shí)別,并將優(yōu)化結(jié)果作為最終識(shí)別結(jié)果輸出。例如:
(1)數(shù)字0與8:利用數(shù)字0與8的“空心”個(gè)數(shù)進(jìn)行區(qū)分。數(shù)字0從上到下只有一個(gè)空心,而數(shù)字8從上到下有兩個(gè)空心。因此,可以將數(shù)字0與8區(qū)分開。
(2)數(shù)字6與9:利用數(shù)字6與9的“空心”區(qū)域分別位于圖像的中下部與中上部的特點(diǎn),可以將其區(qū)分開。
(3)數(shù)字8與字母B:利用數(shù)字8和字母B中部左邊像素點(diǎn)的位置進(jìn)行區(qū)分。對(duì)字符圖像的中部(從上向下第11個(gè)像素點(diǎn)至第21個(gè)像素點(diǎn))從左向右檢測(cè)第1個(gè)白色像素點(diǎn),并記錄該點(diǎn)的位置。取這些點(diǎn)的算術(shù)平均值,若該值在4個(gè)像素點(diǎn)以下,則該字符為字母B,否則為數(shù)字8。
本文對(duì)不同天氣情況下采集的358幅圖片進(jìn)行了MATLAB仿真測(cè)試。如果僅使用模板匹配法,可以識(shí)別出284幅圖片,識(shí)別正確率為79.3%,其中有45幅是在相似字符識(shí)別時(shí)出錯(cuò);如果使用模板匹配和特征統(tǒng)計(jì)相結(jié)合的方法,可以識(shí)別出329幅圖片,識(shí)別正確率為91.9%,其中相似字符的識(shí)別準(zhǔn)確率大大提高。與單一使用模板匹配相比較,本文方法明顯優(yōu)于傳統(tǒng)的模板匹配法,分析原因主要是通過特征統(tǒng)計(jì)對(duì)相似字符的再次識(shí)別彌補(bǔ)了模板匹配對(duì)相似字符識(shí)別較弱的不足。與傳統(tǒng)使用神經(jīng)網(wǎng)絡(luò)方法識(shí)別率只有75.7%相比較,本文91.9%的識(shí)別正確率具有明顯優(yōu)勢(shì)。總之實(shí)驗(yàn)結(jié)果表明,經(jīng)過特征統(tǒng)計(jì)再次優(yōu)化識(shí)別以后大大提高了整個(gè)系統(tǒng)的識(shí)別正確率,圖11所示為本文車牌識(shí)別圖像。

目前,車牌識(shí)別技術(shù)已經(jīng)取得一定突破,但在現(xiàn)實(shí)應(yīng)用中車牌識(shí)別正確率還不理想,僅使用一種特征和識(shí)別方法都有其優(yōu)點(diǎn)和局限性,走多特征組合、多方案集成的道路,已成為車牌識(shí)別系統(tǒng)走向?qū)嵱没挠行緩剑虼塑嚺谱R(shí)別系統(tǒng)算法實(shí)用化的研究十分重要。
參考文獻(xiàn)
[1] GUO J M, LIU Y F. License plate localization and character segmentation with feedback self-learning and hybrid binarization techniques[J]. Transactions on Vehicular Technology, 2008,57(3):1417-1424.
[2] ZHANG C, SUN G M,CHEN D M. A rapid locating method of vehicle license plate based on characteristics of characters′ connection and projection[C]. Proc of the Second IEEE Conference on Industrial Electronics and Applications, 2007:2546-2549.
[3] BAI H L, LIU C P. A hybrid license plate extraction method based on edge statistics and morphology[C]. Proc of the 17th International on Pattern Recognition,2004:831-834.
[4] 沈勇武,章專. 基于特征顏色邊緣檢測(cè)的車牌定位方法[J].儀器儀表學(xué)報(bào),2008,29(12):2673-2677.
[5] CHANG S L,CHEN L S,CHUNG Y C. Automatic license plate recognition[J].IEEE Transactions on Intelligent Transortation System, 2004,5(1):42-53.
[6] 冼允廷,路小波,施毅,等.基于投影二分法的車牌字符分割方法[J].交通計(jì)算機(jī), 2007,25(5):69-71.