
摘 要: 研究了一種基于多粒度鎖的并發(fā)控制算法,包括其多粒度鎖鎖、鎖表數(shù)據(jù)結(jié)構(gòu)及鎖操作的算法步驟。算法可以降低沖突發(fā)生的概率和事務(wù)的夭折數(shù),減少事務(wù)重啟,有利于滿足事務(wù)截止期的要求,提高事務(wù)的并發(fā)度。在驗證算法有效性時,通過測試類對內(nèi)存數(shù)據(jù)庫記錄的插入速度、索引查找的速度、記錄的刪除速度三方面的性能進行了測試,結(jié)果表明,事務(wù)并發(fā)控制優(yōu)化算法對內(nèi)存數(shù)據(jù)庫性能的提升是有效可行的。
關(guān)鍵詞: 內(nèi)存數(shù)據(jù)庫;實時事務(wù);算法;并發(fā)控制;粒度
實時事務(wù)處理的算法主要有兩個方面,一方面是實事事務(wù)調(diào)度算法,主要是事務(wù)優(yōu)先級的確定;另一方面是實時事務(wù)的事務(wù)并發(fā)控制算法,包括悲觀事務(wù)并發(fā)控制算法和樂觀事務(wù)并發(fā)控制算法兩種[1]。近年來,在事務(wù)的并發(fā)控制方面已取得了大量理論研究成果。迄今為止,許多基于鎖、樂觀、時間戳的實時數(shù)據(jù)庫并發(fā)控制方法已提出,如優(yōu)先級繼承PI(Priority Inheriting)、高優(yōu)先級夭折HPA(High Priority Abort)、優(yōu)先級頂PC(Priority Ceiling)等,但很少見有關(guān)實時內(nèi)存數(shù)據(jù)庫并發(fā)控制實現(xiàn)技術(shù)的相關(guān)論述[2]。實時事務(wù)的并發(fā)控制實現(xiàn)涉及到實時數(shù)據(jù)庫的底層技術(shù),而一般的研究和討論只是基于一定的實驗?zāi)P瓦M行理論研究和分析。而且,對于不同的實現(xiàn)環(huán)境和所選擇的實現(xiàn)策略,實時事務(wù)所采用的并發(fā)控制技術(shù)也不盡相同。本文在研究已有的事務(wù)并發(fā)控制算法的基礎(chǔ)上,對悲觀事務(wù)并發(fā)控制算法2PL進行了改進。
在對算法性能測試時,根據(jù)給出的實時內(nèi)存數(shù)據(jù)庫的引擎結(jié)構(gòu),開發(fā)出一個實時內(nèi)存數(shù)據(jù)庫,以測試類對內(nèi)存數(shù)據(jù)庫三個方面的性能進行了測試。測試分為兩次,分別為事務(wù)并發(fā)控制算法優(yōu)化前和事務(wù)并發(fā)控制算法優(yōu)化后。
1 實時事務(wù)的并發(fā)控制算法
內(nèi)存數(shù)據(jù)庫的一個重要設(shè)計問題是并發(fā)控制,它由于既要滿足事務(wù)的時間限制還要維護數(shù)據(jù)庫的一致性而變得復(fù)雜[3]。傳統(tǒng)數(shù)據(jù)庫系統(tǒng)的并發(fā)控制協(xié)議不適合內(nèi)存數(shù)據(jù)庫系統(tǒng),實時事務(wù)是緊急的并且事務(wù)調(diào)度必須滿足截止期[4]。
定義1:一個調(diào)度S定義在一個事務(wù)集合T={T1,T2,...,Tn}的基礎(chǔ)上,它是多個事務(wù)執(zhí)行的操作系列。
定義2:一個調(diào)度S中,各個事務(wù)的操作執(zhí)行時不疊加(即一個接著一個發(fā)生),則這個調(diào)度是串行的。
定義3:一個調(diào)度S是可串行的,當且僅當S沖突等價于一個串行調(diào)度。這種可串行化通常稱為沖突等價可串行化。
一個并發(fā)控制器(或稱調(diào)度器)的基本功能是產(chǎn)生一個要執(zhí)行事務(wù)的可串行化調(diào)度。多數(shù)內(nèi)存數(shù)據(jù)庫系統(tǒng)的并發(fā)控制協(xié)議均基于串行化理論[5]。并發(fā)控制協(xié)議用于控制數(shù)據(jù)的調(diào)度,主要目標是維持數(shù)據(jù)的一致性并提供最大化的并發(fā)度[1]。在有些情況下,一致性要求可適當放寬。內(nèi)存數(shù)據(jù)庫是駐留在內(nèi)存中的共享數(shù)據(jù),在不同線程中同時運行的事務(wù)之間可能由于訪問內(nèi)存數(shù)據(jù)庫中的同一個數(shù)據(jù)對象而發(fā)生沖突,并發(fā)控制協(xié)議就是用來解決事務(wù)之間沖突的策略[6]。常見的沖突模式有“讀-寫”沖突和“寫-寫”沖突[7]。
“讀-寫”沖突:對同一個數(shù)據(jù)對象,一個事務(wù)正在執(zhí)行“讀”操作,同時另一個事務(wù)執(zhí)行“寫”操作而發(fā)生沖突;
“寫-寫”沖突:對同一個數(shù)據(jù)對象,一個事務(wù)正在執(zhí)行“寫”操作,同時另一個事務(wù)也執(zhí)行“寫”操作而發(fā)生沖突。
內(nèi)存數(shù)據(jù)庫中的并發(fā)控制協(xié)議解決沖突的辦法主要有兩種策略:
(1)等待:終止其中一個事務(wù)引起沖突的操作,使其停留在等待狀態(tài),直到另一個事務(wù)的操作完成為止。在內(nèi)存數(shù)據(jù)庫事務(wù)并發(fā)控制的研究中,等待策略有以下三種派生方法:①不等待(no wait):等待的事務(wù)立即夭折,而不是等到另一個事務(wù)操作完為止。②損傷等待(wound wait):根據(jù)每個事務(wù)的達到時間,如果要求得到數(shù)據(jù)者到達得比較早,則夭折正在使用數(shù)據(jù)的事務(wù);否則夭折要求得到數(shù)據(jù)的事務(wù)。③等待死亡(wait die):根據(jù)每個事務(wù)的到達時間,如果要求得到數(shù)據(jù)者到達得比較早,則該事務(wù)可以繼續(xù)等待,否則夭折這個事務(wù)。
(2)回滾:撤消事務(wù)引起沖突的操作,事務(wù)重啟,回到開始時的狀態(tài)[1]。
根據(jù)解決“讀寫”操作沖突的不同策略,并發(fā)控制算法分為悲觀并發(fā)控制協(xié)議PCC(Pessimistic Concurrency Control)和樂觀并發(fā)控制協(xié)議OCC(Optimistic Concurrency Control)兩大類[6]。分類如圖1所示。

悲觀并發(fā)控制算法中最廣泛使用的是基于鎖(Lock)協(xié)議的算法,它為數(shù)據(jù)訪問提供數(shù)據(jù)鎖,分為讀鎖和寫鎖,讀鎖又稱共享鎖(Shared Lock),被加讀鎖的數(shù)據(jù)對象只能讀不能寫;寫鎖又稱排它鎖(Exclusive lock),被加鎖的數(shù)據(jù)對象只能被加鎖事務(wù)讀寫,其他事務(wù)不能訪問[7]。事務(wù)要獲得對數(shù)據(jù)的訪問,首先要申請得到鎖,操作完成后釋放鎖。一般操作系列為:(1)申請鎖(Lock request);(2)授予鎖(Lock granted);(3)數(shù)據(jù)庫操作(Database operation);(4)結(jié)束操作(End of database operation);(5)釋放鎖(Release locks)。
兩階段鎖2PL(two phase lock)是悲觀并發(fā)控制協(xié)議算法的重要內(nèi)容,為解決優(yōu)先級倒置,派生出了高優(yōu)先級法2PL-HP(也叫優(yōu)先級夭折)、優(yōu)先級繼承、有條件優(yōu)先級繼承、數(shù)據(jù)優(yōu)先級法PCP及其他衍生協(xié)議。
樂觀并發(fā)控制協(xié)議認為任何兩個并發(fā)事務(wù)請求同一個數(shù)據(jù)對象的概率很低,事務(wù)對數(shù)據(jù)庫的所有操作在請求時即可進行。樂觀并發(fā)控制協(xié)議的事務(wù)處理過程分為:讀、驗證、提交,驗證分為前向驗證和后向驗證,若在驗證階段發(fā)現(xiàn)沖突,則進行事務(wù)回滾。如果事務(wù)頻繁的重啟對于內(nèi)存數(shù)據(jù)庫系統(tǒng)來說會是一個負擔并且不利于事務(wù)在截止期前完成,因此樂觀并發(fā)控制協(xié)議算法大多是圍繞如何減少事務(wù)重啟而進行改進,派生出了廣播算法OCC-BC、WAIT-50、OCC-TI、OCC-DA、多版本協(xié)議MCC等。
悲觀并發(fā)控制協(xié)議算法具有節(jié)約系統(tǒng)資源的特點,在處理時間限制比較嚴格的硬實時事務(wù)時表現(xiàn)優(yōu)于樂觀并發(fā)控制協(xié)議,而樂觀并發(fā)控制協(xié)議有利于提高系統(tǒng)的并發(fā)度[8]。研究表明,2PL-HP更適合于分布式內(nèi)存數(shù)據(jù)庫系統(tǒng)。根據(jù)流程工業(yè)大型內(nèi)存數(shù)據(jù)庫系統(tǒng)的特點,借鑒分布式兩階段鎖協(xié)議2PL的思想,本文提出并設(shè)計了多粒度鎖的并發(fā)控制算法,其特點是減少沖突事務(wù)之間的等待時間。
2 兩階段鎖2PL
數(shù)據(jù)鎖分為讀鎖(也稱共享鎖)和寫鎖(也稱獨占鎖):(1)共享鎖Shared lock:只允許讀,簡稱“S鎖”;(2)獨占鎖Exclusive lock:允許讀和修改鎖住的數(shù)據(jù)對象,簡稱“X鎖”。一般使用鎖的方式是用完即釋放,如以下代碼所示:
LOCK S(A); //對數(shù)據(jù)對象A加共享鎖
read(A); //讀數(shù)據(jù)對象A
UNLOCK(A);//釋放鎖
LOCK S(B); //對數(shù)據(jù)對象B加共享鎖
read(B); //讀數(shù)據(jù)對象B
UNLOCK(B); //釋放鎖
display(A+B); //顯示結(jié)果
這種使用鎖的方式可能會導(dǎo)致不可串行化,而可串行化(serializability)是并發(fā)控制最普遍的正確性準則,各個事務(wù)對數(shù)據(jù)對象的操作不交叉存取(即每個事務(wù)對數(shù)據(jù)對象的操作是連續(xù)的)[9]。因為在這種方式中,當事務(wù)T1釋放鎖時,事務(wù)T2獲得了數(shù)據(jù)對象A的獨占鎖LOCK X(A)而執(zhí)行write(A)的操作,就會導(dǎo)致事務(wù)T1的執(zhí)行結(jié)果不正確。采用兩階段鎖來解決此問題,所謂兩階段指的是封鎖階段和解鎖階段。封鎖階段也稱為生長階段(Growing phase),事務(wù)獲得鎖并存取數(shù)據(jù);解鎖階段也叫枯萎階段(Shrinking phase),事務(wù)的鎖不斷減少。
兩階段鎖算法的規(guī)則是:(1)如果事務(wù)T想讀(修改)一個對象,它首先要獲得一個共享(獨占)鎖;(2)對事務(wù)已經(jīng)持有的封鎖,不得重復(fù)申請;(3)一個事務(wù)必須注意到其他事務(wù)所做的封鎖;(4)每個事務(wù)分做兩段:生長期和枯萎期。生長期申請封鎖,枯萎期解除封鎖,在枯萎期不得申請新封鎖;(5)調(diào)度器在數(shù)據(jù)管理器完成對數(shù)據(jù)對象橢操作后才能釋放鎖;(6)事務(wù)結(jié)束時,解除所有封鎖。
兩階段鎖算法規(guī)則保證了事務(wù)執(zhí)行的可串行化,鎖管理器LM (Lock Manager)在存取結(jié)束時即刻釋放鎖,提高了事務(wù)的并發(fā)度。但它存在的問題是可能導(dǎo)致級聯(lián)退出,所以需要使用嚴格2PL(strict two-phase locking,簡稱S2PL), S2PL在數(shù)據(jù)存取完成的最后階段釋放所有鎖。
3 基于多粒度鎖的并發(fā)控制
內(nèi)存數(shù)據(jù)庫中,兩階段鎖封鎖對象的大小稱為封鎖的粒度,一般情況下,加鎖的粒度越大,加鎖的次數(shù)就越少,系統(tǒng)資源的開銷小,事務(wù)之間沖突發(fā)生的概率就越高,系統(tǒng)的并發(fā)度越低;多粒度鎖封鎖就是在一個系統(tǒng)中同時支持多種封鎖粒度供不同的事務(wù)進行選擇。采取多粒度鎖封鎖策略,可以降低沖突發(fā)生的概率和事務(wù)的夭折數(shù),減少事務(wù)重啟,有利于滿足事務(wù)截止期的要求,提高事務(wù)的并發(fā)度。
3.1 多粒度鎖并發(fā)控制鎖
參考關(guān)系數(shù)據(jù)庫的概念,內(nèi)存數(shù)據(jù)庫中鎖的粒度可定義為:數(shù)據(jù)庫DataBase (如果多于一個庫,數(shù)據(jù)庫也可以作為粒度的元素)、表Table、頁Page、記錄Record、元組Tuple。從前到后是一種順序包含的關(guān)系,展開以后其層次結(jié)構(gòu)形成了一棵樹。多粒度鎖封鎖允許對樹上的每一個數(shù)據(jù)項進行封鎖。由于節(jié)點的這種包含關(guān)系,除S鎖和X鎖外,多粒度鎖鎖時需要引入以下的意向鎖:
(1)IS(Intent Share Lock):意向共享鎖。如果對一個數(shù)據(jù)對象加IS鎖,表示它的子結(jié)點擬加S鎖。
(2)IX(Intent Exclusive Lock):意向排它鎖。如果對一個數(shù)據(jù)對象加IX鎖,表示它的子結(jié)點擬加X鎖。
(3)SIX(Share Intent Exclusive Lock):共享意向排它鎖。如果對一個數(shù)據(jù)對象加SIX鎖,表示對它加S鎖,再加IX鎖,即SIX=S+IX。例如,對某個表加SIX鎖,則表示該事務(wù)要讀整個表(對該表加S鎖),同時會更新個別元組(對該表加IX鎖)。
多粒度鎖鎖協(xié)議準則:
(1)從層次結(jié)構(gòu)的根節(jié)點開始封鎖;
(2)子節(jié)點要獲得S或IS鎖,它的父節(jié)點必須持有IS或IX鎖;
(3)子節(jié)點要獲得X或IX或SIX鎖,它的父節(jié)點必須持有IX或SIX鎖;
(4)必須從由底向上的順序釋放鎖。
3.2 粒度并發(fā)控制算法步驟
本文提出的多粒度鎖的并發(fā)控制協(xié)議中,采用S2PL-HP算法解決沖突。如果低優(yōu)先級事務(wù)試圖申請高優(yōu)先級事務(wù)持有的鎖,則阻塞優(yōu)先級低的事務(wù);如果優(yōu)先級高的事務(wù)到達時申請低優(yōu)先級事務(wù)持有的鎖,則將低優(yōu)先級事務(wù)回滾。
兩階段鎖算法需要構(gòu)造鎖管理器LM,鎖管理器管理的鎖存放在散列表(Hash Table)一類的數(shù)據(jù)結(jié)構(gòu)中,數(shù)據(jù)結(jié)構(gòu)中的元素可定義如下:
typedef lock_type{
DATAID data_id: //被鎖定的數(shù)據(jù)對象ID
vector trans_id; //持有鎖的事務(wù)ID向量
int lt://鎖類型:S、X、1S、IX,SIX
int lg;//鎖粒度:db,table,page,record,Tuple
}lock_item
定義4:RTDB={DT1,DT2,…,DTn},其中, DTi為數(shù)據(jù)庫中第i個的數(shù)據(jù)表,DTi={DR1,DR2,…,DRn}:DRj為數(shù)據(jù)表中第j條記錄,DRj={DF1,DF2,…,DFn};DFk為記錄中的第k個元組。
定義5:數(shù)據(jù)的全局標識為GID=f(DB,DTi,DRj,DFk);conflict(Ti,Tj)為事務(wù)Ti和Tj的沖突;lock(Ti,Di)表示事務(wù)Ti對數(shù)據(jù)對象Di加鎖。
LM:Lock Manager,即鎖表管理器;DM:Data Manager,即數(shù)據(jù)管理器。當事務(wù)Ti到達時,多粒度鎖并發(fā)控制算法步驟為:
(1)進行事務(wù)預(yù)分析,根據(jù)一定的算法規(guī)則計算Ti所操作的數(shù)據(jù)對象的數(shù)據(jù)標識;并填寫lock_item中的其他項;將鎖粒度lg初始化設(shè)置為table。
(2)查看鎖表管理器,找到事務(wù)Tj的數(shù)據(jù)對象ID:
①Ti和Tj不沖突,則鎖表管理器將Ti的信息加入鎖表中,lock(Ti,Di),轉(zhuǎn)到第(3)步;
②如果Ti和Tj發(fā)生沖突,若它們的鎖類型相容,則鎖表管理器將Ti的trans_id加入向量中,轉(zhuǎn)到第(3)步;
③如果鎖粒度是元組,即最小加鎖粒度,則跳到第(5)步,否則調(diào)整Ti和Tj的加鎖粒度,并返回第(2)步;
(3)處理事務(wù),調(diào)用數(shù)據(jù)管理器進行數(shù)據(jù)讀寫操作;
(4)數(shù)據(jù)管理器處理完畢,鎖表管理器更新對應(yīng)鎖表中的信息,跳到第(6)步;
(5)如果有沖突發(fā)生,調(diào)用S2PL—HP算法規(guī)則解決沖突;
(6)結(jié)束。
4 算法測試
4.1 內(nèi)存數(shù)據(jù)庫引擎結(jié)構(gòu)設(shè)計
內(nèi)存數(shù)據(jù)庫 Engine是內(nèi)存數(shù)據(jù)庫的核心,它對實時/歷史數(shù)據(jù)進行管理,它的本質(zhì)是一個實時事務(wù)處理器。
關(guān)系型數(shù)據(jù)庫采用二維關(guān)系表來進行數(shù)據(jù)的存儲,基于磁盤的存儲結(jié)構(gòu),數(shù)據(jù)存取過程中要進行頻繁的磁盤I/O操作。由于磁盤I/O操作時間不確定性,要引入內(nèi)存數(shù)據(jù)庫中是不現(xiàn)實的。內(nèi)存數(shù)據(jù)庫將實時數(shù)據(jù)常駐內(nèi)存,訪問實時數(shù)據(jù)時無需進行I/O操作,保證了運行速度,有利于滿足實時事務(wù)截止期的要求。
4.2 事務(wù)并發(fā)控制優(yōu)化算法測試結(jié)果
測試系統(tǒng)環(huán)境為:Win7+JDK+NetBeans6.7。
事務(wù)并發(fā)控制算法優(yōu)化前測試結(jié)果如圖2所示。

事務(wù)并發(fā)控制算法優(yōu)化后測試結(jié)果如圖3所示。
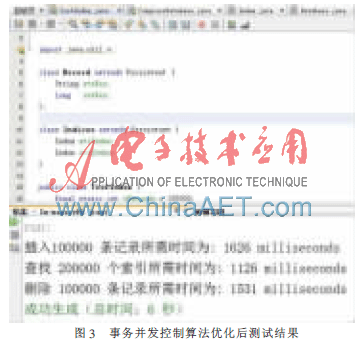
與傳統(tǒng)數(shù)據(jù)庫不同,內(nèi)存數(shù)據(jù)庫系統(tǒng)事務(wù)的并發(fā)擦控制除需保證共享數(shù)據(jù)的一致性外,還要考慮事務(wù)的定時限制。因此,其并發(fā)控制機制比傳統(tǒng)數(shù)據(jù)庫要復(fù)雜。本文給出了一個基于多粒度鎖的并發(fā)控制機制,通過驗證,該方法成功且有效地解決了內(nèi)存數(shù)據(jù)庫的事務(wù)并發(fā)問題。從內(nèi)存數(shù)據(jù)庫的測試結(jié)果可知,算法優(yōu)化后系統(tǒng)的各項性能都有所提升,證明了算法優(yōu)化的可行性和必要性。
參考文獻
[1] 納永良.大型實時數(shù)據(jù)庫關(guān)鍵技術(shù)及應(yīng)用研究[D].北京:北京化工大學(xué),2010.
[2] 祁鑫,王文海.內(nèi)存數(shù)據(jù)庫系統(tǒng)并發(fā)控制機制綜述[J].計算機技術(shù),2006.33(1):47-50.
[3] 陳小艷.嵌入式主動內(nèi)存數(shù)據(jù)庫ARTs.EDB的并發(fā)控制[D].武漢:華中科技人學(xué),2009.
[4] 桑楠.嵌入式應(yīng)用原理及應(yīng)用開發(fā)技術(shù)[M].北京:北京航空航天大學(xué)出版社,2003.
[5] 夏家莉.嵌入式數(shù)據(jù)庫系統(tǒng)中無沖突并發(fā)控制協(xié)議CCCP[J].計算機研究與發(fā)展,2004,41(11):1936-1941.
[6] 廖國瓊,劉云生,等.嵌入式內(nèi)存數(shù)據(jù)庫事務(wù)的并發(fā)控制[J].計算機工程,2005(9).
[7] 趙文潔.基于OPC技術(shù)的實時數(shù)據(jù)庫的研究與設(shè)計[D].太原:太原理工大學(xué),2007.
[8] 廖國瓊,劉云生,等.嵌入式實時數(shù)據(jù)庫事務(wù)的并發(fā)控制[J].計算機工程,2005,32(5):12-18.
[9] LAM K W, LAM K Y, HUNG S L.Optimistic concurrency controlprotocol for real-time databases[J]. SYSTEMS SOFTWARE, 2007,11:34-39.