
文獻(xiàn)標(biāo)識(shí)碼: B
文章編號(hào): 0258-7998(2012)11-0041-03
在多傳感器測量系統(tǒng)中,為了精確測量,需要對(duì)傳感器輸出信號(hào)進(jìn)行高速、高分辨率采樣[1]。這樣勢必會(huì)產(chǎn)生大量需要存儲(chǔ)的數(shù)據(jù),占用很大的存儲(chǔ)空間,同時(shí)也不便于實(shí)時(shí)傳輸。但在一些嵌入式系統(tǒng)中,由于受到工藝、成本等各種因素的限制,存儲(chǔ)器空間非常有限,以至于經(jīng)常采取降低采樣率的辦法來達(dá)到節(jié)省存儲(chǔ)空間的目的。為此,在采樣率和分辨率均不能降低的情況下,為了保證測量精度,對(duì)傳感器信號(hào)進(jìn)行壓縮存儲(chǔ)、傳輸是十分必要的。
目前,有關(guān)傳感器數(shù)據(jù)壓縮傳輸?shù)难芯坑校?1)參考文獻(xiàn)[2]提出一種存儲(chǔ)有效的漸進(jìn)小波數(shù)據(jù)壓縮算法,使得漸進(jìn)傳送的數(shù)據(jù)單元能產(chǎn)生大的編碼增益,在存儲(chǔ)有效的同時(shí)又能夠節(jié)省網(wǎng)絡(luò)傳輸耗能;(2)參考文獻(xiàn)[3]提出了一種基于改進(jìn)的二叉樹算法對(duì)原始采樣數(shù)據(jù)進(jìn)行實(shí)時(shí)壓縮,對(duì)采樣數(shù)據(jù)在二維方向上進(jìn)行去冗余處理,從而達(dá)到節(jié)省數(shù)據(jù)存儲(chǔ)空間、提高數(shù)據(jù)傳輸效率的目的;(3)參考文獻(xiàn)[4]針對(duì)測井傳感器數(shù)據(jù)特征將其分為兩類,第一類采用差分編碼(預(yù)處理),再用Huffman編碼壓縮輸出,第二類采用基于統(tǒng)計(jì)的預(yù)測模型和分段線性預(yù)測模型(PLOT)進(jìn)行處理輸出。
但以上幾種方法都是有損壓縮,無法完全恢復(fù)出原始數(shù)據(jù),并且壓縮數(shù)據(jù)前后都有相關(guān)性,沒有提出一旦出現(xiàn)誤碼或丟包情況將如何正確解壓的問題。本文以無損壓縮方法中性能較優(yōu)的Zlib為基礎(chǔ),并采取改進(jìn)措施,在保證壓縮率和實(shí)時(shí)性的前提下,解決網(wǎng)絡(luò)傳輸中誤碼和丟包容錯(cuò)問題,同時(shí)對(duì)測井傳感器數(shù)據(jù)進(jìn)行了測試實(shí)驗(yàn)。
1 Zlib無損壓縮方法
無損壓縮就是利用數(shù)據(jù)的統(tǒng)計(jì)冗余進(jìn)行壓縮,并可完全回復(fù)原始數(shù)據(jù)而不引起任何失真。典型的無損壓縮算法如Shanno-Fano編碼、Huffman(哈夫曼)編碼、算術(shù)編碼、游程編碼、LZW編碼、LZ編碼以及應(yīng)用最廣也是最好的結(jié)合LZ和Huffman編碼的DEFLATE編碼,其主要應(yīng)用在RAR、LZMA、Zlib、Gzip、Bzip等壓縮算法中。
雖然LZMA具有好的壓縮率,但是消耗資源過大(最小資源消耗在1 MB左右)且壓縮速率很慢,不適合實(shí)際嵌入式應(yīng)用。所以本文選用Zlib壓縮算法,其中SYNC_FLUSH模式下的流程圖如1所示。

首先初始化程序,然后將待壓縮數(shù)據(jù)存到處理窗口中,用LZ算法對(duì)待壓縮數(shù)據(jù)進(jìn)行預(yù)處理。一方面通過Hash算法生成并不斷更新當(dāng)前塊的壓縮字典;另一方面通過查找字典將數(shù)據(jù)匹配情況存到緩沖區(qū)中并統(tǒng)計(jì)其頻率。這樣通過未匹配字節(jié)、匹配長度和匹配距離描述了原始數(shù)據(jù)的匹配關(guān)系。當(dāng)處理窗口數(shù)據(jù)被處理完之后,再利用動(dòng)態(tài)和靜態(tài)Huffman算法對(duì)其匹配情況進(jìn)行編碼,并比較選擇壓縮效果好的Huffman算法進(jìn)行壓縮編碼輸出。但是如果選擇的是動(dòng)態(tài)Huffman算法,還需要在壓縮數(shù)據(jù)之前用deflate_tree編碼壓縮動(dòng)態(tài)Huffman字典編碼并輸出。當(dāng)每個(gè)壓縮塊完成之后再加上Zlib容錯(cuò)方式,如果是最后一個(gè)壓縮塊,則還需要最后輸出校驗(yàn)信息,否則需要重新初始化壓縮下一個(gè)數(shù)據(jù)塊。
2 改進(jìn)的Zlib算法
2.1 基本思想
源Zlib壓縮算法中,SYNC_FLUSH模式雖然通過添加header信息和Zlib容錯(cuò)方式字段實(shí)現(xiàn)分包壓縮,同時(shí)每個(gè)壓縮塊都重新生成字典實(shí)現(xiàn)相互獨(dú)立,但是仍然不能解決容錯(cuò)問題,原因如下。
(1)如果壓縮數(shù)據(jù)在網(wǎng)絡(luò)傳輸過程中出現(xiàn)誤碼的情況,并且誤碼之后的數(shù)據(jù)又能夠通過當(dāng)前塊的壓縮字典解壓,但是解壓錯(cuò)誤,而最后輸出錯(cuò)誤的解壓結(jié)果不報(bào)錯(cuò);
(2)如果出現(xiàn)丟包的情況,則解壓過程中會(huì)報(bào)異常且直接終止跳出,導(dǎo)致后面正確的壓縮塊不能正常解壓。
針對(duì)以上兩個(gè)問題,本文提出改進(jìn)并實(shí)現(xiàn)獨(dú)立分包壓縮并且能夠獨(dú)立解壓的方法,以解決因網(wǎng)絡(luò)傳輸導(dǎo)致的誤碼和丟包的容錯(cuò)問題。此外,根據(jù)實(shí)際程序應(yīng)用修改滑動(dòng)窗口大小和內(nèi)存消耗等級(jí),大大減小了內(nèi)存資源消耗。
2.2 獨(dú)立分包壓縮的算法流程
每次讀4 KB樣本數(shù)據(jù),然后獨(dú)立壓縮成一個(gè)壓縮塊放到輸出緩沖區(qū),當(dāng)輸出緩沖區(qū)內(nèi)滿2 KB數(shù)據(jù)時(shí)就寫到輸出文件中。每次把4 B檢錯(cuò)信息adler寫到壓縮塊最后(Zlib容錯(cuò)方式0x0000ffff之前),便于解壓檢錯(cuò)實(shí)現(xiàn)容錯(cuò)機(jī)制。這樣就得到如圖2所示的壓縮數(shù)據(jù)格式。

獨(dú)立分包壓縮要求每次都要初始化字典并重新建立字典,這樣會(huì)導(dǎo)致壓縮率(壓縮率=壓縮后數(shù)據(jù)大小/壓縮前數(shù)據(jù)大小)提高(即壓縮效果變差)。但是測試表明,壓縮效果較壓縮效果最好的NO_FLUSH模式(其生成的壓縮包之間相互關(guān)聯(lián),如果出現(xiàn)誤碼或丟包情況,就會(huì)使出錯(cuò)后的壓縮塊不能解壓)并沒有下降很多,壓縮率只提高了2%;而與源程序的SYNC_FLUSH模式壓縮率幾乎相等,因?yàn)殡m然每個(gè)壓縮包都加了4 B的檢錯(cuò)信息,但是只有第一個(gè)壓縮塊加了2 B的header信息,而源程序中每個(gè)壓縮塊都要加header信息且最后一個(gè)加了檢錯(cuò)信息,最終生成的壓縮數(shù)據(jù)比源程序多(2×N-2)B,其中N表示壓縮塊的個(gè)數(shù)。由于都是獨(dú)立分包壓縮,解壓可以容錯(cuò),并且可以極大地減小其程序消耗的資源。因?yàn)檫@時(shí)并不需要分配大的滑動(dòng)字典窗口和字典空間,優(yōu)化之后總共動(dòng)態(tài)分配空間為96 KB左右,而NO_FLUSH模式下資源消耗在260 KB左右。
2.3 獨(dú)立解壓的算法流程
本文是模擬傳感器數(shù)據(jù)獨(dú)立分包壓縮再整體解壓,因?yàn)樵趯?shí)際工程中解壓程序是源源不斷地從輸入緩沖區(qū)中讀數(shù)據(jù)解壓。但是如果讀入的待解壓數(shù)據(jù)出現(xiàn)誤碼和丟包情況(而解壓程序并不知道),解壓程序必須實(shí)現(xiàn)獨(dú)立解壓功能,即丟棄出錯(cuò)的壓縮塊而又不影響后面的正確的壓縮塊解壓,這就要求每個(gè)壓縮包必須是獨(dú)立壓縮。采用在每個(gè)壓縮塊后面寫入檢錯(cuò)信息adler和Zlib容錯(cuò)方式就能很好地解決這個(gè)問題。具體解壓流程圖如圖3所示。
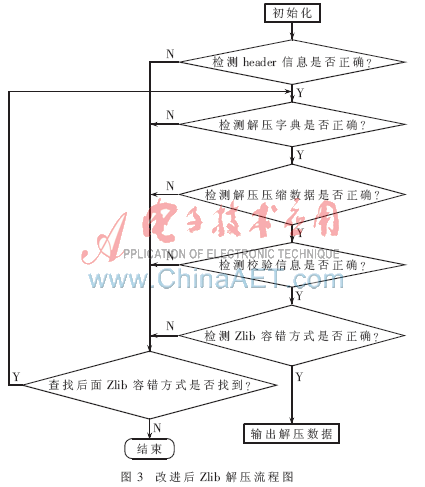
為了便于誤碼或丟包的測試,將壓縮數(shù)據(jù)存放在一個(gè)緩沖區(qū)中。這就要求預(yù)判壓縮數(shù)據(jù)大小再分配緩沖區(qū)空間保證有足夠大,再整體解壓;然后就是模擬誤碼和丟包情況:因?yàn)樵诜职鼔嚎s過程中可以統(tǒng)計(jì)每個(gè)壓縮塊的大小,再根據(jù)壓縮塊的格式就可很容易修改Zlib頭信息、壓縮數(shù)據(jù)、檢錯(cuò)信息和Zlib容錯(cuò)方式來模擬誤碼,并且通過移除一定長度的壓縮數(shù)據(jù)來模擬丟包情況;最后對(duì)測井傳感器數(shù)據(jù)測試驗(yàn)證了容錯(cuò)能力。
2.4 壓縮算法的DSP實(shí)現(xiàn)
首先在CCS3.3編譯環(huán)境下,選擇F2812的Device Simulator仿真。其DSP擴(kuò)展一個(gè)256 KB的片外空間,因?yàn)槌绦蛟贔2812中測試程序總空耗(程序執(zhí)行消耗總資源,包括動(dòng)態(tài)分配heap空間96 KB左右)為140 KB左右,并選擇大寄存器模式;設(shè)置heap大小;在調(diào)試程序通過之后選擇XDS560 emulator將程序下載到F2812上運(yùn)行。在運(yùn)行之前設(shè)置一個(gè)定時(shí)中斷,定時(shí)從樣本數(shù)據(jù)文件中讀數(shù)據(jù)到輸入緩沖區(qū),而在壓縮程序中每次直接從輸入緩沖區(qū)中讀數(shù)據(jù)進(jìn)行壓縮。
3 實(shí)驗(yàn)與分析
在現(xiàn)代傳感器遙測遙傳網(wǎng)絡(luò)中,石油測井網(wǎng)絡(luò)是極具代表性的。隨著測井技術(shù)的發(fā)展,尤其是組合測井、成像測井的出現(xiàn),造成了測井?dāng)?shù)據(jù)的快速膨脹。但是數(shù)據(jù)傳輸帶寬的限制和實(shí)時(shí)的要求,不能夠把這些數(shù)據(jù)實(shí)時(shí)而可靠地傳到地面,成為阻礙測井技術(shù)發(fā)展的一大問題,迫切需要解決。而應(yīng)用無損數(shù)據(jù)壓縮技術(shù)來減小數(shù)據(jù)傳輸量是最有效途徑之一[5]。
所以本文以石油測井網(wǎng)絡(luò)為例,利用DSP F2812嵌入式平臺(tái)對(duì)測井?dāng)?shù)據(jù)進(jìn)行實(shí)時(shí)壓縮,并把壓縮后的數(shù)據(jù)實(shí)時(shí)傳到地面PC機(jī)后再由網(wǎng)絡(luò)傳輸?shù)娇刂浦行倪M(jìn)行實(shí)時(shí)解壓縮。測試結(jié)果如表1所示。其中樣本數(shù)據(jù)主要由自然伽瑪能譜測井儀、方位測井儀、電纜遙測傳輸儀、總線適配器等儀器采集生成。

測試結(jié)果表明,不同類型測井?dāng)?shù)據(jù)樣本壓縮率、時(shí)延和壓縮速率差異還是很明顯的,主要由于不同樣本文件的數(shù)據(jù)結(jié)構(gòu)差異很大。而且在滿足獨(dú)立分包壓縮前提下,每個(gè)包都要重新建立字典,包越小壓縮效果越差,而本方法的包只有4 KB,壓縮率基本上都在60%以下,但實(shí)時(shí)性也能達(dá)標(biāo)。因?yàn)閴嚎s速率大于測井儀器的采集數(shù)據(jù)速率(這取決于不同的儀器速率傳輸能力和采集間隔的控制,但最大不超過500 kb/s)。而在沒改進(jìn)之前,farheap空間占192 KB,heap空間占40 KB,程序總消耗約為260 KB,所以改進(jìn)后的Zlib算法運(yùn)行所占資源很少且壓縮效果很好,適合于嵌入式平臺(tái)應(yīng)用。由于壓縮程序的移植優(yōu)化只是在算法和程序結(jié)構(gòu)上,并沒有進(jìn)一步在匯編級(jí)別上的優(yōu)化,因此壓縮速率提升空間還很大。
本文針對(duì)傳感器數(shù)據(jù)在分組傳輸環(huán)境下的特點(diǎn)和要求,提出基于Zlib的傳感器數(shù)據(jù)壓縮方法,并在DSP嵌入式平臺(tái)上得到應(yīng)用驗(yàn)證。本壓縮方法具有良好的壓縮效果和壓縮速率,并且能夠?qū)崿F(xiàn)分包壓縮獨(dú)立解壓,解決了在網(wǎng)絡(luò)傳輸過程中誤碼和丟包的容錯(cuò)問題,
參考文獻(xiàn)
[1] LEMING S K,STALFORD H L.Bridge weigh-in-motion system development using superposition of dynamic truck/static bridge Interaction[C].IEEE American Control Conference,2003.
[2] 周四望,林亞平,葉松濤,等.傳感器網(wǎng)絡(luò)中一種存儲(chǔ)有效的小波漸進(jìn)數(shù)據(jù)壓縮算法[J].計(jì)算機(jī)研究與發(fā)展,2009,46(12):2085-2092.
[3] 劉貞,王祁.多傳感器信號(hào)數(shù)據(jù)采集實(shí)時(shí)壓縮算法[J].傳感技術(shù)學(xué)報(bào),2006,19(6):2712-2715.
[4] 漢澤西,郭楓,呂飛.測井?dāng)?shù)據(jù)的無損壓縮方法研究[J]. 現(xiàn)代電子技術(shù),2004(22):94-96.
[5] 郭楓,漢澤西.測井?dāng)?shù)據(jù)的無損壓縮方法研究[D].西安:西安石油大學(xué),2005.