
PCIE(PCI express)是用來(lái)互聯(lián)諸如計(jì)算機(jī)和通信平臺(tái)應(yīng)用中外圍設(shè)備的第三代高性能I/0總線。PCIE體系結(jié)構(gòu)繼承了第二代總線體系結(jié)構(gòu)最有用的特點(diǎn),采用與PCI相同的使用模型和讀/寫通信模型,支持各種常見的事務(wù)。其存儲(chǔ)器、I/0和配置地址空間與PCI的地址空間相同。由于地址空間模型沒有變化,所以現(xiàn)有的OS和驅(qū)動(dòng)軟件無(wú)需進(jìn)行修改就可以在PCIE系統(tǒng)上運(yùn)行。
PCIE是串行協(xié)議,與原有的PCI并行總線相比,它沒有大量的數(shù)據(jù)和控制線,對(duì)于硬件電路設(shè)計(jì)者來(lái)說(shuō),省去了很多硬件設(shè)計(jì)工作。PCIE的傳輸速度遠(yuǎn)遠(yuǎn)大于PCI總線,PCIE1.1版本單個(gè)鏈路的單向吞吐量能達(dá)到250 MB/s。對(duì)于需要與主機(jī)進(jìn)行大容量傳輸?shù)南到y(tǒng)來(lái)說(shuō),該總線標(biāo)準(zhǔn)的優(yōu)勢(shì)是非常明顯的。
由于PCIE總線硬件設(shè)計(jì)簡(jiǎn)單,吞吐量大,軟件向下兼容,只要找到合適的總線接口芯片,很容易將現(xiàn)有的PCI總線設(shè)備升級(jí)為PCIExpress設(shè)備。Altera公司最新推出的EP2SGX90系列的芯片,給用戶提供了PCIE接口IP核。本文將結(jié)合實(shí)際的應(yīng)用,詳細(xì)介紹該IP核的使用情況,包括寄存器設(shè)置,DMA操作等。
1 功能描述及參數(shù)設(shè)置
按照PCIE協(xié)議的要求,該FPGA的IP核也采用三層體系結(jié)構(gòu),即傳輸層、數(shù)據(jù)鏈路層和物理層。這三層功能模塊完成了PCIE的協(xié)議轉(zhuǎn)換,在傳輸層上給開發(fā)人員提供了非常豐富的接口。開發(fā)人員的所有開發(fā),包括DMA傳輸等都是在傳輸層以上進(jìn)行的。
傳輸層(transaction layer):完成TLP(數(shù)據(jù)傳輸包)的收發(fā),含有虛擬信道(VC)緩沖區(qū),具有端口仲裁、VC仲裁、流控制、數(shù)據(jù)重新排序和數(shù)據(jù)校驗(yàn)等功能。
數(shù)據(jù)鏈路層(data link layer):數(shù)據(jù)鏈路層的主要功能是保證在各鏈路上發(fā)送和接收數(shù)據(jù)包時(shí)數(shù)據(jù)的完整性。在接收端,對(duì)數(shù)據(jù)進(jìn)行嚴(yán)格的CRC校驗(yàn),如果有錯(cuò)誤,會(huì)給發(fā)送方返回1個(gè)NAK信號(hào)。發(fā)送端具有重傳緩沖區(qū),如果收到NAK信號(hào),則把數(shù)據(jù)重新發(fā)送1次。
物理層(physical layer):對(duì)于發(fā)送端,接收數(shù)據(jù)鏈路層的數(shù)據(jù)包,把這些數(shù)據(jù)進(jìn)行8 b/10 b編碼,送到串行發(fā)送器上;對(duì)于接收端則剛好相反,收到串行碼后,先解碼,然后送給數(shù)據(jù)鏈路層。
在生成PCIE的IP核時(shí),至少選擇2個(gè)存儲(chǔ)區(qū),一個(gè)是BAR[1:O],用作用戶開發(fā)板的擴(kuò)展存儲(chǔ)區(qū)用;還有一個(gè)是BAR2,下面所有的寄存器操作都是基于該地址的。新生成的IP核不帶有DMA功能,但是在工程文件夾下面有一個(gè)xxxx_examples(xxx代表工程名稱)的文件夾,文件夾里有簡(jiǎn)單DMA和鏈?zhǔn)紻MA的例子代碼,開發(fā)者只需要對(duì)這些代碼進(jìn)行修改,就能開發(fā)出適合自己的DMA功能模塊。
2 簡(jiǎn)單DMA
該DMA傳輸模式相對(duì)比較簡(jiǎn)單,只需要對(duì)相應(yīng)的寄存器進(jìn)行設(shè)置即可完成,DMA傳輸步驟如下所示,每進(jìn)行1次DMA傳輸,都需要按照下面的步驟進(jìn)行1次設(shè)置。下面所述的偏移量都是相對(duì)于BAR2地址。
(1)設(shè)置偏移量為0x00和0x04的寄存器,寫入DMA傳輸?shù)闹鳈C(jī)端地址;
(2)設(shè)置偏移量為0x14的寄存器,寫入DMA傳輸?shù)腜CIE端點(diǎn)地址;
(3)在偏移量為0x08的寄存器中寫入本次DMA傳輸?shù)拈L(zhǎng)度,以字節(jié)為單位;
(4)設(shè)置偏移量為0x0C的寄存器,設(shè)置DMA傳輸?shù)膶傩裕瑢?duì)該寄存器的寫操作將啟動(dòng)本次DMA傳輸;
(5)讀取0x0C的寄存器DMA傳輸狀態(tài)位,察看本次DMA是否完成。
《電子設(shè)計(jì)技術(shù)》網(wǎng)站版權(quán)所有,謝絕轉(zhuǎn)載
3 鏈?zhǔn)紻MA
鏈?zhǔn)紻MA是一種效率遠(yuǎn)遠(yuǎn)高于簡(jiǎn)單DMA的傳輸方式,它只需要1次啟動(dòng)操作,就可以完成多次DMA傳輸。這里將結(jié)合實(shí)際使用情況,詳細(xì)介紹鏈?zhǔn)紻MA的傳輸過程。
3.1 描述符表
實(shí)現(xiàn)鏈?zhǔn)紻MA傳輸時(shí),需要開發(fā)人員在主機(jī)內(nèi)存中開辟一塊空間,用來(lái)存儲(chǔ)描述符表,它由一個(gè)表頭和多個(gè)描述符組成,其中每一個(gè)描述符對(duì)應(yīng)一次DMA操作。用戶根據(jù)自己的需求填寫該描述符表,關(guān)于該描述符表的詳細(xì)說(shuō)明如表1和表2所示。
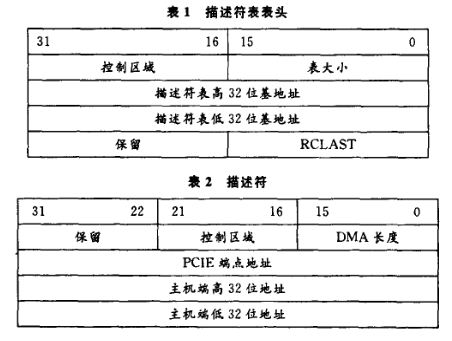
鏈?zhǔn)紻MA傳輸時(shí)用來(lái)存儲(chǔ)描述符表說(shuō)明圖
控制區(qū)域中含有一些控制信息,其中第16位用來(lái)控制傳輸方向,為O是DMA寫,為1是DMA讀,這里的讀/寫是以主機(jī)端為參考的,如果以PCIE核為參考,方向剛好相反。第18位用來(lái)使能DMA傳輸計(jì)數(shù),如果該位使能為1,那么在DMA傳輸過程中,PCIE核每完成1次DMA操作,都會(huì)進(jìn)行1次計(jì)數(shù)操作,然后把這個(gè)計(jì)數(shù)結(jié)果傳送給主機(jī),主機(jī)把這個(gè)結(jié)果填寫到描述符表的RCLAST字段中。
表大小是指本次鏈?zhǔn)紻MA操作對(duì)應(yīng)的描述符個(gè)數(shù),每個(gè)描述符對(duì)應(yīng)一次DMA操作。
RCLAST是一個(gè)計(jì)數(shù)單元,它有兩個(gè)作用,在鏈?zhǔn)紻MA傳輸前,表示還有多少個(gè)DMA操作等待傳輸,由于它是從0開始計(jì)數(shù)的,所以這個(gè)值等于表大小減1。還有一個(gè)重要作用是在鏈?zhǔn)紻MA傳輸過程中,用來(lái)表示鏈?zhǔn)紻MA傳輸?shù)臓顟B(tài)。如上所述,如果控制區(qū)域的第18位設(shè)置為1,那么每完成1次DMA操作,主機(jī)都會(huì)更新這個(gè)計(jì)數(shù)器。當(dāng)計(jì)數(shù)器的數(shù)值(也是從O開始計(jì)數(shù)的)等于前面設(shè)置的期望傳輸?shù)腄MA次數(shù),就表示鏈?zhǔn)紻MA傳輸操作結(jié)束。開發(fā)人員可以用這個(gè)狀態(tài)單元來(lái)察看本次傳輸是否結(jié)束,從而開始一個(gè)新的傳輸周期。
DMA長(zhǎng)度用來(lái)設(shè)置本描述符對(duì)應(yīng)的DMA傳輸?shù)拈L(zhǎng)度,是以32位為單位的。主機(jī)端地址用來(lái)指示數(shù)據(jù)存放存放的位置。
3. 2 實(shí)現(xiàn)范例
根據(jù)上面介紹的描述符表,下面給出一個(gè)鏈?zhǔn)紻MA讀的驅(qū)動(dòng)程序例子。首先生成一個(gè)描述符表,然后把描述符表表頭的4個(gè)字段的內(nèi)容分別寫入BAR2地址偏移量為0x0,0x4,0x8和0xC寄存器中。寫完后即開始此次鏈?zhǔn)紻MA讀傳輸,while循環(huán)用于等待鏈?zhǔn)紻MA結(jié)束。從下面的代碼可以看出,2個(gè)描述符對(duì)應(yīng)2次DMA操作。

鏈?zhǔn)紻MA讀的驅(qū)動(dòng)程序

鏈?zhǔn)紻MA讀的驅(qū)動(dòng)程序
圖1是用SignalTap工具獲取的鏈?zhǔn)紻MA讀時(shí)序圖。PCIE核接收tx_req0請(qǐng)求信號(hào),然后給出一個(gè)tx_ack0,同時(shí)將tx_dr0置為有效,該信號(hào)套住的TXData就是需要讀取的有效數(shù)據(jù)。在每次DMA結(jié)束之后,PCIE核都會(huì)用同樣的控制邏輯給主機(jī)傳送1個(gè)已完成DMA次數(shù)的狀態(tài)字,如圖1中的44040000h。
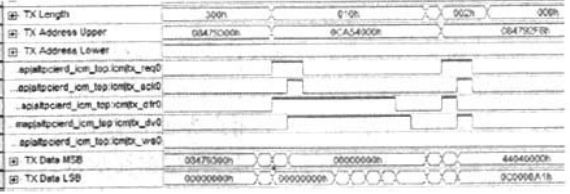
鏈?zhǔn)紻MA傳輸時(shí)序圖
4 性能測(cè)試
在做總線性能測(cè)試時(shí),采用鏈?zhǔn)紻MA傳輸方式,共4個(gè)描述符表。根據(jù)實(shí)際使用的PCIE總線通道數(shù)和DMA長(zhǎng)度的不同,實(shí)際測(cè)試得到的總線速度也不同,表3給出了參考數(shù)據(jù)。
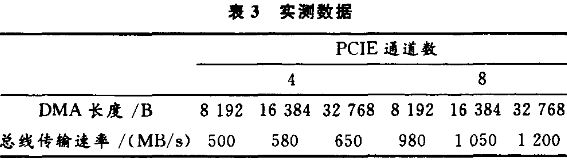
總線性能測(cè)試圖
5 結(jié)語(yǔ)
使用FPGA來(lái)設(shè)計(jì)PCIE總線擴(kuò)展卡,可以省去專用的PCIE接口芯片,降低了硬件設(shè)計(jì)成本,提高了硬件的集成度。利用FPGA的可編程特性,大大提高了設(shè)計(jì)靈活性、適應(yīng)性和可擴(kuò)展性。PCIE總線提供了高速、獨(dú)享的數(shù)據(jù)交換通道,確保在大數(shù)據(jù)量的數(shù)據(jù)交換時(shí)不會(huì)出現(xiàn)瓶頸,而且作為新一代總線,它使系統(tǒng)在獲得更高性能的同時(shí),具有了良好的升級(jí)性。