
摘 要: 提出了一種消除中文分詞中交集型歧義的模型。首先通過(guò)正向最大匹配法和逆向最大匹配法對(duì)中文文本信息進(jìn)行分詞,,然后使用不單獨(dú)成詞語(yǔ)素表對(duì)分詞結(jié)果進(jìn)行分析對(duì)比消歧,,得到符合漢語(yǔ)語(yǔ)境的結(jié)果。整個(gè)過(guò)程分為歧義識(shí)別,、歧義分析,、歧義消除三個(gè)階段。實(shí)驗(yàn)結(jié)果表明,,該模型可以有效降低由交集型歧義引起的中文文本切分錯(cuò)誤率,。
關(guān)鍵詞: 自然語(yǔ)言處理; 分詞,; 交集型歧義
在英文和其他西方語(yǔ)言系統(tǒng)中,,文本書(shū)寫(xiě)時(shí)通常是詞與詞之間用空格隔開(kāi),但中文的書(shū)寫(xiě)形式卻是連續(xù)的字串,,詞與詞之間沒(méi)有任何標(biāo)志,。而對(duì)于中文來(lái)說(shuō),如果不進(jìn)行詞語(yǔ)的有意義切分,,句子將沒(méi)有任何的意義[1] ,。分詞是中文信息處理的第一步,就目前來(lái)說(shuō),,較為常用的中文分詞方法主要分為兩類:基于規(guī)則的方法和基于統(tǒng)計(jì)的方法[2],。基于規(guī)則的分詞方法的核心在于建立一個(gè)完備的詞典,,然后通過(guò)該詞典對(duì)句子中的切分片段進(jìn)行匹配,,以完成分詞過(guò)程。較常用的基于詞典的中文分詞方法有正向最大匹配法,、逆向最大匹配法和最佳匹配法,;基于統(tǒng)計(jì)的分詞法的基本原理是對(duì)語(yǔ)料庫(kù)中相鄰字的組合頻度進(jìn)行統(tǒng)計(jì),根據(jù)一定的頻度計(jì)算公式來(lái)決定字符串成為詞的可能性進(jìn)行分詞,。字詞共現(xiàn)的頻度高低體現(xiàn)了漢字之間結(jié)合關(guān)系的緊密程度,。當(dāng)緊密程度高于某一個(gè)閥值時(shí),便可認(rèn)為此字符串可能已經(jīng)構(gòu)成了一個(gè)詞[3-5],。這些方法有效地促進(jìn)了中文分詞研究的進(jìn)一步發(fā)展,,但在實(shí)際應(yīng)用中仍然有很多因素影響著分詞的準(zhǔn)確率,其中較常見(jiàn)的就是分詞的歧義問(wèn)題,。
本文建立了一個(gè)中文分詞的模型來(lái)減少中文分詞中的歧義問(wèn)題,,以提高分詞的準(zhǔn)確率。該模型基于正向最大匹配法和逆向最大匹配法來(lái)完成分詞過(guò)程,,通過(guò)對(duì)兩種分詞方法產(chǎn)生的分詞序列進(jìn)行比較分析,,最終通過(guò)基于罰分機(jī)制的歧義消除算法選出正確的序列來(lái)完成分詞,。
1 最大匹配法與交集型歧義
最大匹配法有正向最大匹配法MM法(Maximum Matching Method)和逆向最大匹配法RMM法(Reverse Maximum Matching Method)兩種基本方法。它們具有原理簡(jiǎn)單,、時(shí)間復(fù)雜度低,、易于實(shí)現(xiàn)等優(yōu)點(diǎn),但是不足之處在于往往不能識(shí)別出切分歧義而導(dǎo)致文本切分錯(cuò)誤[6],。 而中文語(yǔ)言環(huán)境中歧義的存在是一個(gè)很普遍的現(xiàn)象,,據(jù)統(tǒng)計(jì),MM法對(duì)于文本的錯(cuò)誤切分率為1/169,,RMM法對(duì)于文本的錯(cuò)誤切分率為1/245[7],。
導(dǎo)致分詞錯(cuò)誤的切分歧義主要有組合型歧義和交集型歧義兩種。在所有的歧義現(xiàn)象中,,普通的交集型歧義現(xiàn)象所占的比例為85%以上[8],,所以交集型歧義在中文文本中是極為常見(jiàn)的。以文本“他的確切地址在這兒”為例,,通過(guò)MM法進(jìn)行切分的結(jié)果為“他/的確/切/地址/在/這兒”,,用RMM法得到的結(jié)果為“他/的/確切/地址/在/這兒”,可見(jiàn)兩種方法得到了不一樣的分詞結(jié)果,,而有差別的“的確切”部分存在的歧義就是交集型歧義,。
2 交集型歧義消除模型
2.1 歧義分詞
歧義消除的過(guò)程通常是與分詞結(jié)合在一起的,對(duì)于中文文本來(lái)說(shuō),,如果存在歧義,,分別通過(guò)MM法和RMM法所得到分詞結(jié)果是一樣的,反之則不一樣,。對(duì)于存在交集型歧義的文本,,交集型歧義消除模型首先需要將文本用MM法和RMM法分別進(jìn)行切分以得到兩個(gè)不同的切分結(jié)果。除此之外還可以通過(guò)其他的分詞方法得到更多的切分結(jié)果,,但實(shí)驗(yàn)證明MM法和RMM法的結(jié)合分詞能夠識(shí)別出絕大多數(shù)的交集型歧義,,基于此點(diǎn)以及效率上的考慮,本文的模型中只保留使用MM法和RMM法兩種切分方法來(lái)進(jìn)行對(duì)比分析,。
以文本“他明白天為什么下雨”為例,,可以通過(guò)MM法和RMM法分別得到結(jié)果(1)和結(jié)果(2):
結(jié)果(1):他/明白/天/為什么/下雨
結(jié)果(2):他/明/白天/為什么/下雨
2.2 不單獨(dú)成詞語(yǔ)素表
在本文所研究的交集型歧義消除模型中還需要用到一個(gè)不單獨(dú)成詞語(yǔ)素表。該表包含了一些在中文語(yǔ)境中單獨(dú)出現(xiàn)通常沒(méi)有意義的一些字,,比如“第”,,當(dāng)“第”單獨(dú)出現(xiàn)時(shí)基本上沒(méi)有任何意義,但是“第”通過(guò)與其他字的組合卻能具有很多不同的意義,,例如“及第”,,“第一”等。在交集型歧義消除模型中,,不單獨(dú)成詞語(yǔ)素表所包含的不單獨(dú)成詞的語(yǔ)素完備性對(duì)分詞的模型在實(shí)際應(yīng)用當(dāng)中的文本切分準(zhǔn)確性是緊密聯(lián)系在一起的,,語(yǔ)素表完備性越高則文本切分越準(zhǔn)確,反之則越不準(zhǔn)確,。
2.3 消歧算法
交集型歧義消除模型中所使用的用來(lái)確保能夠消除歧義的算法主要原理是通過(guò)引入針對(duì)切分結(jié)果賦予權(quán)值,然后對(duì)權(quán)值進(jìn)行統(tǒng)計(jì)的方法來(lái)進(jìn)行歧義消除的,。
定義:ABC為文本,,A,、B,、C均為切分單元,即ABC可被切為A/B/C,,A,、B、C分別被賦予初始權(quán)值R(A)=R(B)=R(C)=1,。
現(xiàn)假設(shè)切分結(jié)果“A/B/C”中只有切分單元B屬于2.2節(jié)所構(gòu)建的不單獨(dú)成詞語(yǔ)素表,,則切分單元B的權(quán)值會(huì)增加,即R(B)=2,。
然后對(duì)切分結(jié)果“A/B/C”的權(quán)值進(jìn)行統(tǒng)計(jì),,R(A)+R(B)+R(C)=1+2+1=4,通過(guò)不同的方法可以得到不同的切分結(jié)果,不同的切分結(jié)果的權(quán)值統(tǒng)計(jì)也會(huì)有區(qū)別,。交集型歧義消除模型會(huì)將各個(gè)結(jié)果的權(quán)值統(tǒng)計(jì)進(jìn)行比較分析,選出統(tǒng)計(jì)值較小的一個(gè)為消除歧義后的切分結(jié)果,。
對(duì)于文中2.1節(jié)分別通過(guò)MM法和RMM法獲得的結(jié)果(1)和結(jié)果(2),分別對(duì)切分單元賦予初始權(quán)值:
結(jié)果(1):R(他)=R(明白)=R(天)=R(為什么)=R(下雨)=1,;
結(jié)果(2):R(他)=R(明)=R(白天)=R(為什么)=R(下雨)=1,;
通過(guò)將結(jié)果(1)和結(jié)果(2)與不單獨(dú)成詞語(yǔ)素表進(jìn)行匹配,可以判斷結(jié)果(2)中的“明”字屬于不單獨(dú)成詞語(yǔ)素,,即R(明)=2,,通過(guò)結(jié)果權(quán)值統(tǒng)計(jì):
結(jié)果(1):R(他)+R(明白)+R(天)+R(為什么)+R(下雨)=1+1+1+1+1=5;
結(jié)果(2):R(他)+R(明)+R(白天)+R(為什么)+R(下雨)=1+2+1+1+1=6,;
然后通過(guò)對(duì)結(jié)果進(jìn)行比較,,交集型歧義消除模型選取權(quán)值統(tǒng)計(jì)較小的結(jié)果(1)為消歧后的正確結(jié)果,同時(shí)該結(jié)果也完全符合中文語(yǔ)境下的正確的表達(dá)意義,。
2.4 模型示意圖
通過(guò)以上的分析描述,,交集型歧義消除模型消歧的過(guò)程主要分為三個(gè)步驟:發(fā)現(xiàn)歧義、分析歧義,、消除歧義,。發(fā)現(xiàn)歧義是通過(guò)MM法和RMM法對(duì)文本進(jìn)行切分對(duì)比來(lái)識(shí)別歧義的存在;分析歧義的過(guò)程是以不單獨(dú)成詞語(yǔ)素表為基礎(chǔ),,通過(guò)對(duì)文本切分單元進(jìn)行權(quán)值賦予與統(tǒng)計(jì)來(lái)完成的,;最后的消除歧義步驟則是對(duì)分析歧義的結(jié)果進(jìn)行對(duì)比,剔除切分錯(cuò)誤文本來(lái)消除歧義。圖1是交集型歧義消除的示意圖,。
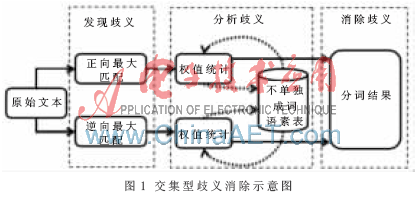
3 實(shí)驗(yàn)及結(jié)果
對(duì)于中文分詞來(lái)說(shuō),分詞的高效性和準(zhǔn)確性是極其重要的,。在相同的條件下,,更準(zhǔn)確、更高效的分詞方法就意味著更好的分詞性能以及更快的分詞速度,。
(1) 效率分析
根據(jù)本文中的分詞策略,,對(duì)于一個(gè)中文句子來(lái)說(shuō),分別用正向最大匹配法和逆向最大匹配法得到兩個(gè)分詞結(jié)果序列,,然后通過(guò)不單獨(dú)成詞語(yǔ)素表來(lái)對(duì)兩個(gè)結(jié)果序列進(jìn)行分析,,整個(gè)分析過(guò)程不涉及到其他的分詞方法。而正向最大匹配法和逆向最大匹配法基于其實(shí)現(xiàn)原理分詞效果是非常理想的,,在所有的中文分詞系統(tǒng)中基本上都可以找到這兩種方法的身影,,所以本文中的分詞過(guò)程基于正向最大匹配法和逆向最大匹配法這兩種基本方法,然后再結(jié)合不單獨(dú)成詞語(yǔ)素表,,使分詞的效率得到了保證,。
(2) 準(zhǔn)確性分析
在中文自然語(yǔ)言處理領(lǐng)域,正向最大匹配法和逆向最大匹配法是兩個(gè)最基本的分詞方法,,不幸的是這兩種方法都不能很好地解決中文語(yǔ)言環(huán)境中的分詞歧義問(wèn)題,。因此,針對(duì)于這一系列因素,,本文中提到的交集型歧義消除模型利用對(duì)切分結(jié)果進(jìn)行基于不單獨(dú)成詞語(yǔ)素表的權(quán)值統(tǒng)計(jì)來(lái)選出相對(duì)權(quán)值較小的切分結(jié)果,,進(jìn)而保證中文分詞中的交集型歧義的發(fā)現(xiàn)與消除。
(3) 實(shí)驗(yàn)結(jié)果分析
基于以上的規(guī)則,,本文中開(kāi)發(fā)了一個(gè)交集型歧義消除系統(tǒng),,其中不單獨(dú)成詞語(yǔ)素表包含了4 871個(gè)不單獨(dú)成詞語(yǔ)素,同時(shí)從2012年的人民日?qǐng)?bào)中選取了6篇文章作為實(shí)驗(yàn)的原始語(yǔ)料庫(kù)。通過(guò)用交集型歧義消除模型獲得的消歧結(jié)果與單獨(dú)使用正向最大匹配法和逆向最大匹配法所得到的結(jié)果進(jìn)行對(duì)比來(lái)分析系統(tǒng)的效率和準(zhǔn)確度,。
表1和表2分別為單獨(dú)使用MM法和RMM法進(jìn)行文本切分時(shí)的切分準(zhǔn)確率,。表3為采用交集型歧義消除模型進(jìn)行切分的準(zhǔn)確率,從中可以看到交集型歧義消除模型針對(duì)于同一語(yǔ)料庫(kù)的文本切分準(zhǔn)確率最高,。
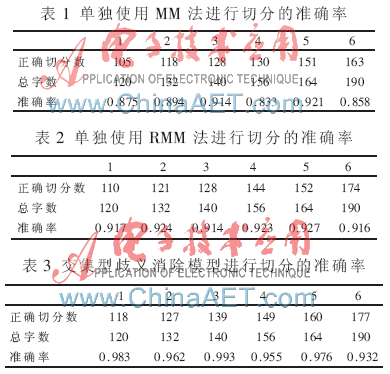
圖2為MM法,、RMM法和交集型歧義消除模型切分準(zhǔn)確率的對(duì)比。從圖2中可以看出,,交集型歧義消除模型對(duì)文本切分中的交集型歧義消除準(zhǔn)確率比單獨(dú)使用正向最大匹配法和逆向最大匹配法的切分準(zhǔn)確率要高,。

圖3是交集型歧義消除模型與MM法、RMM法在文本切分效率上的對(duì)比,。從圖3中可以看出,,交集型歧義消除模型雖然較MM法和RMM法額外使用了不單獨(dú)成詞語(yǔ)素表,但在效率上并沒(méi)有明顯的降低,。
通過(guò)以上的實(shí)驗(yàn)可以看出,,交集型歧義消除模型可以很好地發(fā)現(xiàn)并解決中文語(yǔ)言環(huán)境下的交集型歧義問(wèn)題,并且具有較高的效率和準(zhǔn)確率,。根據(jù)實(shí)驗(yàn)數(shù)據(jù)可知,,本系統(tǒng)的分詞結(jié)果準(zhǔn)確率比單純使用正向最大匹配法和逆向最大匹配法高得多,;另一方面,由于使用了不單獨(dú)成詞語(yǔ)素表,,本文算法的分詞效率較原始的正向最大匹配法和逆向最大匹配法有略微的降低,。但結(jié)合效率和準(zhǔn)確性來(lái)進(jìn)行整體分析,可以看到交集型歧義消除模型對(duì)于解決中文分詞中的交集型歧義是非常有價(jià)值的,。
本文基于不單獨(dú)成詞語(yǔ)素表及常用的分詞方法提供了一個(gè)中文分詞中的交集型歧義的解決方案,。實(shí)驗(yàn)結(jié)果表明,交集型歧義消除模型能夠很好地解決中文分詞中的交集型歧義問(wèn)題,,希望本文的研究成果能夠?qū)χ形姆衷~歧義消除領(lǐng)域的發(fā)展起到一定的推動(dòng)作用,。
參考文獻(xiàn)
[1] 孫茂松,鄒嘉彥. 漢語(yǔ)自動(dòng)分詞研究評(píng)述[J]. 當(dāng)代語(yǔ)言學(xué),,2001(1):22-32.
[2] 麥范金,王挺.基于雙向最大匹配和HMM 的分詞消歧模型[J].現(xiàn)代圖書(shū)情報(bào)技術(shù),2008(8):37-41.
[3] 施彤年,,盧忠良,,榮融,等.多類多標(biāo)簽漢語(yǔ)文本自動(dòng)分類的研究[J]. 情報(bào)學(xué)報(bào), 2003,22(3):306-309.
[4] 鄒海山,,吳勇,,吳月珠,等.中文搜索引擎中的中文信息處理技術(shù)[J]. 計(jì)算機(jī)應(yīng)用研究, 2000(12).
[5] 趙偉,,戴新宇,,尹存燕,等.一種規(guī)則與統(tǒng)計(jì)相結(jié)合的漢語(yǔ)分詞方法[J]. 計(jì)算機(jī)應(yīng)用研究, 2004(3):23-25.
[6] 劉穎.計(jì)算語(yǔ)言學(xué)[M].北京:清華大學(xué)出版社,,2002.
[7] 梁南元.書(shū)面漢語(yǔ)自動(dòng)分詞系統(tǒng)——CDWS[J]. 中文信息學(xué)報(bào),,1987(2):44-52.
[8] 一種Hash高速分詞算法[J].解放軍理工大學(xué)學(xué)報(bào)(自然科學(xué)版),2004,5(2):40-42.