
摘 要:介紹了以ARM+DSP" title="DSP">DSP體系結構為基礎的FPGA" title="FPGA">FPGA實現(xiàn)。在其上驗證應用算法,實現(xiàn)了由ARM負責對整個程序的控制,由DSP負責對整個程序的計算,最大程度地同時發(fā)揮了ARM和DSP的各自優(yōu)勢。
關鍵詞:ARM DSP FPGA
ARM通用CPU及其開發(fā)平臺,是近年來較為流行的開發(fā)平臺之一,而由ARM+DSP的雙核體系結構,更有其獨特的功能特點:由ARM完成整個體系的控制和流程操作,由DSP完成具體的算法和計算處理。這樣,不但可以充分地發(fā)揮ARM方便的控制優(yōu)勢,同時又能最大限度地發(fā)揮DSP的計算功能。這在業(yè)界已逐漸成為一種趨勢。
本文的FPGA的Demo驗證,是在基于一款DSP內核處理器的研發(fā)基礎上,對其功能進行驗證的一個小目標識別算法的實現(xiàn)。考慮到軟件環(huán)境仿真的速度以及仿真模型的局限性,用FPGA進行硬件協(xié)同驗證。這樣,既能夠保證仿真的真實性,又能夠快速發(fā)現(xiàn)實際問題,減少不必要的流片次數(shù),加快開發(fā)的進程,這對于一個大規(guī)模的SoC設計,已經成為不可或缺的手段之一,而且對節(jié)約成本也有很大好處。
1 系統(tǒng)體系結構
雙核系統(tǒng)的體系結構如圖1所示。

1.1 內嵌ARM內核的EPXA1芯片及其特點
圖1中,包含ARM922T內核的開發(fā)平臺選用的是Altera公司的excalibar系列,本驗證實現(xiàn)選用的型號是EPXA1。EPXA1是一款帶有100萬門可重配置PLD的ARM Core+PLD體系結構,可以通過quartus II軟件工具來靈活配置ARM Core同外部的端口連接,最大時鐘頻率能夠達到200MHz。EPXA1的高度集成化,不僅大大加快了ARM與片內各種資源的通訊速度,而且減小了硬件電路的復雜性、體積和功耗,真正實現(xiàn)了SOPC[1]。
1.2 FPGA硬件平臺及其特點
對于一個具體項目,F(xiàn)PGA芯片的選取要根據(jù)實際需求和特點來具體考慮。一般應從邏輯資源需求、易擴展能力、信號質量以及成本等因素來考慮。如圖1所示,本次設計采用的兩片F(xiàn)PGA分別為Xilinx" title="Xilinx">Xilinx公司的FPGA X3S5000和X2V6000,其容量分別為500萬門和600萬門。選用這兩塊芯片正是基于邏輯資源需求的考慮。FPGA X2V6000面向高端應用,存儲資源更多,功能更強大,適用于性能要求較高的DSP內核,但其成本相對也較高;而FPGA X3S5000成本較低,適用于一般性能要求的模塊。兩片F(xiàn)PGA都具備三個擴展槽,可做接口擴展,同時也能作為調試測試點用。
1.3 雙核體系結構設計特點
具體來講,整個體系結構是指通過人為設計電路圖,外部選用不同的FPGA器件來下載生成特定功能的外部硬件電路,在電路圖上對應相應的端口標號;同時,ARM Core可以通過quartus II工具方便地連接不同的端口標號,編譯運行生成相應的配置文件;ARM的啟動代碼中用以上的的配置文件信息來配置PLD,從而實現(xiàn)ARM同外部硬件電路即兩片F(xiàn)PGA的連接[3]。FPGA X3S5000中下載固化AHBC硬件電路以及外部SRAM Memory,而FPGA X2V6000中下載固化DSP Core以及支持AMBA協(xié)議的Wrapper。
這種體系結構能夠充分利用硬件資源,合理的版圖位置方便了ARM和DSP對外部SRAM的訪問,同時可快捷地實現(xiàn)ARM的控制功能,而且預留的擴展槽能夠較為方便地進行功能擴展和調試。DSP Core的Wrapper能夠快速響應ARM的控制請求,調動DSP Core進入不同的工作狀態(tài)。
2 系統(tǒng)工作流程及特點
系統(tǒng)工作流程圖如圖2所示,介紹如下。
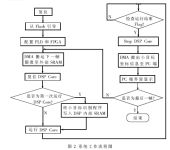
2.1 ARM負責準備階段
ARM從Flash中運行啟動代碼,通過配置PLD來連接FPGA X3S5000中的AHBC,目的在于ARM通過AHBC同F(xiàn)PGA X2V6000中的DSP Core進行交互。
代碼喚醒外部DMA通過以太網口從PC機端搬運第一幀待處理的圖像數(shù)據(jù),放到雙核公用的外部SRAM memory既定的地址段中。然后,ARM Core通過AHBC控制FPGA X2V6000中的DSP Core。
這里需要說明兩點:
(1) FPGA開發(fā)板的的圖像傳輸是通過專門配置的帶有LXT972芯片的以太網口與PC機的以太網口進行交互, 如圖3所示。圖3左邊的以太網子板即圖1中的Ethernet模塊。

(2) DSP Core頂層的wrapper是支持AMBA協(xié)議的TOP Module,其中包括一個Debug Sub-Module。ARM就是通過讀寫Debug Sub-Module的控制寄存器來控制DSP Core的啟動、停止等工作狀態(tài)的。所以說,Debug Sub-Module是整個FPGA工程最為關鍵的部件之一,它直接關系到ARM和DSP之間的交互。本項目中,利用Debug Sub-Module實現(xiàn)對DSP Core的復位、啟動、暫停、斷點設置、單步運行、讀寫內部SRAM、讀DSP Core寄存器等一系列功能,大大方便了調試工作,同時也非常便捷地實現(xiàn)了ARM和DSP的交互運行。
2.2 DSP運行階段
ARM寫控制寄存器使DSP Core復位,并把小目標識別的程序代碼寫入DSP內部的SRAM0中等待DSP啟動運行,由ARM控制DSP Core運行起來。DSP Core運行完程序之后,會在外部SRAM的一個地址上返回一個標志數(shù)(0x00ff00ff),同時進入idle狀態(tài),完全釋放對AHBC的操作。每隔一段時間,ARM檢查一下相應地址上的這個標志數(shù),如果沒有,則表示程序還未運行完,ARM繼續(xù)檢查;如果有,則表示程序已經運行完畢,ARM將進入下一步操作。
選用這種流程有兩個特點:(1)ARM完全實現(xiàn)了控制和輔助的作用,而運行部分則完全由DSP負責,各自分工明確。(2)ARM和DSP實現(xiàn)了很好的交互,嚴謹?shù)乜刂屏肆鞒痰倪\行步驟。
2.3 ARM控制停止返回
ARM通過寫控制寄存器把DSP Core停下來,從外部SRAM的既定地址段中取出DSP Core運行完所返回的小目標的坐標信息,并通過以太網口返回到PC機端,在顯示界面的此幀圖像上顯示出小目標。圖4為其中一幀圖像的處理結果顯示。

ARM擦除DSP Core運行完畢的標志數(shù),同時判斷當前處理完的圖像是否為最后一幀,如果不是,則流程跳回DMA搬運步驟去執(zhí)行下一幀圖像,同時加上必要的控制,避免寫程序的重復執(zhí)行;如果是,則結束整個程序運行。這樣循環(huán)下去,直到所有圖像序列處理完畢。
這個過程充分顯示了ARM在控制流程的判斷跳轉方面所起到的主要作用。由ARM的平臺來實現(xiàn)對整個視頻序列的最終處理控制過程,顯得非常清晰便捷。
3 體系架構的調試
3.1 FPGA的選取
FPGA的選取一定要合適(這里主要針對容量而言)。以本開發(fā)過程為例, Xilinx的兩片F(xiàn)PGA(X2V6000和X3S5000)的容量分別為600萬門和500萬門左右,而項目的硬件代碼容量卻稍微超出了這個范圍,所以不得不對一些模塊作精簡和舍棄。即便如此,兩片F(xiàn)PGA的利用率都已大于90%。
一般來說,F(xiàn)PGA的利用率達到70%或多一些是比較好的,太高的利用率反而容易造成板子的不穩(wěn)定。本開發(fā)過程就有一些不穩(wěn)定因素,例如,因一些數(shù)據(jù)線、地址線的個別位傳輸值不正確,需要花大量的精力才能追查出這些存在問題的線路,然后更換Bonding連接,選用其他的通路。同時,所造成的不穩(wěn)定因素也會影響下載代碼的運行速度。目前經過Xilinx的軟件工具ISE綜合出來的FPGA可下載代碼受時序約束,所能達到的速度上限為25MHz時鐘頻率。
容量大的FPGA的成本同樣也會比較高,所以在研發(fā)需要和成本之間必須找到一個比較好的平衡點,這在整個電路設計階段就要預測得比較好,但這不太容易做到,需要經驗的積累。
3.2 觀測點的預留
開發(fā)板在設計電路圖階段,一定要預留出足夠的觀測點。這一點非常重要。因為:在后來的調試過程中,當出現(xiàn)問題時需要追查線路,而目前的FPGA調試軟件還不成熟,并不像RTL代碼前端仿真那樣方便,能夠把所有的信號都輸出到屏幕上觀看,而且FPGA調試時使用的邏輯分析儀只能夠測量觀測點的信號波形,如果觀測點不夠的話,當出現(xiàn)邏輯錯誤時,根本沒辦法追查下去,找不到問題的所在,或者需要做相當繁瑣的重復工作,才能把估計存在問題的線路節(jié)點信號連(Bonding)到僅有的觀測點上。如果經排查,估計得不正確或者需要進一步拉出更多的其他信號時,又需要重新花時間將節(jié)點新信號連到觀測點。這樣,會耗費非常多的時間和精力。因為對每一次新的節(jié)點生成一版新的FPGA下載代碼都很煩瑣。
所以,從電路的設計之初,預留出足夠的觀測點,盡量將更多的節(jié)點信號連到觀測點上。這樣將會極大地方便調試工作,加快整個研發(fā)進程。
3.3 FPGA調試的原則
FPGA的調試應該按照由簡入繁的步驟進行。這樣可以方便研發(fā)人員快速地熟悉板子,并且容易定位問題的所在。
由于整個ARM+DSP體系結構是由ARM加上兩塊FPGA共同工作,相對比較復雜,相互之間交互性比較多。所以,在調試整個程序之前,可以先通過另外的小程序和硬件結構分別調通ARM對兩片F(xiàn)PGA的交互;然后,再用較為簡單的功能模塊調試好三塊片子的簡單交互功能;最后,把整個大程序應用在上面進行嘗試。這樣一步步下來,出現(xiàn)問題時,就比較容易發(fā)現(xiàn)問題所在,方便調試。
例如,可以先不考慮FPGA X2V6000,單獨調試ARM通過FPGA X3S5000中的AHBC對外部SRAM讀寫的控制,成功之后,再將FPGA X2V6000考慮進去,但先不考慮Debug模塊對DSP的控制,單獨將Debug模塊提取出來,下載到FPGA X2V6000當中;然后再調試ARM通過FPGA X3S5000中的AHBC對于FPGA X2V6000當中的Debug模塊的控制寄存器的讀寫情況等。
3.4 軟硬件協(xié)同驗證
軟硬件協(xié)同驗證是較好的驗證方式(或調試方式),二者都是為了保證系統(tǒng)功能和結構正確的有效手段。在整個FPGA系統(tǒng)實現(xiàn)過程中,非常有必要結合前端軟件仿真波形來參照調試系統(tǒng)各個環(huán)節(jié)的功能運行情況,這樣可以大大簡化研發(fā)進程,有效地縮短調試周期。可以說,如果不結合前端軟件仿真波形來協(xié)同驗證的話,要想實現(xiàn)一個較為復雜的體系結構是非常困難的。
一般而言,對于這樣一個較為復雜的體系結構需要先進行前端RTL代碼的軟件仿真,因為前端仿真對于糾正RTL級代碼以及功能方面的錯誤是非常方便的,而且它所需要的驗證周期和糾錯難度比硬件的FPGA驗證要有利得多。但是FPGA硬件驗證,其真實性又是非常可靠的。所以驗證波形完全調試通過之后,可以非常有效地指導FPGA的實現(xiàn)。當FPGA在調試某項功能時出現(xiàn)了問題,可以通過邏輯分析儀將可疑端口節(jié)點出來的觀測點波形導出來對照軟件仿真波形來查找問題,這是一種非常有效的手段。
3.5 Demo演示速度的調整
目前,開發(fā)板選用的晶振頻率為24MHz,穩(wěn)定的演示版本速度能夠達到28幀/秒,為人眼所能接受的連續(xù)視頻速度,效果已經相當好。這是經過了各種調試才達到的效果。主要原因在于考慮比較周全:DMA在傳輸圖像序列的時候,所用到的FIFO在設計之初就考慮到了FPGA的容量和利用率,認識到其容量有限,在現(xiàn)有的FIFO容量下,要想調整到一個DMA與PC機雙方網口傳輸速度的精確狀態(tài)不太容易,如果運行速度太快,交互同步不準確,就會有丟包的現(xiàn)象發(fā)生;如果為了更方便的調試和達到更好的速度性能,可以選用更大容量的FPGA,設計更大容量的FIFO,這樣每一次圖像傳輸就可以傳送更多的圖像數(shù)據(jù),減少DMA搬運的次數(shù),傳輸雙方的交互過程較為容易控制。表1給出了從開始演示速度不理想到較為理想所做的調整過程。從表1中可以看出,單獨調整晶振頻率,速度提升并不明顯。這說明了速度瓶頸不在硬件代碼性能上,關鍵在于演示界面的軟件代碼、ARM的Cache打開與否以及圖像搬運的速度三方面。同時還可以看出Cache的打開對于速度影響很大,說明ARM的取指速度受到影響。目前ARM的運行指令是放在Flash中,如果改成從SRAM中取指,估計效果會更加理想。

從以上分析可見,ARM在整個設計中所起的主要作用是控制圖像的輸入輸出,以及循環(huán)控制DSP Core的運行停止等狀態(tài);DSP Core的主要作用是處理運算應用程序,計算小目標識別程序。這樣既分工又合作,能夠充分發(fā)揮ARM的控制功能以及DSP Core的數(shù)字運算處理功能。
與此同時,由于ARM在整個設計當中主要起到一些輔助的控制作用,ARM922T的一些擴展DSP運算功能沒有用到,如果綜合考慮到成本和性價比等因素,可以考慮采用ARM7硬核、NIOS 或其他形式的軟核替代。
參考文獻
[1] FURBER S,田澤,于敦山.ARM SOC體系結構.盛世敏,譯.北京:北京航空航天大學出版社,2002.
[2] CSCHWIND M. FPGA prototyping of a RISC processor core for embedded applications. IEEE Transactions on
Very Large Scale Integration(VLSI)Systems,2001,9(2).
[3] Hardware Reference Manual Version 3.1. www.altera.com. 2002-11.