0 引言
語音識別技術(shù)的目的是使機(jī)器能理解人類語言,最終使人機(jī)通信成為現(xiàn)實(shí)。在過去幾十年,自動語音識別(AutomaticSpeech Recognition,ASR)技術(shù)已經(jīng)取得了非常重大的進(jìn)步。
ASR系統(tǒng)已經(jīng)能從處理像數(shù)字之類的小詞匯量到廣播新聞之類的大詞匯量。然而針對識別效果來說,ASR 系統(tǒng)則相對較差。尤其在會話任務(wù)上,自動語音識別系統(tǒng)遠(yuǎn)不及人類。因此,語音識別技術(shù)的應(yīng)用已成為一個極具競爭性和挑戰(zhàn)性的高新技術(shù)產(chǎn)業(yè)。
隨著DSP技術(shù)的快速發(fā)展及性能不斷完善,基于DSP的語音識別算法得到了實(shí)現(xiàn),并且在費(fèi)用、功耗、速度、精確度和體積等方面有著PC機(jī)所不具備的優(yōu)勢,具有廣闊的應(yīng)用前景。
1 系統(tǒng)參數(shù)選擇
一般情況下,語音識別系統(tǒng)按照不同的角度、不同的應(yīng)用范圍、不同的性能要求有不同的分類方法。針對識別對象不同有孤立詞識別、連接詞識別、連續(xù)語音識別與理解和會話語音識別等。針對識別系統(tǒng)的詞匯量有小詞匯量語音識別(1~20個詞匯)、中詞匯量識別(20~1 000個詞匯)和大詞匯量(1 000以上個詞匯)語音識別。針對發(fā)音人范圍來分,分為特定人語音識別、非特定人語音識別、自適應(yīng)語音識別。
本文主要研究非特定人小詞匯量連續(xù)語音實(shí)時(shí)識別系統(tǒng)。
1.1 語音識別系統(tǒng)
語音識別本質(zhì)上是一種模式識別的過程,即未知語音的模式與已知語音的參考模式逐一進(jìn)行比較,最佳匹配的參考模式被作為識別結(jié)果。語音識別系統(tǒng)一般包括前端處理、特征參數(shù)提取、模型訓(xùn)練和識別部分。圖1所示是基于模式匹配原理的語音識別系統(tǒng)框圖。
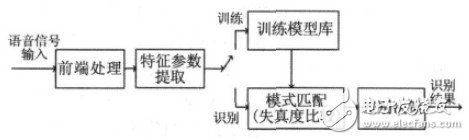
圖1 語音識別系統(tǒng)基本框圖
1.2 特征參數(shù)
語音信號中含有非常豐富的信息,包括影響語音識別的重要信息,也包括對語音識別無關(guān)緊要甚至?xí)档妥R別率的冗余信息。特征提取則可以去除冗余信息,將能準(zhǔn)確表征語音信號特征的聲學(xué)參數(shù)提取出來用于后端的模型建立和匹配,大大減少了存儲空間、訓(xùn)練和測試時(shí)間。對特定人語音識別來說,希望提取的特征參數(shù)盡可能少的反映語義信息,盡可能多的反映說話人的個人信息,而對非特定人語音識別來說,則相反。
現(xiàn)在較常用的特征參數(shù)有線性預(yù)測參數(shù)(LPCC)、線譜對(LSP)參數(shù)、Mel頻率倒譜參數(shù)(MFCC)、感覺加權(quán)的線性預(yù)測(PLP)參數(shù)、動態(tài)差分參數(shù)和高階信號譜類特征等,尤其是LPCC和MFCC兩種參數(shù)最為常用。本文選擇MFCC作為特征參數(shù)。
1.3 模型訓(xùn)練及模式識別
在識別系統(tǒng)后端,從已知模式中獲取用以表征該模式本質(zhì)特征的模型參數(shù)即形成模式庫,再將輸入的語音提取特征矢量參數(shù)后與已建立的聲學(xué)模型進(jìn)行相似度比較,同時(shí)根據(jù)一定的專家知識(如構(gòu)詞規(guī)則,語法規(guī)則等)和判別規(guī)則決策出最終的識別結(jié)果。
目前,語音識別所應(yīng)用模型匹配技術(shù)主要有動態(tài)時(shí)間規(guī)整(DTW)、隱馬爾可夫模型(HMM)、人工神經(jīng)元網(wǎng)絡(luò)(ANN)和支持向量機(jī)(SVM)等。DTW 是基本的語音相似性或相異性的一種測量工具,僅僅適合于孤立詞語音識別系統(tǒng)中。在解決非特定人、大詞匯量、連續(xù)語音識別問題時(shí)較之HMM 算法相形見絀。HMM 模型是隨機(jī)過程的數(shù)學(xué)模型,它用統(tǒng)計(jì)方式建立語音信號的動態(tài)模型,將聲學(xué)模型和語言模型融入語音識別搜索算法中,被認(rèn)為是語音識別中最有效的模型。
然而由Vapnik和co-workers提出來的SVM 基于結(jié)構(gòu)風(fēng)險(xiǎn)最小化準(zhǔn)則和非線性和函數(shù),具有更好的泛化能力和分類精確度。目前,SVM 已經(jīng)成功應(yīng)用于語音識別與話者識別。
除此之外,Ganapathiraju等人已經(jīng)將支持向量機(jī)成功運(yùn)用到復(fù)雜的大詞表非特定人連續(xù)語音識別上來。因此本文選擇SVM結(jié)合VQ完成語音模式識別。
2 系統(tǒng)構(gòu)建及實(shí)現(xiàn)
為了更好地體現(xiàn)DSP的實(shí)時(shí)性,選擇的合適參數(shù)相當(dāng)重要。考慮到DSP的存儲容量和實(shí)時(shí)性要求,本文首先選用Matlab平臺對系統(tǒng)進(jìn)行仿真以比較選取合適的參數(shù)。
2.1 Matlab平臺上的仿真實(shí)現(xiàn)
2.1.1 實(shí)驗(yàn)數(shù)據(jù)的建立
基于Matlab平臺,本文實(shí)驗(yàn)語音信號在安靜的實(shí)驗(yàn)室環(huán)境下用普通的麥克風(fēng)通過Windows音頻設(shè)備和Cool edit軟件進(jìn)行錄制,語速一般,音量適中,文件存儲格式為wav文件。語音采樣頻率為8kHz,采樣量化精度為16bit,雙聲道。
由于無調(diào)音節(jié)有412個,有調(diào)音節(jié)為1 282個,若采用SVM 對所有音節(jié)進(jìn)行分類,數(shù)據(jù)量很龐大,故本文選擇10個人對6個不固定的連續(xù)漢語數(shù)字進(jìn)行發(fā)音,每人發(fā)音15次,音節(jié)切分后共900個樣本,其中600個樣本作為訓(xùn)練樣本集,其余300個樣本用于特定人的識別;另外選擇5個人對漢語數(shù)字0~9發(fā)音,每人發(fā)音3次,共150個測試樣本作為非特定人的識別。此外,以上選取的訓(xùn)練或測試樣本均考慮到0~9共10個數(shù)字的均勻分布,并且樣本類型通過手工標(biāo)定。
2.1.2 基于Matlab的語音識別系統(tǒng)的仿真及性能分析
首先對語音信號進(jìn)行了預(yù)處理及時(shí)域分析:使用H(Z)=1-0.9375z-1 進(jìn)行預(yù)加重處理;同時(shí)考慮語音信號的短時(shí)平穩(wěn)性,進(jìn)行分幀加窗---選用Hamming窗,幀長32ms,幀移是10ms.本文所設(shè)計(jì)系統(tǒng)為小詞匯量的連續(xù)語音識別,考慮到訓(xùn)練時(shí)的工作量和運(yùn)算量,選用音節(jié)作為基本識別單元。語音特征參數(shù)矢量采用12維MFCC、12維一階MFCC以及每幀的短時(shí)歸一化能量共25維構(gòu)成。
本文構(gòu)造了基于SVM 的連續(xù)語音識別系統(tǒng)。系統(tǒng)前端采用MFCC特征參數(shù)、并用遺傳算法(GA)與矢量量化(VQ)混合算法對其進(jìn)行聚類得到優(yōu)化碼本,然后將所得碼本作為 SVM 模式訓(xùn)練和識別算法的輸入,按照相應(yīng)的準(zhǔn)則最終得到識別的結(jié)果。語音識別系統(tǒng)流程圖如圖2所示。
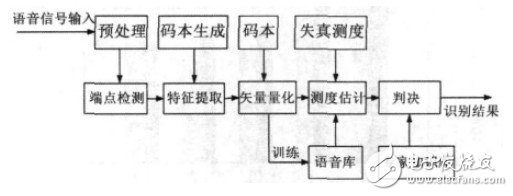
圖2 語音識別系統(tǒng)流程圖
首先對不同初始種群數(shù)的語音識別系統(tǒng)性能進(jìn)行了分析。表1給出了不同初始種群下的識別系統(tǒng)性能,從表中可以得出,在迭代次數(shù)為100、初始種群數(shù)為100時(shí),種群最終平均適應(yīng)度和正識率最高,之后隨著初始種群數(shù)繼續(xù)增加,平均適應(yīng)度和正識率都在降低。綜合考慮迭代所需時(shí)間和正識率,本文折衷采用初始種群數(shù)為80進(jìn)行系統(tǒng)的仿真和實(shí)現(xiàn)。
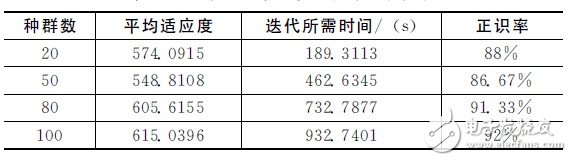
表1 不同初始種群下的識別系統(tǒng)性能
種群數(shù)平均適應(yīng)度迭代所需時(shí)間/ (s) 正識率系統(tǒng)設(shè)計(jì)中考慮到MFCC參數(shù)數(shù)據(jù)量太大,對模型訓(xùn)練和識別的時(shí)間有很大的影響,因此選擇矢量量化對數(shù)據(jù)進(jìn)行分類。矢量量化的關(guān)鍵問題是如何獲取VQ碼本及碼本長度的確定,對此進(jìn)行了仿真比較。
表2給出了不同VQ算法對正識率的影響比較。由表可以采用種群數(shù)為80,碼本長度為16,核函數(shù)為 RBF,選用的改進(jìn)遺傳算法(GA)時(shí)系統(tǒng)的正識率要明顯高于LBG和傳統(tǒng)GA.LBG容易陷入局部最優(yōu),傳統(tǒng)GA 具有全局搜索能力,但收斂速度慢。實(shí)驗(yàn)證明,改進(jìn)的GA較好地解決了這兩者的問題,收斂速度較快,正識率也有較為明顯的提高。
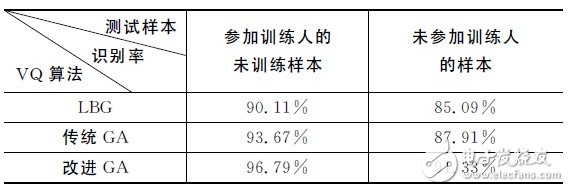
表2 不同VQ算法對正識率的影響比較
在此基礎(chǔ)上比較了傳統(tǒng)GA和優(yōu)化后GA對不同碼本長度失真測度的影響,如圖3所示。由圖可知,在碼本平均失真測度上,改進(jìn)的GA比傳統(tǒng)GA在整體上明顯有所降低,即種群平均適應(yīng)度更高。從圖3還可以發(fā)現(xiàn)碼本長度為32時(shí)失真測度達(dá)到最低,但相比碼本長度為16時(shí)的值減少的并不太明顯。 考慮到迭代時(shí)間問題,本文所采用的碼本長度為16.
不同SVM 核函數(shù)對語音識別系統(tǒng)性能也會有影響。SVM分類器的目的是設(shè)計(jì)一個具有良好性能的分類超平面,以滿足在高維特征空間中能通過這個分類超平面區(qū)分多類數(shù)據(jù)樣本。
已有文獻(xiàn)證明一對一分類器在邊界距離上比一對多分類器更精確,故本文采用一對一方法對多類數(shù)據(jù)樣本進(jìn)行訓(xùn)練和識別。
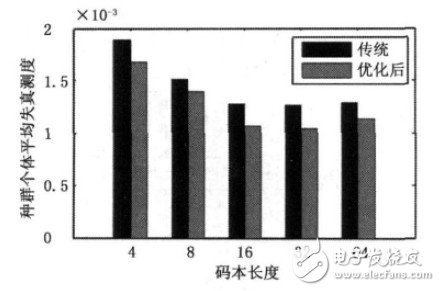
圖3 碼本長度的失真測度對比
表3給出了針對非特定人的不同SVM 核函數(shù)的識別系統(tǒng)性能。表中顯示,在取C =3,γ= 125(這里的25為特征參數(shù)維數(shù))情況下,盡管核函數(shù)為RBF時(shí)所需的支持向量數(shù)要略高于核函數(shù)為Sigmoid時(shí),但系統(tǒng)的正確識別率要明顯高于采用其他核函數(shù)的系統(tǒng),因此本文選取RBF作為核函數(shù)。
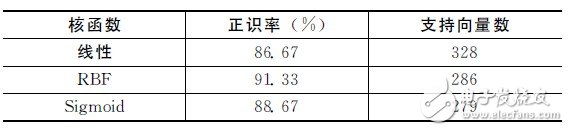
表3 不同SVM 核函數(shù)的識別系統(tǒng)性能
通過Matlab仿真分析了不同的矢量量化算法、SVM 核函數(shù)和初始種群數(shù)對語音識別系統(tǒng)性能產(chǎn)生的影響,為語音識別系統(tǒng)在DSP上的實(shí)現(xiàn)提供了參數(shù)和模型的選擇。
2.2 語音識別系統(tǒng)在DSP上的實(shí)現(xiàn)
2.2.1 實(shí)驗(yàn)數(shù)據(jù)的建立
所有語音信號在安靜的實(shí)驗(yàn)室環(huán)境下獲得。基于DSP 平臺的實(shí)時(shí)識別實(shí)驗(yàn)系統(tǒng),語音信號通過麥克風(fēng)輸入,使用TLV320AIC23對模擬語音信號進(jìn)行采樣。語音采樣頻率為8kHz,采樣量化精度為 16bit,雙聲道。考慮到Flash存儲空間有限,本文選用自建語音庫中900個樣本中的40個樣本作為訓(xùn)練樣本建立模型參數(shù)。
2.2.2 語音識別系統(tǒng)的硬件結(jié)構(gòu)
由于語音識別系統(tǒng)算法復(fù)雜度較高,同時(shí)考慮到實(shí)時(shí)性,本文選擇TI公司的TMS320C6713DSK 作為硬件開發(fā)平臺。
TMS320C6713DSK是一款低成本獨(dú)立開發(fā)應(yīng)用板,其最高工作時(shí)鐘頻率可以達(dá)到225MHz,且是高性能的浮點(diǎn)數(shù)字信號處理器。且?guī)в蠺LV320AIC23 立體編解碼器,8M 字節(jié)32bit的SDRAM,512k字節(jié),8bit的非易失性Flash存儲器。
本系統(tǒng)針對的是非特定人小詞匯量連續(xù)語音的識別,硬件結(jié)構(gòu)如圖4所示,主要包括語音數(shù)據(jù)采集模塊、數(shù)據(jù)傳輸模塊、數(shù)據(jù)處理模塊、程序數(shù)據(jù)存儲及Flash引導(dǎo)裝載模塊、數(shù)據(jù)存儲器RAM 模塊及其他相關(guān)模塊。
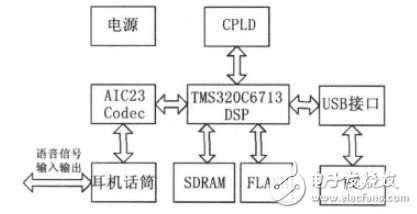
圖4 系統(tǒng)硬件結(jié)構(gòu)圖
數(shù)據(jù)采集模塊主要采用TLV320AIC23編解碼器來實(shí)現(xiàn)對語音數(shù)據(jù)的采集。由AIC23采集的數(shù)字信號數(shù)據(jù)通過McBSP1存入SDRAM 中,數(shù)據(jù)傳輸方式為EDMA方式下的McBSP數(shù)據(jù)傳輸。數(shù)據(jù)處理模塊是系統(tǒng)的核心模塊,用TMS320C6713DSP芯片來完成語音識別算法的實(shí)現(xiàn)。訓(xùn)練時(shí),DSP完成語音信號MFCC特征參數(shù)的提取、SVM 建模并存入Flash中;識別時(shí),DSP讀取待識別語音信號數(shù)據(jù)并將獲得的模型參數(shù)與訓(xùn)練模型參數(shù)進(jìn)行比較,進(jìn)而得到識別結(jié)果。
2.2.2 基于DSP的語音識別系統(tǒng)的實(shí)現(xiàn)及分析
本系統(tǒng)設(shè)計(jì)主要涉及到語音數(shù)據(jù)段、執(zhí)行代碼段、載入Flash的程序段和模型參數(shù)段等。在編程中主要以C語言編程為主,配合使用匯編語言,使程序運(yùn)行效率更高。
實(shí)驗(yàn)結(jié)果及其性能分析:
訓(xùn)練時(shí),系統(tǒng)上電,加入工程項(xiàng)目。圖5所示為讀取“12345”的語音時(shí)部分主程序、對音節(jié)切分后數(shù)字“1”提取的語音及其第10幀的MFCC參數(shù)、mfcc子程序等。
圖5 MFCC參數(shù)
識別過程中,將存入Flash中的訓(xùn)練模型參數(shù)依次讀出,與待識別語音信號的MFCC參數(shù)比較,最后得到識別結(jié)果。
實(shí)驗(yàn)中讀取20句話,每句話含有6個不同漢語數(shù)字的連續(xù)語音,通過對其進(jìn)行測試,得到識別率為76.7%.圖6是對音節(jié)切分后的數(shù)字“2”的識別情況,在STD欄輸出了最后識別結(jié)果即數(shù)字“2”。
3 結(jié)論
本文通過在Matlab平臺上進(jìn)行仿真實(shí)驗(yàn)選取合適的參數(shù)及模型,并將其移植到 TMS320C6713DSK上實(shí)現(xiàn)了非特定人小詞匯量連續(xù)語音識別系統(tǒng)。其中基于TLV320AIC23完成了對語音數(shù)據(jù)的采集,借助SDRAM 和Flash進(jìn)行數(shù)據(jù)存儲,并采用短時(shí)能量和短時(shí)過零率進(jìn)行語音信號的初步判定,結(jié)合起來進(jìn)行測試,在Windows7操作系統(tǒng)中使用DirectX SDK 9.0b進(jìn)行視頻顯示,QR解碼程序?yàn)樽孕芯幹疲⑴cTPS自動測試臺集成。連續(xù)地采集視頻,在計(jì)算機(jī)顯示屏上實(shí)時(shí)顯示影像圖的同時(shí)進(jìn)行條碼解碼定位,結(jié)果顯示單幀圖像的平均解碼時(shí)間為630ms,使用幀相關(guān)算法后,平均解碼時(shí)間為124ms.
圖6為在單碼定位時(shí)預(yù)估未定位條碼的結(jié)果,q1為已定位碼,q2,q3,q4為未定位碼,由q1預(yù)估q2,q3,q4的結(jié)果為圖中的加亮框表示,對框區(qū)域外擴(kuò)使其包含完整條碼,然后把擴(kuò)域后的子區(qū)域獨(dú)立出來,作為下一幀條碼解碼的有效區(qū)域以提高圖像處理速度。

圖5 視頻輔助探針定位

圖6 單碼定位的預(yù)估結(jié)果
本方法在采用幀相關(guān)及位置相關(guān)算法后,在普通PC上實(shí)現(xiàn)實(shí)時(shí)視頻,并具有如下特點(diǎn):
a)無需夾具,允許遮擋,允許測試板和探頭位置變化;探針和目標(biāo)點(diǎn)標(biāo)記同時(shí)出現(xiàn)影像圖上,直接引導(dǎo),無需在影像和實(shí)板上對照查找,提高探測效率,減小出錯機(jī)會。
b)QR碼定位符含測試板信息,可以在PCB板制作過程中通過絲印到PCB板上,也可以在后期紙制粘貼到PCB板上(但要精確地保證每塊板上的QR碼位置相同),允許同一板面任意多定位碼,以區(qū)分不同PCB板及不同板面,用作PCB加電前預(yù)檢測,可保證加電安全。
