
摘 要:考慮到人臉表情識別問題在未來的科學應用中可能出現(xiàn)的樣本分布不均勻的情況,在提高識別率的基礎上,針對這類問題進行了實驗研究,將一種改進的AdaBoost算法與SVM結合運用到表情分類當中。實驗結果表明,在出現(xiàn)稀有樣本的情況下,相對于普通的AdaBoost訓練SVM以及單純的SVM進行多分類的方法,該算法在識別率方面有了很大提高。
關鍵詞: 人臉表情識別;預處理;Gabor變換;IAdaBoost
對人類面部的表情本質信息進行特征的提取分析,并利用人類的認知和思維方式對其歸類及理解,參考人們在情感方面所具有的先驗知識讓計算機思考和推理,從而據(jù)此從人們的面部表情中分析并理解他們的情緒,這就是人類面部表情識別所要做的工作[1]。
本文采用一種改進的AdaBoost算法[2]與支持向量機[3]組合的分類方法,使其能夠處理多分類的表情問題,采用該方法的最大優(yōu)點是能夠在實驗的訓練過程中考慮分布稀疏樣本的重要性,使得稀有類別中的樣本也能具有較高權值,并且采用了規(guī)則抽樣的方法,使得其可以較大概率地被選中,這樣在之后的迭代過程中更容易被抽到,從而可以有效避免分類器忽視稀有類這一現(xiàn)象的發(fā)生,使稀有類樣本正確劃分更有利。
之所以采用這種分類,是因為所研究的表情分類問題,其最終目的還是要應用到實際生活當中,六類表情在人們的生活當中出現(xiàn)的概率肯定是不盡相同的,像厭惡、悲傷的表情還是要比高興少,當出現(xiàn)樣本分布不均勻的分類情況下,本文研究的算法就可能體現(xiàn)出價值。
1 系統(tǒng)概要
通常來說,把一個完善的人臉表情識別過程分成人臉的檢測過程、人臉本質特征的提取過程以及表情的分類過程3個小環(huán)節(jié)。因此,如果建立一個正常的表情識別系統(tǒng),第一步需要對人們的面部進行檢測和定位[4],其后通常還有一個預處理[5]的過程,進行預處理的主要目的是盡量除去圖像因采集因素差異而造成的不同,確保了圖像能有一個同等的實驗環(huán)境,這樣再進行表情識別的研究,就可以有效地提高識別的效率。第二步把靜態(tài)圖像或動態(tài)的視頻序列中能表征人臉表情本質的信息提取出來,其后通常有一個二次特征降維[6]的過程,來進一步降低提取特征的維數(shù)。第三步進行特征分類[7],即將輸入到系統(tǒng)的人臉表情正確地分類到相應的類中。系統(tǒng)核心框架如圖1所示。

1.1 人臉檢測
目前,已有很多的人臉檢測算法,本文采用由Paul Viola等人提出的基于Haar小波基函數(shù)的的矩形特征與級聯(lián)的Boosted機器學習相結合的對象探測算法進行人臉檢測。首先利用樣本(大約幾百幅樣本圖片)的Haar特征進行分類器的訓練,得到一個級聯(lián)Boosted分類器,分類器訓練完以后,就可以應用于輸入圖像中的感興趣區(qū)域的檢測。為了檢測整幅圖像,可以在圖像中移動搜索窗口,檢測每一個位置來確定可能的目標。為了搜索不同大小的目標物體,分類器被設計為可以進行尺寸改變,這樣,為了在圖像中檢測未知大小的目標物體,掃描程序通常需要用不同比例大小的搜索窗口對圖像進行多次掃描。
Intel開源OpenCV計算機視覺庫已經(jīng)有效地實現(xiàn)了該算法。本文利用OpenCV庫函數(shù)進行人臉檢測,從輸入圖像中獲取人臉的位置和尺寸信息。為了有效地檢測到人臉位置,又不致于使檢測掃描的次數(shù)過多影響系統(tǒng)運行時間,本文在日本ATR女性表情數(shù)據(jù)庫(JAFFE)[8]和CMU的Cohn-KanadeAU表情數(shù)據(jù)庫[9]上進行了人臉檢測的實驗。首先對圖像庫待檢測的圖像進行了分析計算,以獲取圖像類Haar特征[10],再利用訓練好的AdaBoost算法來處理這些得到的類Haar特征,以檢測待測圖像,最終顯示出了人臉的具體位置。在日本ATR女性表情數(shù)據(jù)庫(JAFFE)上所做實驗的部分檢測結果如圖2所示。

1.2 圖像預處理
因為采集設施的差異、光照因素的不同以及環(huán)境背景的變換等因素會影響到所輸入到系統(tǒng)的圖像,因此,在進行表情特征提取前,檢測獲取的人臉區(qū)域還需要進行另外的一些處理,這就是通常所講的預處理操作。
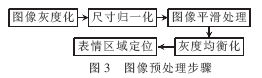
圖像的預處理步驟通常包括了尺寸的歸一化、噪聲的去除以及灰度的均衡化等,正如前文所說,這樣做的目的是盡量消除圖像采集因素間的差異,以確保圖像能有一個同等的實驗環(huán)境,這樣再進行表情識別的研究,就可以有效地提高識別的效率。
本文采用的圖像預處理大致步驟如圖3所示。
2 特征提取和降維
2.1 Gabor特征提取
由Gabor函數(shù)經(jīng)過尺度的伸縮及旋轉而生成的一組復函數(shù)系,稱為Gabor小波[11],其具有的多分辨率特性以及良好的時頻局部化特征,使得它可以提取到待測圖像局部細微的變化,因此,它很適合于人臉表情特征提取。此外,其對于光照的變化不敏感,具有較好的光照性。
被用作提取特征和表征圖像的方法,Gabor濾波器在圖像分析、圖像識別等領域得到了很大程度的應用,這里關于它的原理就不再贅述,主要說下本文的思路和實現(xiàn)。
假如對整個待測的圖片直接做Gabor變換[12],經(jīng)過實驗得到的維數(shù)是非常大的,因此為了便于后續(xù)的表情分類,可以設想,由于人們的每一種表情其實主要是在眉毛、眼和嘴部等這些個最能代表面部表情特征的區(qū)域進行了較為集中的展現(xiàn),因此就可以對第一步人臉檢測過程中,通過圖像的預處理已經(jīng)定位出的表情區(qū)域進行有目的的選擇,即選擇最能代表人臉表情本質信息的區(qū)域,并對這些個區(qū)域進行一些網(wǎng)格化的處理。這樣不但可以使特征向量的維數(shù)有效地減少,還保留了原始表情本質信息的有效性。經(jīng)過試驗比對,最終選取了Gabor的核函數(shù)窗口為61×61,變換頻率總數(shù)為3,變換方向總數(shù)為7的情況來獲得最佳的識別率。而對于表情區(qū)域的網(wǎng)格化,則選取了眼部區(qū)域尺寸為35×42,嘴部區(qū)域尺寸為28×63,表情的子網(wǎng)格顆粒尺寸為7×7的情況來獲取最佳的識別率。Gabor濾波器提取表情特征的大致步驟如圖4所示。

2.2 AdaBoost二次降維
雖然區(qū)域化選擇表情特征使得提取到的特征圖像維數(shù)有了一定程度的降低,但是對于識別分類的要求而言,其維數(shù)還是比較高的,因此,本文又選取了AdaBoost的修改算法進行二次降維。在這個過程中,令每一個弱分類器僅僅對應于1個特征,并且由特征值大小來對分類進行判斷,這樣一來,Adaboost對于弱分類器的挑選過程也就成了對于特征的挑選過程。整個特征提取的過程如圖5所示。

3 基于改進的AdaBoost算法的表情分類
3.1 AdaBoost算法
AdaBoost算法是一種分類器算法。具體來說,AdaBoost學習算法的核心思想是從一個很大的特征集中選擇很小的一部分關鍵的視覺特征,從而產(chǎn)生一個及其有效的分類器。它利用大量的分類能力一般的簡單分類器通過一定的方法疊加(Boost)起來,構成一個分類能力很強的強分類器,再將若干個強分類器串聯(lián)成為分級分類器(Classifier Cascade)完成圖像搜索檢測。串聯(lián)的級數(shù)依賴于系統(tǒng)對錯誤率和識別速度的要求。這種用“Cascade”來不斷組合成更復雜的分類器的方法可以使圖像的背景區(qū)域能夠很快地被排除掉,而將更多的計算花費在更有希望成為目標的區(qū)域。對于每一種特征而言,弱學習器決定弱分類器的最佳的門限值,使其具有最小的誤分樣本數(shù)。全部的檢測過程的形式就是這樣的一個退化的決策樹。

3.2 IAdaBoost算法
本文采用把AdaBoost應用到SVM的多類分類方法,不同之處是對AdaBoost中隨機抽樣的方法做了改進,采用了規(guī)則的抽樣方法來提高分類器的泛化能力,把按照這樣的方法改進的AdaBoost算法叫做IAdaBoost算法[13]。
IAdaBoost是利用AdaBoost迭代的思想訓練支持向量機的基分類器。AdaBoost本身用的是抽樣處理,即把自助的樣本集從原始的數(shù)據(jù)集中提取出來,并自適應地進行多輪迭代,但該算法在建立稀有類的分類模型上有局限性,而IAdaBoost可以很好地解決此類問題。它使用了規(guī)則抽樣,并用樣本所在類的規(guī)模來標記樣本的初始權重,賦予了稀有類樣本比較高的權值,使得這些樣本能夠擁有較大的概率在規(guī)則抽樣中被選中,并且在迭代過程中較容易被抽到,從而使得分類器忽視稀有類的現(xiàn)象得以避免。可見,IAdaBoost算法在處理具有稀有類的分類問題上,相比AdaBoost算法有了改進。

4 實驗與分析
在日本ATR女性表情數(shù)據(jù)庫和CMU的Cohn-KanadeAU表情數(shù)據(jù)庫上針對除中性之外的六種表情,進行了兩組對照試驗,即在表情數(shù)據(jù)庫上做每類樣本大致相同時和某幾類樣本明顯減少時的對照試驗來檢測本文方法的可行性。本文將悲傷和厭惡兩類樣本作為了稀有樣本,將其樣本數(shù)量減少至一半,這也是主要考慮到在以后的社會應用中,此類樣本出現(xiàn)的概率肯定要比高興等其他表情要少,凸顯了本文的研究目的。在日本ATR女性表情數(shù)據(jù)庫上進行的不同算法多次實驗的平均識別水平如表1和2所示,在CMU的Cohn-KanadeAU表情數(shù)據(jù)庫上進行的不同算法多次實驗的平均識別水平如表3和4所示。
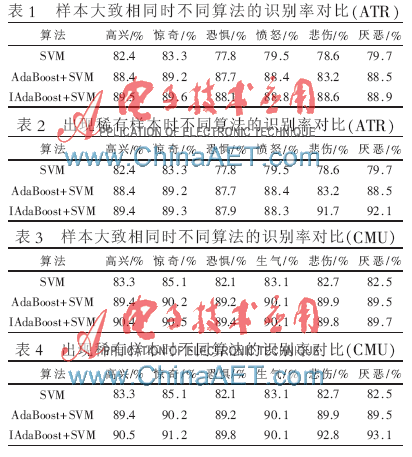
本文針對人臉表情識別問題在未來的科學應用中可能出現(xiàn)的樣本分布不均勻的情況,在提高識別率的基礎上,采用IAdaBoost訓練SVM的多分類方法很好地解決了這一問題,在實驗中使用規(guī)則抽樣,并用樣本所在類的規(guī)模來標記樣本的初始權重,賦予了稀有類樣本比較高的權值,使得這些樣本在規(guī)則抽樣中被選中的概率較大,并且在迭代過程中較容易被抽到,從而使得分類器忽視稀有類的現(xiàn)象得以避免,并達到了很好的效果。
參考文獻
[1] 王志良,陳鋒軍,薛為民.人臉表情識別方法綜述[J].計算機應用與軟件,2003,20(12):63-66.
[2] 武妍,項恩寧.動態(tài)權值預劃分實值Adaboost人臉檢測算法[J].計算機工程,2007,33(3):208-209.
[3] 應自爐,唐京海,李景文.支持向量鑒別分析及在人臉表情識別中的應用[J].電子學報,2008,36(4):725-730.
[4] 梁路宏,艾海舟.人臉檢測研究綜述[J].計算機學報,2002,25(5):449-458.
[5] 孔凡芝,張興周,謝耀菊.基于Adaboost的人臉檢測技術[J].應用科技,2005,32(6):7-9.
[6] 王志良,劉芳,王莉.基于計算機視覺的表情識別技術綜述[J].計算機工程,2006,32(11):231-233.
[7] 章品正,王征,趙宏玉.面部表情特征抽取的研究進展[J].計算機工程與應用,2006,38(9):38-42.
[8] LYONS M, BUDYNEK J, AKAMASTU S. Automatic classification of single facial images[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1999, 21 (12): 1357-1362.
[9] KANADE T, COHN J F, TIAN Y. Comprehensive database for facial expression analysis[C]. Proceedings of the Fourth International Conference of Face and Gesture Recognition, Grenoble, France, 2000: 46-53.
[10] LIENHART R, MAYDT J. An extended set of Haar-like features for rapid object detection[C]. IEEE ICIP 2002, 2002, 1: 900-903.
[11] 印勇,史金玉,劉丹平.基于Gabor小波的人臉表情識別[J].光電工程,2009,36(5):111-1169.
[12] 王化勇,李昕.基于改進的Gabor和ADABOOST的人臉表情識別[J].遼寧工業(yè)大學學報(自然科學版), 2010,30(1):17-19.
[13] 李亞軍,劉曉霞,陳平.改進的AdaBoost算法與SVM的組合分類器[J].計算機工程與應用,2008,44(32):140-142.