
摘 要: 針對已有增量分類算法只是作用于小規(guī)模數(shù)據(jù)集或者在集中式環(huán)境下進(jìn)行的缺點(diǎn),,提出一種基于Hadoop云計(jì)算平臺的增量分類模型,以解決大規(guī)模數(shù)據(jù)集的增量分類,。為了使云計(jì)算平臺可以自動地對增量的訓(xùn)練樣本進(jìn)行處理,,基于模塊化集成學(xué)習(xí)思想,設(shè)計(jì)相應(yīng)Map函數(shù)對不同時刻的增量樣本塊進(jìn)行訓(xùn)練,,Reduce函數(shù)對不同時刻訓(xùn)練得到的分類器進(jìn)行集成,,以實(shí)現(xiàn)云計(jì)算平臺上的增量學(xué)習(xí)。仿真實(shí)驗(yàn)證明了該方法的正確性和可行性,。
關(guān)鍵詞: 增量分類,;Hadoop;云計(jì)算
隨著信息技術(shù)和生物技術(shù)突飛猛進(jìn)的發(fā)展,,科學(xué)研究和實(shí)際應(yīng)用中產(chǎn)生了海量數(shù)據(jù),,并且這些數(shù)據(jù)每天都在增加,為了將每天產(chǎn)生的新數(shù)據(jù)納入到新的學(xué)習(xí)系統(tǒng),,需要利用增量學(xué)習(xí),。增量學(xué)習(xí)比較接近人類自身的學(xué)習(xí)方式,可以漸進(jìn)地進(jìn)行知識的更新,,修正和加強(qiáng)以前的知識,,使得更新后的知識能適應(yīng)更新后的數(shù)據(jù),而不必重新學(xué)習(xí)全部數(shù)據(jù),,從而降低了對時間和空間的需求,。模塊化是擴(kuò)展現(xiàn)有增量學(xué)習(xí)能力的有效方法之一[1],而集成學(xué)習(xí)(Ensemble Learning)一直是機(jī)器學(xué)習(xí)領(lǐng)域的一個研究熱點(diǎn)[2-6],,許多模塊化增量分類算法[7-9]正是基于二者提出的,。
云計(jì)算(Cloud Computing)這一新名詞從2007年第3季度誕生起就在學(xué)術(shù)界和產(chǎn)業(yè)界引起了轟動,Google,、IBM,、百度、Yahoo等公司都開始進(jìn)行“云計(jì)算”的部署工作,。云計(jì)算是分布式計(jì)算(Distributed Computing)、并行計(jì)算(Parallel Computing)和網(wǎng)格計(jì)算(Grid Computing)的發(fā)展與延伸,。在云計(jì)算環(huán)境下,,互聯(lián)網(wǎng)用戶只需要一個終端就可以享用非本地或遠(yuǎn)程服務(wù)集群提供的各種服務(wù)(包括計(jì)算、存儲等),,真正實(shí)現(xiàn)了按需計(jì)算,,有效地提高了云端各種軟硬件資源的利用效率。隨著云計(jì)算技術(shù)的日益成熟,云計(jì)算也為解決海量數(shù)據(jù)挖掘所面臨的問題提供了很好的基礎(chǔ)[10],。雖然在機(jī)器學(xué)習(xí)領(lǐng)域,,對增量學(xué)習(xí)進(jìn)行了較深入的研究,但是在云計(jì)算環(huán)境下,,還沒有相關(guān)文獻(xiàn)討論利用增量分類提高云計(jì)算環(huán)境下海量數(shù)據(jù)挖掘的效率問題,。本文基于模塊化的集成學(xué)習(xí)思想,研究在開源云計(jì)算平臺Hadoop[11]上的增量分類方法,。
1 Hadoop云平臺的體系結(jié)構(gòu)
在現(xiàn)有的云計(jì)算技術(shù)中,, Apache軟件基金會(Apache Software Foundation) 組織下的開源項(xiàng)目Hadoop是一個很容易支持開發(fā)和并行處理大規(guī)模數(shù)據(jù)的分布式云計(jì)算平臺,具有可擴(kuò)展,、低成本,、高效和可靠性等優(yōu)點(diǎn)。程序員可以使用Hadoop中的Streaming工具(Hadoop為簡化Map/Reduce的編寫,,為讓不熟悉Java的程序員更容易在Hadoop上開發(fā)而提供的一個接口)使用任何語言編寫并運(yùn)行一個Map/Reduce作業(yè),。Hadoop項(xiàng)目包括多個子項(xiàng)目,但主要是由Hadoop分布式文件系統(tǒng)HDFS(Hadoop Distributed File System)和映射/化簡引擎(Map/Reduce Engine)兩個主要的子項(xiàng)目構(gòu)成,。
1.1 分布式文件系統(tǒng)HDFS
Hadoop實(shí)現(xiàn)了一個分布式文件系統(tǒng)(Hadoop Distribu-
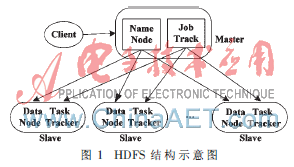
tedFile System),,簡稱HDFS。HDFS采用Master/Slave架構(gòu),,一個HDFS集群由一個NameNode節(jié)點(diǎn)和若干DataNode節(jié)點(diǎn)組成,。NameNode節(jié)點(diǎn)存儲著文件系統(tǒng)的元數(shù)據(jù),這些元數(shù)據(jù)包括文件系統(tǒng)的名字空間等,,并負(fù)責(zé)管理文件的存儲等服務(wù),,程序使用的實(shí)際數(shù)據(jù)并存放在DataNode中,Client是獲取分布式文件系統(tǒng)HDFS文件的應(yīng)用程序,。圖1是HDFS結(jié)構(gòu)圖,。
圖1中,Master主要負(fù)責(zé)NameNode及JobTracker的工作,,JobTracker的主要職責(zé)是啟動,、跟蹤和調(diào)度各個Slave任務(wù)的執(zhí)行。還會有多臺Slave,,每一臺Slave通常具有DataNode的功能并負(fù)責(zé)TaskTracker的工作,。TaskTracker根據(jù)應(yīng)用要求來結(jié)合本地數(shù)據(jù)執(zhí)行Map任務(wù)以及Reduce任務(wù)。
1.2 Map/Reduce分布式并行編程模型
Hadoop框架中采用了Google提出的云計(jì)算核心計(jì)算模式Map/Reduce,,它是一種分布式計(jì)算模型,,也是簡化的分布式編程模式[12]。Map/Reduce把運(yùn)行在大規(guī)模集群上的并行計(jì)算過程抽象成兩個函數(shù):Map和Reduce,,其中,,Map把任務(wù)分解成多個任務(wù),Reduce把分解后的多個任務(wù)處理結(jié)果匯總起來,得到最終結(jié)果,。圖2介紹了用Map/Reduce處理數(shù)據(jù)的過程,。一個Map/Reduce操作分為兩個階段:映射和化簡。
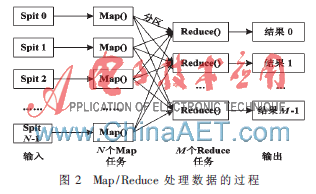
在映射階段(Map階段),,Map/Reduce框架將用戶輸入的數(shù)據(jù)分割為N個片段,,對應(yīng)N個Map任務(wù)。每一個Map的輸入是數(shù)據(jù)片段中的鍵值對<K1,,V1>集合,,Map操作會調(diào)用用戶定義的Map函數(shù),輸出一個中間態(tài)的鍵值對<K2,,V2>,。然后,按照中間態(tài)K2將輸出的數(shù)據(jù)進(jìn)行排序,,形成<K2,,list(V2)>元組,這樣可以使對應(yīng)于同一個鍵的所有值的數(shù)據(jù)都集合在一起,。最后,,按照K2的范圍將這些元組分割成M個片段,從而形成M個Rdeuce任務(wù),。
在化簡階段(Reduce階段),,每一個Reduce操作的輸入是Map階段的輸出,即<K2,,list(V2)>片段,,Reduce操作調(diào)用用戶定義的Reduce函數(shù),生成用戶需要的結(jié)果<K3,,V3>進(jìn)行輸出,。
2 基于Map/Reduce的模塊化增量分類模型
基于Map/Reduce的增量分類模型,主要思想是Map函數(shù)對訓(xùn)練數(shù)據(jù)進(jìn)行訓(xùn)練,,得到基于不同時刻增量塊的分類器,,Reduce函數(shù)利用Map訓(xùn)練好的分類器對測試樣本進(jìn)行預(yù)測,并且將不同時刻訓(xùn)練得到的分類器進(jìn)行集成,,得到最終的分類結(jié)果,。基于Map/Reduce的增量分類模型如圖3所示,。當(dāng)t1時刻有海量的訓(xùn)練樣本到達(dá)時,,通過設(shè)置Map任務(wù)的個數(shù)使得云平臺自動地對到達(dá)的海量樣本進(jìn)行劃分,每個Map的任務(wù)就是對基于劃分所得的樣本子集進(jìn)行訓(xùn)練得到一個基分類器,。同一時刻的不同Map之間可以并行訓(xùn)練,從而得到t1時刻的增量分類系統(tǒng)。當(dāng)tT時刻的訓(xùn)練樣本到達(dá)以后,,采取相同的步驟,,得到tT時刻的不同基分類器,然后將這些分類器加入到tT-1時刻的增量分類系統(tǒng)以構(gòu)成tT時刻的增量分類系統(tǒng),。再采用Reduce函數(shù)將當(dāng)前增量分類系統(tǒng)里所有分類器進(jìn)行集成,,集成方法可以采用投票法Majority Voting(MV)進(jìn)行。
2.1 Map過程
Map函數(shù)的主要功能就是建立不同時刻的增量分類系統(tǒng),。當(dāng)某一時刻有新的訓(xùn)練樣本到達(dá)時,,Map便從HDFS將其讀取。通過設(shè)置Map任務(wù)的個數(shù)使得云平臺自動地對大規(guī)模的訓(xùn)練樣本進(jìn)行劃分,,每一個Map任務(wù)完成基于一個劃分塊的分類訓(xùn)練,,劃分后的不同塊可以并行訓(xùn)練,從而得到基于該時刻增量樣本集的不同分類器,,然后將這些分類器加入上一時刻的增量分類系統(tǒng)以構(gòu)成當(dāng)前時刻的增量分類系統(tǒng),。Map函數(shù)偽代碼如下:


3 仿真實(shí)驗(yàn)
本文用三臺PC搭建了Hadoop云計(jì)算平臺,三臺PC的硬件配置均為2GRAM和AMD雙核CPU,,各節(jié)點(diǎn)的操作系統(tǒng)為Linux Centos 5.4,,Hadoop版本為0.19.2,JDK版本為1.6.0_12,。實(shí)驗(yàn)中一臺PC既部署NameNode和JobTrack,,也部署DataNode和TaskTrack,另兩臺PC均部署DataNode和TaskTrack,。
實(shí)驗(yàn)對兩個數(shù)據(jù)集進(jìn)行了仿真,,第一個數(shù)據(jù)集是來自UCI的Adult[13]數(shù)據(jù)集,第二個是來自UCI的Mushrooms(每個實(shí)名屬性都被分解成若干個二進(jìn)制屬性,初始的12號屬性由于丟失未使用)數(shù)據(jù)集,。分類器采用SVM[14],。為了證明該方法的正確性,每個實(shí)驗(yàn)分別在集中式和云平臺兩種環(huán)境下進(jìn)行,。兩種環(huán)境都將訓(xùn)練樣本集隨機(jī)劃分為五等份以構(gòu)成5個增量訓(xùn)練子集,,也就是按照時間順序進(jìn)行了5次增量訓(xùn)練。由于現(xiàn)實(shí)中采集的增量訓(xùn)練樣本的規(guī)??赡芎艽?,所以在云平臺環(huán)境中,通過設(shè)置Map的個數(shù)對樣本進(jìn)行分解,。本次實(shí)驗(yàn)中Map的個數(shù)設(shè)為2,,這樣每個增量訓(xùn)練子集都會被云平臺自動劃分成兩塊,各塊之間可以進(jìn)行并行訓(xùn)練,。為了與云平臺環(huán)境進(jìn)行對比,,在集中式環(huán)境中將每個子集手動均分成兩塊,,每塊用來訓(xùn)練一個分類器。每個實(shí)驗(yàn)均采用了式(1)和式(2)兩種核函數(shù),。
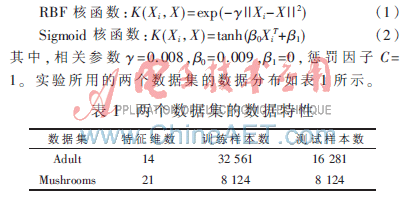
其中,,相關(guān)參數(shù)γ=0.008,β0=0.009,,β1=0,,懲罰因子C=1。實(shí)驗(yàn)所用的兩個數(shù)據(jù)集的數(shù)據(jù)分布如表1所示,。
兩個增量分類系統(tǒng)在不同數(shù)據(jù)集上的分類性能如圖4所示,。通過比較可知,集中式增量分類的準(zhǔn)確率和Hadoop云平臺上增量分類準(zhǔn)確率較為接近,,證明了本文所提出的在Hadoop云平臺上實(shí)現(xiàn)增量分類方法的可行性和正確性,。由于MV方法本身具有較大的波動性,故集中式和Hadoop云平臺環(huán)境中隨著訓(xùn)練樣本的增加,,增量分類系統(tǒng)的學(xué)習(xí)能力是曲折上升的,。

本文提出了一種基于Hadoop云平臺的增量分類方法,仿真實(shí)驗(yàn)表明,,基于Hadoop云平臺的增量分類是可行的,。與其他增量分類方法相比,該模型簡單,,易于實(shí)現(xiàn),。通過設(shè)置平臺中Map任務(wù)的個數(shù)讓云平臺自動地對海量訓(xùn)練樣本進(jìn)行劃分,劃分后的各個任務(wù)相互獨(dú)立,,可以進(jìn)行并行訓(xùn)練,。這提高了海量數(shù)據(jù)的處理速度,基本實(shí)現(xiàn)了實(shí)時的增量分類,。
參考文獻(xiàn)
[1] 羅四維,,溫津偉.神經(jīng)場整體性和增殖性研究與分析[J].計(jì)算機(jī)研究與發(fā)展,2003,,40(5):668-674.
[2] 周志華,,陳世福.神經(jīng)網(wǎng)絡(luò)集成[J].計(jì)算機(jī)學(xué)報,2002,,25(1):1-8.
[3] 王玨,,石純一.機(jī)器學(xué)習(xí)研究[J].廣西師范大學(xué)學(xué)報,2003,,21(2):1-15.
[4] LU B L,,ITO M.Task decomposition and module combination based on class relations:a modular neural networks for pattern classification[J].IEEE Trans.Neural Networks,1999,,10(5):1244-1256.
[5] HUANG Y S,,SUEN C Y.A method of combining multiple experts for the recognition of unconstrained handwritten numerals[J]. IEEE Trans. Pattern Analysis and Machine Intelligence,1995,17(1):90-94.
[6] WOODS K, KEGELMEYER W P,,BOWYER K.Combination of multiple classifiers using local accuracy estimates[J]. IEEE Trans. Pattern Analysis and Machine Intelligence, 1997, 19(4):405-410.
[7] POLIKAR R,UDPA L,,UDPA S S,,et al. Learn++:an incremental learning algorithm for supervised neural networks [J]. IEEE Trans. System, Man, and Cybernetic, 2001,31(4):497-508.
[8] LU B L,ICHIKAWA M. Emergent online learning in minmax modular neural networks[J]. In:Proc. of Inter’l Conference on Neural Network(IJCNN’01), Washington, DC,USA, 2001:2650-2655.
[9] 文益民,,楊旸,呂寶糧.集成學(xué)習(xí)算法在增量學(xué)習(xí)中的應(yīng)用研究[J].計(jì)算機(jī)研究與發(fā)展, 2005, 42(增刊):222-227.
[10] COPPOCK H W,,F(xiàn)REUND J E.All-or-none versus incremental learning of errorless shock escapes by the rat[J]. Science, 1962, 135(3500):318-319.
[11] Hadoop.[EB/OL].2008-12-16.http://hadoop.apache.org/core/.
[12] DEAN J,,GHEMAWAT S.MapReduce:simplified data processingon large clusters[J]. Communications of the ACM, 2008, 51(1):107-113.
[13] PLATT J C. Fast training of support vector machines using sequential minimal optimization[D].SCHOLKOPF B, BURGES C J C, SMOLA A J, editors.Advances in kernel methods-support vector learning.Cambridge, MA,MIT Press,1998.
[14] 鄧乃揚(yáng),,田英杰.數(shù)據(jù)挖掘中的新方法:支持向量機(jī)[D]. 北京:科學(xué)出版社, 2004.