
摘 要: 對于一些查詢密集型的應(yīng)用,查詢操作的響應(yīng)速度往往是決定其系統(tǒng)性能的關(guān)鍵因素,因此如何提高查詢響應(yīng)速度和系統(tǒng)吞吐率成為首要任務(wù)。經(jīng)過實驗證明,通過將查詢數(shù)據(jù)緩存可以有效地解決這個問題。
關(guān)鍵詞: 數(shù)據(jù)集成;數(shù)據(jù)緩存;B_Link樹
目前,在企業(yè)中由于開發(fā)時間或開發(fā)部門的不同,往往存在有多個異構(gòu)的在不同軟硬件平臺上的信息系統(tǒng)同時運行,這些系統(tǒng)的數(shù)據(jù)源彼此獨立、相互封閉,使得數(shù)據(jù)難以在系統(tǒng)之間交流、共享和融合,從而形成了“信息孤島”問題。如何對這些數(shù)據(jù)進行有效的集成管理,屏蔽這些信息的異構(gòu)部分,并給上層用戶或應(yīng)用提供一個統(tǒng)一透明的訪問接口,以透明的方式訪問各信息源,成為當(dāng)今企業(yè)和組織所關(guān)心的問題。數(shù)據(jù)集成也就是在這樣的情況下提出來的。
通過復(fù)制的方式,將各種異構(gòu)數(shù)據(jù)源中的數(shù)據(jù)抽取到一個統(tǒng)一的數(shù)據(jù)源中(如數(shù)據(jù)倉庫),同時維護數(shù)據(jù)源整體上數(shù)據(jù)的一致性。該方式實現(xiàn)了對物理數(shù)據(jù)庫異構(gòu)的屏蔽和數(shù)據(jù)訪問的控制,以便于提供一個統(tǒng)一的訪問接口、提高訪問效率和系統(tǒng)的獨立性。圖1是一個典型的基于數(shù)據(jù)復(fù)制方式建立的數(shù)據(jù)倉庫體系結(jié)構(gòu)圖。
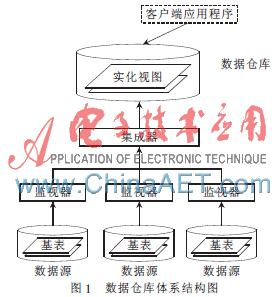
此外,在把數(shù)據(jù)倉庫應(yīng)用于數(shù)據(jù)集成時,還需解決如何應(yīng)對大量客戶端應(yīng)用程序?qū)?shù)據(jù)倉庫進行訪問時能夠做出快速的響應(yīng)。但是一個數(shù)據(jù)庫的連接資源是有限的,大量的并發(fā)查詢操作必定會導(dǎo)致查詢效率的下降,導(dǎo)致客戶端應(yīng)用程序獲取數(shù)據(jù)的延遲時間大大增加。這樣的情況用戶是不想看到的,甚至有些對時間有一定限制的應(yīng)用因為不能及時獲得所需的數(shù)據(jù)而無法正常工作而迫切需要解決這一問題。出現(xiàn)這個問題的原因是:由于連接數(shù)據(jù)庫是一件耗時的工作,而且一般數(shù)據(jù)庫服務(wù)器能同時提供的連接數(shù)也相當(dāng)有限,出現(xiàn)了性能瓶頸。解決這個問題的有效方法可以通過將查詢過的數(shù)據(jù)緩存起來,若下次有同樣的查詢時則不需再連接數(shù)據(jù)庫,而是直接從緩存中獲得,這樣不但節(jié)省了連接數(shù)據(jù)庫的時間開銷,而且省略了查詢數(shù)據(jù)庫所帶來的時間和資源的消耗。但是對于數(shù)據(jù)緩存的組織不能簡單了事,必須得經(jīng)過精心的設(shè)計。為此,本文提出一種基于B_Link樹的方法來管理緩存。下面將詳細(xì)介紹如何組織和管理緩存。
1 數(shù)據(jù)緩存的體系結(jié)構(gòu)
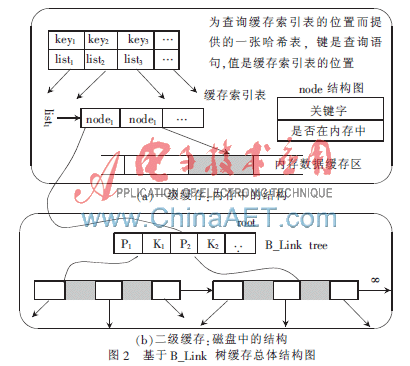
無論多么強大的服務(wù)器,其內(nèi)存的數(shù)量都是有限的,故在考慮大數(shù)據(jù)量的緩存時,不可能將所有的數(shù)據(jù)都緩存在內(nèi)存中,而要考慮使用二級緩存。基于B_Link樹緩存總體結(jié)構(gòu)如圖2所示,為了解決內(nèi)存有限的問題,采用了兩層緩存結(jié)構(gòu),用一張哈希表將查詢與索引表對應(yīng)起來。若已經(jīng)建立了緩存,則對應(yīng)有一張緩存索引表,用于記錄數(shù)據(jù)記錄塊的位置(數(shù)據(jù)記錄塊是指把數(shù)據(jù)記錄打包成塊進行保存和傳輸)。若數(shù)據(jù)在內(nèi)存中則直接取出發(fā)送給客戶端應(yīng)用程序即可,否則需通過關(guān)鍵詞去磁盤中獲取。磁盤中的緩存是基于B_Link樹組織起來的。
2 B_Link樹的基本結(jié)構(gòu)和操作
2.1 數(shù)據(jù)結(jié)構(gòu)
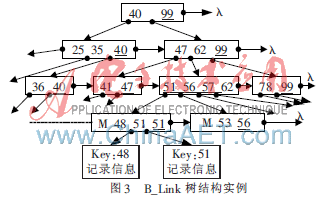
B_Link樹是在B+樹的基礎(chǔ)上加以改進的,主要添加了一個高值域和非葉子結(jié)點指向其右兄弟結(jié)點的Link指針。B_Link樹結(jié)構(gòu)如圖3所示,其中帶下劃線的表示高值域,主要用于提升并發(fā)操作的性能。Link指針可以使得每個結(jié)點至少可以有兩條路徑訪問到,提高了查詢速度。
2.2 B_Link樹的查詢操作
B_Link樹的查詢操作是比較容易的,具體操作可查閱參考文獻[1]。其基本思路是:首先檢查根結(jié)點,找到大于查詢關(guān)鍵字V的最小搜索碼值(假設(shè)搜索碼值為ki);然后,順著指針pi到達另一個結(jié)點,如果查詢關(guān)鍵字比該結(jié)點所有關(guān)鍵字都大,則遍歷指針指向當(dāng)前結(jié)點的右兄弟結(jié)點,在達到最后一層葉子結(jié)點時,若找到則返回該結(jié)點,否則返回空。
2.3 B_Link樹的插入操作
B_Link樹的插入操作是一個比較復(fù)雜的過程,既要保證B_Link樹的基本結(jié)構(gòu)不受到破壞,還要保證并發(fā)操作時不會出現(xiàn)錯誤,所以有必要進行加鎖處理。下面介紹幾種操作:
(1)x←scannode(v,A):掃描指針A指向的結(jié)點,找到能發(fā)現(xiàn)key值v的下一個節(jié)點并賦給x。
(2)A←get(current):表示將current結(jié)點讀入內(nèi)存中并把其指針賦給A。
(3)A←node.insert(A,w,v):把指針w和帶關(guān)鍵字v插入指針A指向的結(jié)點。
(4)u←allocate(B):為結(jié)點B在磁盤中分配一新的頁,并將其指針賦給u。
(5)A,B←rearrange old A:把需要分裂的A指向的結(jié)點分裂成新的由A和B指向的結(jié)點。
(6)lock(current):表示將current結(jié)點鎖住,防止其他并發(fā)操作對該結(jié)點進行修改,但這并不會鎖住查詢操作。需要說明的是:如果查詢某個結(jié)點時,這個結(jié)點進行了分裂操作,有可能會出現(xiàn)查詢關(guān)鍵字大于高值域的情況,這時只要將當(dāng)前指針指向右兄弟結(jié)點即可,并在父結(jié)點中添加一搜索碼和指針指向右兄弟結(jié)點(細(xì)節(jié)可參考文獻[1])。
下面是插入算法的偽代碼:
Procedure insert(v)
initialize stack;//初始化一個堆棧,用于保存祖先結(jié)點
current←root;
A←get(current);
//將current讀入內(nèi)存中并將其指針賦給A
while current is not a leaf do
//從上至下遍歷結(jié)點,直到葉子結(jié)點
Begin
t←current;
current←scannode(v,A);
if new current was not link pointer in A then
push(t);
A ← get(current);
end;
lock(current); //將該結(jié)點鎖住
A←get(current);
move.right;
//如果有必要將當(dāng)前結(jié)點指向其右兄弟結(jié)點
if v is in A then stop
//如果原來的樹中存在關(guān)鍵字為v的結(jié)點,則算法停止
w←pointer to pages allocated for record associated with v; //把與v相關(guān)聯(lián)的指針賦給w
Doinsertion:
if A not need to split //若結(jié)點無須分裂
Begin
A←node.insert(A. w. v);
//把w指針和關(guān)鍵字v插入A指向的結(jié)點中,返回新的指針A
put(A, current);
//把指針A放入current結(jié)點適當(dāng)?shù)奈恢?br />
unlock(current);
end else begin
u←allocate(1 new page for B);
A,B←rearrange old A,adding v and w, to make 2 nodes;//把A指向的結(jié)點 分裂成2個結(jié)點,
//分別由A和B指向
(link ptr of A, link ptr of B)←(u, link ptr of old A);
//把分裂出的新結(jié)點的右兄弟結(jié)點指針
//指向未分裂前A的右兄弟結(jié)點
y←getmaxvalue(A);
//取出A指向的結(jié)點中的最大的值(注意不是高值域)
put(B,u);
put(A, current); //開始將指針放入父結(jié)點中
v ← y;
w ← u;
current ← pop(stack);
//進行回溯處理,檢測父親是否需要繼續(xù)分裂
lock(current);
A ← get(current);
move.right;
unlock(oldnode);
goto Doinsertion;
end
其中的move.right操作表示將指針指向其右兄弟結(jié)點。對于刪除算法,基本思路與插入算法類相同,要保持樹結(jié)構(gòu)和并發(fā)操作的正確性,具體可參閱文獻[2]。此外,充分利用內(nèi)存中的緩存也是很是重要的,在這里可以采用一種預(yù)讀取的辦法,即在磁盤緩存中檢索到要讀的結(jié)點時,在傳輸數(shù)據(jù)這段時間里可以將接下來的一些記錄數(shù)據(jù)塊讀入內(nèi)存緩存中,這樣在下次取數(shù)據(jù)時可以減少一些磁盤IO操作,提高讀取性能。
3 性能測試分析
測試環(huán)境如下:
數(shù)據(jù)庫服務(wù)器端配置:數(shù)據(jù)庫Oracle 10g,操作系統(tǒng)Linux 2.6,CPU 2.1 GHz X4,內(nèi)存4 GB,硬盤串口500 GB。查詢中間件服務(wù)器與數(shù)據(jù)庫服務(wù)器是同樣的配置,但不在同一臺服務(wù)器上,對查詢中間件的介紹可以參閱文獻[3]。
客戶端配置:CPU 2.6 GHz X2,內(nèi)存2 GB,硬盤串口160 GB。表1和表2是在不同的并發(fā)查詢數(shù)目和不同的查詢規(guī)模下經(jīng)過緩存和未經(jīng)緩存所需時間的對比。表1中查詢記錄數(shù)固定為10萬條,表2中并發(fā)查詢數(shù)固定為50個。
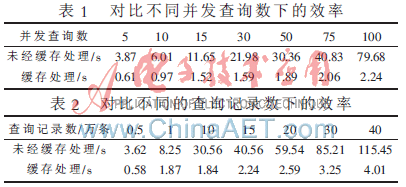
通過對比直接查詢數(shù)據(jù)庫和經(jīng)過緩存優(yōu)化后進行查詢的實驗數(shù)據(jù)可知,通對對數(shù)據(jù)進行緩存處理,效率提升是非常明顯的,尤其是在并發(fā)查詢的數(shù)量比較大時,效率提升更為明顯。
本文把數(shù)據(jù)緩存應(yīng)用于基于數(shù)據(jù)倉庫方式的數(shù)據(jù)集成中,而且,在組織緩存時采用了兩級緩存結(jié)構(gòu),并采用了B_Link樹來組織磁盤中的緩存中的結(jié)構(gòu)。因此提高了并發(fā)查詢數(shù)據(jù)的效率、縮短了客戶端查詢數(shù)據(jù)的響應(yīng)時間、提高了工作效率。但本文方法還存在一些不足,例如,如何更有效地協(xié)調(diào)磁盤和內(nèi)存中的緩存交互,這一設(shè)計的好壞也直接關(guān)系到查詢的性能,這有待以后進一步完善和優(yōu)化。
參考文獻
[1] PHILIP L, LEHMAN S, Bing Yao. Efficient locking for concurrent operations on B-trees[M]. ACM Transactions on Database Systems,1981:655-663.
[2] 孫兆玉,黃宇光,朱鴻宇. 一種基于B_Link樹結(jié)構(gòu)的高性能緩存機制[J].高性能計算技術(shù),2007,186:23-24.
[3] 房元平,許嬌陽,葛珂.流水線處理技術(shù)在數(shù)據(jù)集成中的應(yīng)用[J].微型機與應(yīng)用,2010(24):67-69.
[4] JOHNSON T. A highly concurrent priority queue based on the B_Link tree[R]. Technical Report,University of Florida,1991.
[5] CORMEN T H, CHARLES E. LEISERSON R L, et al. Introduction to algorithms(second edition)[M]. The MIT Press, 2009:434-453.