
摘 要: 針對異構(gòu)集群并行效率不高的特點,通過分析由于計算系統(tǒng)設(shè)計不合理而產(chǎn)生的種種問題,提出了一種基于異構(gòu)環(huán)境下的樹型計算系統(tǒng),用以兼容各類計算平臺,降低全局通信流量和均衡主控節(jié)點負載,從而改善集群通信效率,使集群的擴展更加靈活,并且通過實驗驗證了該系統(tǒng)的可行性。
關(guān)鍵詞: MPI;組通信;廣播;收集;Linux
近年來,為了滿足不斷增長的計算能力的需求,將已有的若干個不同的計算平臺(計算主機或計算網(wǎng)絡(luò))互連并改造成高性能集群系統(tǒng)是一種性價比較高的實現(xiàn)方式。然而集群規(guī)模的增大并沒有帶來絕對計算速度和并行效率的提升,伴隨而來的卻是全局通信(尤其是組通信)流量猛增,網(wǎng)絡(luò)堵塞嚴重,操作響應(yīng)遲滯,以至計算性能下降。
1 分析問題
經(jīng)過對此類異構(gòu)集群的研究和分析,計算系統(tǒng)設(shè)計的不合理應(yīng)是造成該集群計算性能下降的主要原因之一。其理由是:在現(xiàn)有的計算系統(tǒng)中,大多是在不考慮集群網(wǎng)絡(luò)或處理機的性能差異的情況下對網(wǎng)絡(luò)進行模型化,然后在此模型及其參數(shù)值基礎(chǔ)上構(gòu)造出最優(yōu)算法來實現(xiàn)通信。這樣的方法固然能夠定量地分析算法的描述精度,更能精確地給出通信時間的統(tǒng)計公式,這對計算系統(tǒng)的分析和設(shè)計是有指導(dǎo)意義的,但同時也存在著一些問題,就是它們假定計算中的所有進程對(發(fā)送進程和接收進程稱為進程對)之間的通信時間都是相等的。而實際情況卻并非如此,不同的處理器速度、不同的內(nèi)部結(jié)構(gòu)(單核或多核)以及集群內(nèi)部存在著不同類型的網(wǎng)絡(luò)和不同的連接方式,這些都會造成通信延遲的差異,所以此種模型構(gòu)造出的集群系統(tǒng)與實際應(yīng)用是有差距的。具體表現(xiàn)在應(yīng)用的透明性不足[1]、集群框架結(jié)構(gòu)[2]和編程模型的選用不合理。
2 解決問題
解決問題思路就是在粒度、通信開銷和計算資源三者之間尋找最佳平衡點,并以此平衡點來組織集群,以達到性能提升的目的。本文將具體的網(wǎng)絡(luò)拓撲信息作為主要建模依據(jù),提出了一種基于異構(gòu)集群環(huán)境下采用樹型結(jié)構(gòu)的計算系統(tǒng),用以確定適合并行任務(wù)的粒度、降低通信開銷和提高計算資源利用率,進而改善集群計算環(huán)境。
2.1 樹型組通信系統(tǒng)的提出
2.1.1 樹型結(jié)構(gòu)介紹
樹型結(jié)構(gòu)是針對單層型結(jié)構(gòu)在消息廣播和消息收集方面速度慢、可擴展性差的弱點而提出的新的集群框架結(jié)構(gòu)。圖1所示的是典型的樹型結(jié)構(gòu)。與單層型結(jié)構(gòu)一樣,樹型結(jié)構(gòu)也有主控節(jié)點(根節(jié)點)和從屬節(jié)點(葉子節(jié)點),且功能與單層型結(jié)構(gòu)類似。不同的是,樹型結(jié)構(gòu)中還包含分支節(jié)點,這些分支節(jié)點是樹的內(nèi)部節(jié)點,沒有計算功能,沒有系統(tǒng)認證、網(wǎng)絡(luò)管理和遠程控制等功能,只有對消息的轉(zhuǎn)發(fā)、分發(fā)和收集功能,所以也叫路由節(jié)點。如圖1所示,根節(jié)點與其下一層的分支節(jié)點有直接的通信連接。同樣,每個分支節(jié)點都與其下一層的節(jié)點有直接通信連接,上層節(jié)點與下層節(jié)點可以實現(xiàn)組通信,而擁有同一個父親的同層節(jié)點之間可以進行點到點通信。除此以外,其他非同父節(jié)點相互之間沒有建立直接的通信連接。
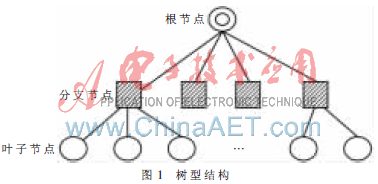
樹型結(jié)構(gòu)集群可以將全局通信域劃分為多個子通信域,并且可以將主控節(jié)點的負載量分擔(dān)到各個分支節(jié)點上,降低全局通信量進而改善集群計算環(huán)境。隨著樹的深度的增加,使得集群更易于擴展。但該集群實現(xiàn)起來比較復(fù)雜,且沒有專用的協(xié)議、應(yīng)用軟件或集群工具的支持[3]。樹型結(jié)構(gòu)的消息廣播和消息收集的時間復(fù)雜度均為O(logn)。
2.1.2 異構(gòu)環(huán)境下樹型計算系統(tǒng)
在異構(gòu)環(huán)境下集群成員間彼此通信差異很大,有的使用廣域網(wǎng)技術(shù)通信,有的在局域網(wǎng)內(nèi)通信,還有的通信在機器內(nèi)部進行,所有這些相互通信的進程對之間的通信時間是不可能相等的。所以延用已有的計算系統(tǒng)不可能最優(yōu)。
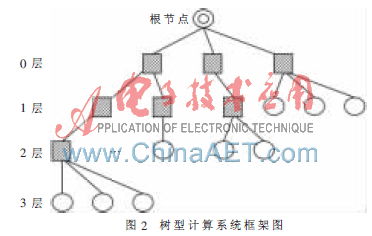
系統(tǒng)采用如圖2所示的樹型結(jié)構(gòu),根節(jié)點為主控節(jié)點,葉子節(jié)點為計算節(jié)點(圖中圓形節(jié)點),此外還有路由節(jié)點(圖中方形節(jié)點)用于連接上下層節(jié)點或網(wǎng)絡(luò),整個系統(tǒng)按通信速度分層,各層的通信速度從第0層到最后一層依次升高,第0層的通信最慢,最底層的通信最快。通常根據(jù)一般情況下節(jié)點機的計算速度或子網(wǎng)中延遲的大小來評定各節(jié)點機或子網(wǎng)通信速度的快慢。例如,對于集群子網(wǎng)中存在10 M以太網(wǎng)計算平臺、100 M以太網(wǎng)計算平臺和SMP節(jié)點機,顯然SMP是機內(nèi)通信,通信速度是三者之中最高的,應(yīng)放在最底層(圖中第3層);10 M以太網(wǎng)的通信帶寬明顯低于100 M以太網(wǎng),所以應(yīng)放在最上層(圖中第1層),100 M以太網(wǎng)的放在中間層(圖中第2層)。
2.2 OpenMP+MPI混合編程模型機制
在前面提到,由于異構(gòu)環(huán)境下各節(jié)點機或計算平臺的粒度并行化程度不一,采用統(tǒng)一的編程方式勢必會顧此失彼,所以依據(jù)各節(jié)點機或計算平臺的實際情況,各取所長,采用混合編程MPI+OpenMP方式應(yīng)是較好的選擇[4]。
2.2.1 MPI編程方式
MPI(Message Passing Interface)是消息傳遞接口的工業(yè)標準,為用戶提供一個實際可用、可移植、高效、靈活的消息傳遞接口庫。相對其他并行編程模型,由于其既可以在分布式系統(tǒng)又可以在共享內(nèi)存系統(tǒng)中運行,同時可以移植到包括NT和Unix在內(nèi)的幾乎所有系統(tǒng),所以非常適合異構(gòu)環(huán)境下的集群通信。目前有關(guān)MPI的產(chǎn)品很多,主要有LAM/MPI、LA-MPI、FT-MPI和PACX-MPI,其中Open MPI結(jié)合了上述幾種工具的優(yōu)點,有望成為下一代MPI系統(tǒng)的主導(dǎo)者,它在異構(gòu)環(huán)境下的作業(yè)管理、異構(gòu)處理器、異構(gòu)網(wǎng)絡(luò)協(xié)議等方面提供了較為全面的技術(shù)支持,是目前對異構(gòu)計算環(huán)境支持較好的MPI實現(xiàn)系統(tǒng)。在本模型中,采用Open MPI集群工具,用于負責(zé)集群內(nèi)節(jié)點間通信。
2.2.2 OpenMP編程方式
異構(gòu)環(huán)境中,對于擁有多核處理器的節(jié)點機或計算平臺,由于其采用共享存儲系統(tǒng)的方式來進行計算和通信,采用MPI編程模式并不合適,其主要理由是:在該系統(tǒng)上MPI的消息傳送是通過存儲器中的共享消息緩沖區(qū)來實現(xiàn)的,所以對于較小的數(shù)據(jù)傳送量(粒度),其通信效率較低;而在進行大塊的數(shù)據(jù)傳送時,通信效率則較好。但由于共享消息緩沖區(qū)的容量有限,所以當通信量超過共享消息緩沖區(qū)的容量時,通信速率將下降。此外,一些MPI應(yīng)用需要特定數(shù)量的進程運行,當MPI所需進程數(shù)與節(jié)點機處理器數(shù)不相等時,該系統(tǒng)將無法運行,進而降低了節(jié)點機的利用率。所以在此系統(tǒng)下應(yīng)選擇基于共享存儲的編程方式,通過共享變量實現(xiàn)線程間通信和線程級并行。OpenMP是共享內(nèi)存編程的工業(yè)標準,它規(guī)范了一系列編譯制導(dǎo)、子程序庫和環(huán)境變量,采用 Fork-Join 的并行執(zhí)行模式實現(xiàn)線程級并行。制導(dǎo)語句提供對并行區(qū)域、工作共享的支持,且支持數(shù)據(jù)私有化。在本模型中,采用OpenMP集群工具負責(zé)節(jié)點內(nèi)通信。
2.2.3 如何實現(xiàn)MPI與OpenMP的混合編程
(1)原則上以MPI編程為主,OpenMP編程為輔,這樣才能更符合異構(gòu)環(huán)境的特點;
(2)每個節(jié)點上都應(yīng)有MPI進程,使得整個集群為一個MPI集群;
(3)對于多核環(huán)境或SMP體系結(jié)構(gòu)的,MPI進程中的計算部分(尤其是循環(huán)部分)應(yīng)交由OpenMP多線程并行求解(以嵌入編程方式實現(xiàn));
(4)OpenMP多線程求解部分可以與MPI進程的局部計算、通信或同步操作穿插進行;
(5)OpenMP求解部分結(jié)束后,應(yīng)返回并繼續(xù)MPI進程,直至MPI進程結(jié)束。
2.3 路由節(jié)點的構(gòu)造
樹形結(jié)構(gòu)中的分支節(jié)點用于連接根節(jié)點(主控節(jié)點)和葉子節(jié)點(計算節(jié)點),在整個集群中發(fā)揮兩個作用:一個是承上啟下的連接作用,另一個則是對根節(jié)點(主控節(jié)點)的分擔(dān)作用,所以分支節(jié)點應(yīng)具有路由和對消息的傳遞、分發(fā)和收集等功能。
這里,以集群中采用統(tǒng)一的TCP/IP協(xié)議為例來構(gòu)造一個分支節(jié)點。首先在分支節(jié)點機上安裝兩塊網(wǎng)卡,一塊連接上層節(jié)點(根節(jié)點或上層的分支節(jié)點),IP地址設(shè)置在上層節(jié)點的同一個網(wǎng)段內(nèi),默認網(wǎng)關(guān)指向上層節(jié)點(父節(jié)點),使其成為上層網(wǎng)絡(luò)的成員;另一塊連接下層節(jié)點(下層的分支節(jié)點或葉子節(jié)點),設(shè)置IP地址(最好與前一塊網(wǎng)卡的IP地址不同網(wǎng)段),為下層網(wǎng)絡(luò)提供網(wǎng)關(guān)服務(wù)。但若要在上下層兩個網(wǎng)絡(luò)實現(xiàn)路由,需要在分支節(jié)點上修改/etc/sysctl.conf配置文件中的net.ipv4.ip_forward=1(以Linux操作系統(tǒng)為平臺參考),使得本節(jié)點機IP轉(zhuǎn)發(fā)功能生效。這樣做的目的是既能實現(xiàn)上下兩層網(wǎng)絡(luò)之間的通信,同時又能阻止基于網(wǎng)絡(luò)第二層的廣播幀的傳播。若集群中存在不同網(wǎng)絡(luò)協(xié)議,則在構(gòu)造分支節(jié)點機時,除了安裝兩塊網(wǎng)卡和相應(yīng)的網(wǎng)絡(luò)協(xié)議之外,還要依托MPI通信機制實現(xiàn)協(xié)議之間的通信。
2.4 進程組和通信域的設(shè)計
MPI中的通信域(Communicator)提供了一種組織和管理進程間通信的方法。每個通信域包括一組MPI進程,稱為進程組。這一組進程之間可以相互通信,而且這個通信域內(nèi)的通信不會跨越通信域的邊界。這樣就提供了一種安全的消息傳遞的機制,因為它隔離了內(nèi)部和外部的通信,避免了不必要的同步。每個進程都至少在某個特定的通信域中,但有可能進程在多個通信域中的情形,這就像某個人可以是多個組織的成員一樣。進程組由一個進程的有序序列進行描述,每個進程根據(jù)在序列中的位置被賦予一個進程號(0,1,…,N-1)[5]。
這里,將根節(jié)點與其相鄰的下一層節(jié)點(孩子節(jié)點)劃定為一個進程組0,對分支節(jié)點1與其相鄰的下一層節(jié)點(孩子節(jié)點)劃定為進程組1,…。如此類推,直到所有分支節(jié)點或根節(jié)點都擁有自己的進程組為止,如圖3所示。由于每個分支節(jié)點或根節(jié)點都有兩塊網(wǎng)卡,所以將兩塊網(wǎng)卡分屬不同的進程組中,彼此互不包含。
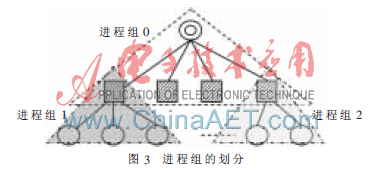
這樣的設(shè)計將全局通信域劃分成若干個子通信域,使得大量的消息傳遞開銷限制在局部,大大降低了全局通信的頻率,從而提高了集群通信的性能。
2.5 組間通信
進程組劃分之后,形成相應(yīng)的通信域,規(guī)避了大量節(jié)點間同步所消耗的開銷,但進程組之間也需要通信,根節(jié)點需要將消息逐層傳遞到葉子節(jié)點,同樣葉子節(jié)點所計算出來的結(jié)果也要逐層收集、規(guī)約到根節(jié)點,所以組間通信也是本系統(tǒng)實現(xiàn)的關(guān)鍵之一。
這里,通過使用MPI組間通信函數(shù)(如MPI_Intercomm_
create()函數(shù))來實現(xiàn)組間消息的傳遞。
3 實驗測試與分析
3.1 實驗環(huán)境和方法
本實驗將先后搭建兩種結(jié)構(gòu)的集群進行測試。其測試環(huán)境如下:
(1)第一種結(jié)構(gòu)為傳統(tǒng)的單層型MPI集群,其中有4個計算節(jié)點和1個主控節(jié)點,這4個計算節(jié)點分別由2個單核結(jié)構(gòu)節(jié)點和2個雙核結(jié)構(gòu)節(jié)點構(gòu)成,如圖4(a)所示。
(2)第二種結(jié)構(gòu)為本文提出的樹型MPI+OpenMP集群,其中有4個計算節(jié)點、1個路由節(jié)點和1個主控節(jié)點(根節(jié)點),如圖4(b)所示。

其中,每個單核節(jié)點包含一顆P Ⅳ處理器和2 GB內(nèi)存,每個雙核節(jié)點包含一顆奔騰雙核E2140處理器和2 GB內(nèi)存,操作系統(tǒng)采用Redhat Linux Enterprise 5,并行集群軟件為OPEN MPI 1.3+OpenMP。由于條件所限,加之實驗規(guī)模較小,所以本實驗采用MPI自帶的函數(shù)MPI_Wtime()來采集MPI計算的開始和結(jié)束時間,取二者的時間差作為程序的運行時間并對其進行比較和分析,用MPI_Wtick()函數(shù)來監(jiān)測MPI_Wtime()返回結(jié)果的精度。
在實驗用例設(shè)計上,考慮到兩種MPI集群的通信機制中的傳輸路徑不同,采用計算求解三對角方程組作為測試方案,主要測試通信和計算的平衡。
3.2 結(jié)果和分析
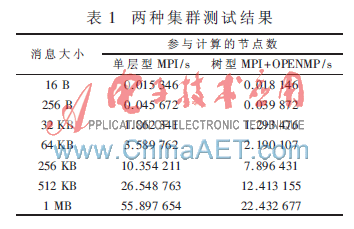
兩種集群測試結(jié)果如表1所示。可見測試結(jié)果差異較明顯,在傳輸短消息時,可以發(fā)現(xiàn)單層型集群的運算速度并不比樹型慢多少,在16 B的情況下單層型還優(yōu)于樹型。這是因為樹型結(jié)構(gòu)的集群中除了擁有和單層型相同數(shù)目的計算節(jié)點外,還有一個分支節(jié)點(也叫路由節(jié)點),分支節(jié)點需要時間在兩個通信域之間傳遞處理消息,所以樹型結(jié)構(gòu)的消息傳輸時間除了消息廣播和收集時間外,還有域間轉(zhuǎn)發(fā)處理的時間。盡管在時間復(fù)雜度上樹型結(jié)構(gòu)優(yōu)于單層型結(jié)構(gòu),但在通信域中節(jié)點數(shù)較少、消息較小的情況下,二者之間差距不是十分明顯,若再加上域間處理的時間,自然會出現(xiàn)這樣的情況。但當消息增大時,由于樹型結(jié)構(gòu)中每個通信域的廣播和收集時間遠遠小于單層結(jié)構(gòu)的廣播和收集時間,從而抵消了分支節(jié)點處理消息的時間,所以樹型的整體運算時間明顯小于單層型的運算時間。當消息大小為512 KB以后時,單層型的運算時間明顯高于樹型,這是因為雙核節(jié)點是基于共享存儲器來實現(xiàn)進程間通信的。由于事先將共享存儲器的容量設(shè)定為512 KB,所以當消息大小超過共享存儲器的容量之后,基于MPI的單層型集群的通信效率迅速下降,而樹型中的雙核節(jié)點是基于多線程共享機制的,當消息增大時反而其優(yōu)勢更加明顯。
由上分析,基于異構(gòu)環(huán)境下樹型計算系統(tǒng)是可行的。在該方案上構(gòu)建的MPI+OpenMP集群系統(tǒng)可以兼容各類計算平臺,各取所長,并使消息廣播和消息收集的通信速度明顯提高,全局通信流量明顯下降,從而提升了集群整體計算速度。同時,由于樹型結(jié)構(gòu)的特點,使得集群的擴展更加輕松。盡管從理論上可知隨著節(jié)點數(shù)的增加,該類集群的優(yōu)勢將更加凸顯,但是由于實驗條件的限制,只能對集群通信系統(tǒng)做初步驗證,所以希望在未來的研發(fā)工作中能夠引入更科學(xué)的評測體系,不斷地論證和完善該系統(tǒng),為傳統(tǒng)集群性能的升級改造提供一些幫助。
參考文獻
[1] 蔣艷凰,趙強利,盧宇彤.異構(gòu)環(huán)境下MPI通信技術(shù)研究[J].小型微型計算機系統(tǒng),2009,30(9):1724-1729.
[2] 劉洋,曹建文,李玉成.聚合通信模型的測試與分析[J]. 計算機工程與應(yīng)用,2006,42(9):30-33.
[3] CHEN C P.The parallel computing technologies(PaCT-2003)[C].Seventh International Conference,2003:15-19.
[4] 趙永華,遲學(xué)斌.基于SMP集群的MPI+OpenMP混合編程模型及有效實現(xiàn)[J].微電子學(xué)與計算機,2005,22(10):7-11.
[5] 莫則堯,袁國興.消息傳遞并行編程環(huán)境[M].北京:科學(xué)出版社,2001.