
摘 要: 利用聚類的基本知識,根據(jù)不同顧客購買商品的相似性的大小,提出了運用K-means聚類算法。利用相似度代替歐氏距離,對該網(wǎng)絡(luò)進行聚類分析,劃分出相似性大的顧客群體,并根據(jù)每個群體中顧客購買每類商品占總商品數(shù)的比例進行排序,從而為商品陳列提供依據(jù)。
關(guān)鍵詞: 聚類;K-means聚類算法;相似性;商品陳列
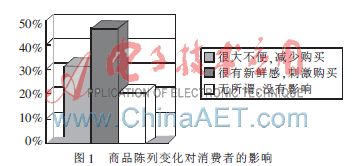
隨著經(jīng)濟的發(fā)展,商品的種類越來越多,作為顧客自由購物場所的商店,可利用有限的營業(yè)空間,在顧客瀏覽商品時,刺激顧客的購買欲望,達到擴大銷售的目的。商品的陳列在銷售過程中扮演者重要的角色,是商品沉默的推銷員[1]。因此如何合理地對商品進行陳列[2],成為商店推銷過程的一個必須要考慮的問題。由于不同顧客購買的商品之間具有一定的相似性,可以根據(jù)不同商品間的相似性,構(gòu)造具有關(guān)聯(lián)性的商品網(wǎng)絡(luò)[3]形成聚類,并根據(jù)不同顧客購買商品的相似性的大小,運用K-means聚類算法,利用相似度代替歐氏距離,對該商品網(wǎng)絡(luò)進行聚類分析[4],劃分出相關(guān)性大的顧客群體,并根據(jù)每個群體中顧客購買每類商品的均值占總商品數(shù)得比例進行排序[5],從而得到商品陳列的依據(jù),這樣顧客在瀏覽商品時,便會刺激其購買欲望,進而達到擴大銷售的目的。如圖1所示。
1 聚類分析的理論基礎(chǔ)
1.1 聚類簡介
聚類[6](Clustering)是數(shù)據(jù)挖掘中一種重要的挖掘方法,它是將物理或抽象對象進行分組并將相似的對象歸為一類的過程。聚類分析將物理或抽象對象分為幾個群體,在每個群體內(nèi)部,對象之間具有較高的相似性,而在群體之間相似性則比較低。聚類算法大體可以劃分為:劃分方法、層次方法、基于密度的方法、基于網(wǎng)格的方法和基于模型的方法[7]。
1.2 K-means聚類算法簡介
K-means算法[8]屬于聚類方法中的一種劃分方法,該算法具有較好的可伸性和很高的效率,適合處理大文檔集。K-means算法將一組物理的或抽象的對象,根據(jù)它們之間的相似程度分為若干組,其中相似的對象構(gòu)成一組。它采用歐式距離作為相似性的評價指標,即認為兩個樣本的距離越近,其相似度越大。其以最大歐式距離原則選取新的聚類中心,以最小歐式距離原則進行模式歸類。


4.2 商品的陳列算法
依據(jù)上面算法分成的k個顧客群體,在每類群體中,計算每種商品占商品總數(shù)的比例,依據(jù)比例的大小,由近到遠對商品進行排列,從而得到商品的排列次序。
本文根據(jù)顧客的購買記錄,根據(jù)其購買的商品間的相似性,劃分出相似性大的顧客群體,再根據(jù)每個群體中的每種商品占商品總數(shù)的比例大小進行排序,從而得到商品排序的理論依據(jù),進而使商品得到合理排序,這樣顧客在瀏覽商品時,便會刺激其購買欲望,達到擴大銷售的目的。但是每種商品,由于其品牌不同,知名度、信譽度等也不同,并且商品陳列時還要考慮場地位置,顏色搭配等,從而為商品陳列帶來新的問題,因此在為其提供基礎(chǔ)的同時為下一步工作指明了方向。
參考文獻
[1] 傅強.超市商品陳列對消費心理的影響[J].中國商貿(mào),2010(3).
[2] 朱海紅,江庭友,司丹丹,基于數(shù)據(jù)挖掘技術(shù)的商品陳列研究[J].商場現(xiàn)代化,2010(12).
[3] 王金龍,徐從富,徐嬌芬,等.利用銷售數(shù)據(jù)的商品影響關(guān)系挖掘研究[J].電子科技大學學報,2007(2).
[4] 崔春生,吳祈宗,王瑩,用于推薦系統(tǒng)聚類分析的用戶興趣度研究[J].計算機工程與應(yīng)用,2011(7).
[5] 劉金嶺.數(shù)據(jù)挖掘技術(shù)在商品銷售預測方面的應(yīng)用[J].商場現(xiàn)代化,2008(2).
[6] BERRY M, LINOFF G. Data mining techniques for marketing, sales, and customer relationship management[M]. 2nd ed. [S.l.]: John Wiley & Sons, Inc, 2004.
[7] 黃韜,劉勝輝,譚艷娜.基于k-means聚類算法的研究[J].計算機技術(shù)與發(fā)展,2011(7).
[8] 安建成,德增.一種改進的K-means算法[J].電腦開發(fā)與應(yīng)用,2011(4).
[9] 韓瑞凱,孟嗣儀,劉云,等.基于興趣相似度的社區(qū)結(jié)構(gòu)發(fā)現(xiàn)算法研究[J].計算機應(yīng)用,2010(10).
[10] Han Jiawei, KAMBER M.數(shù)據(jù)挖掘概念與技術(shù)[M].北京:機械工業(yè)出版社,2001.
[11] 王德榮,李衛(wèi)華.網(wǎng)絡(luò)號百用戶興趣模型挖掘算法[J].現(xiàn)代計算機,2010(4).
[12] 趙鳳霞、福鼎,基于K-means聚類算法的復雜網(wǎng)絡(luò)社團發(fā)現(xiàn)新算法[J].計算機應(yīng)用研究,2009(6).
[13] 樊寧.K均值聚類算法在銀行客戶細分中的研究[J],.計算機仿真,2011(3).