
文獻(xiàn)標(biāo)識(shí)碼: A
文章編號(hào): 0258-7998(2013)09-0135-04
結(jié)構(gòu)生物信息學(xué)已成為當(dāng)前計(jì)算機(jī)科學(xué)領(lǐng)域的一個(gè)研究熱點(diǎn)。其主要研究目標(biāo)是獲取生物系統(tǒng)的高分辨率結(jié)構(gòu)信息,從而精確地推理系統(tǒng)的功能、預(yù)測(cè)某些修改或擾動(dòng)對(duì)系統(tǒng)造成的影響。與生物信息學(xué)的其他領(lǐng)域相比,結(jié)構(gòu)生物信息學(xué)面臨眾多新的挑戰(zhàn)。其中之一是多數(shù)結(jié)構(gòu)生物信息學(xué)問(wèn)題的搜索空間是連續(xù)的;換言之,生物系統(tǒng)的微觀結(jié)構(gòu)一般通過(guò)原子在空間坐標(biāo)系中的位置來(lái)表示,而坐標(biāo)通常是連續(xù)變量,因此搜索空間是無(wú)窮的。雖然某些近似方法可以在一定程度上應(yīng)對(duì)結(jié)構(gòu)生物信息學(xué)問(wèn)題的這種連續(xù)特性,但是從搜索空間中求得最終解仍然需要進(jìn)行大量的運(yùn)算[1]。
DNA-蛋白質(zhì)匹配是生物信息學(xué)的一個(gè)重要問(wèn)題。傳統(tǒng)的序列分析方法往往會(huì)導(dǎo)致較高的多重檢驗(yàn)錯(cuò)誤率(false-positive rate)[2]。多數(shù)基于結(jié)構(gòu)生物信息學(xué)的DNA-蛋白質(zhì)匹配方法把獲得轉(zhuǎn)錄因子-DNA組合體的信息作為一個(gè)必備條件,而轉(zhuǎn)錄因子-DNA組合體的信息通常需要通過(guò)實(shí)驗(yàn)獲得,這種實(shí)驗(yàn)通常需要耗費(fèi)大量的時(shí)間。參考文獻(xiàn)[2]提出的基于退火算法的匹配算法避開(kāi)了這個(gè)問(wèn)題,但是使用該方法進(jìn)行DNA-蛋白質(zhì)匹配仍需要較大的運(yùn)算量。參考文獻(xiàn)[3]基于參考集索引技術(shù)提出了一種快速的序列分析算法,并將其應(yīng)用于DNA-蛋白質(zhì)匹配。參考文獻(xiàn)[4]采用多CPU的方式設(shè)計(jì)實(shí)現(xiàn)了并行化的DNA-蛋白質(zhì)序列分析方法,并取得了較高的加速比。但上述工作均未涉及基于結(jié)構(gòu)生物信息學(xué)的匹配方法的加速問(wèn)題。
應(yīng)對(duì)大運(yùn)算量問(wèn)題的一個(gè)常用方法是并行計(jì)算。NVIDIA公司統(tǒng)一計(jì)算設(shè)備架構(gòu)CUDA(Compute Unified Device Architecture)是一種全新的并行計(jì)算架構(gòu)。在CUDA的支持下,通用計(jì)算圖形處理單元GPGPU(General Purpose Graphic Processing Unit)可以作為一種通用的效率、硬件加速器,發(fā)揮出強(qiáng)大的運(yùn)算能力[5]。
本文針對(duì)參考文獻(xiàn)[2]的DNA-蛋白質(zhì)匹配方法,從計(jì)算的角度對(duì)其進(jìn)行分析,設(shè)計(jì)實(shí)現(xiàn)并優(yōu)化了基于CUDA的加速方法,通過(guò)實(shí)驗(yàn)驗(yàn)證了其加速性能。
1 相關(guān)知識(shí)介紹
1.1 基于退火算法的DNA-蛋白質(zhì)匹配算法
給定一條DNA鏈和一條蛋白質(zhì)鏈,兩者之間的相對(duì)位置存在很多種可能。假定兩者均為剛體,DNA-蛋白質(zhì)組合體的物理能量主要受兩者相對(duì)位置的影響,組合體的物理能量越低,其穩(wěn)定性越強(qiáng)。該方法試圖尋找使得組合體最穩(wěn)定的相對(duì)位置,這一結(jié)果對(duì)生物信息學(xué)的研究具有重要意義。
從計(jì)算的角度看,該方法的基礎(chǔ)是退火算法。為了提高搜索精度,該匹配方法通常需要隨機(jī)產(chǎn)生大量初始“種子”,為每個(gè)“種子”啟動(dòng)一個(gè)基于退火算法的搜索過(guò)程,在整個(gè)解空間中尋找最穩(wěn)定的相對(duì)位置。這種匹配方法的流程如圖1所示。

圖1中的初始值為T(mén)0,溫度T及溫度衰減周期interval為正整數(shù),溫度衰減系數(shù)為a。每當(dāng)算法所經(jīng)歷的平移和旋轉(zhuǎn)次數(shù)達(dá)到interval的非零整數(shù)倍時(shí),T衰減為原來(lái)的a倍(0<a<1),Tmin為溫度的最小值。
DNA-蛋白質(zhì)組合體的物理能量E1、E2分別代表第n次(1≤n≤Smax,Smax為平移和旋轉(zhuǎn)次數(shù)的最大值)平移和旋轉(zhuǎn)前后組合體的物理能量。Emin代表通過(guò)算法得到的組合體物理能量的最小值。如果E2<E1,則接受第n次平移和旋轉(zhuǎn)的結(jié)果;否則,計(jì)算指數(shù)式exp(-(E2-E1)/T)的值,并使用C++庫(kù)函數(shù)drand48( )產(chǎn)生一個(gè)在區(qū)間[0,1]上均勻分布的隨機(jī)數(shù)。如果指數(shù)式的值小于隨機(jī)數(shù)的值,則接受第n次平移旋轉(zhuǎn)的結(jié)果,反之不接受。
step為當(dāng)前進(jìn)行到了第幾次平移和旋轉(zhuǎn)。
1.2 CUDA編程模型及線程調(diào)度方式的特點(diǎn)
CUDA程序通常包含CPU串行代碼和GPU并行代碼,后者被稱(chēng)作CUDA程序的內(nèi)核。在執(zhí)行內(nèi)核時(shí),CUDA會(huì)產(chǎn)生大量并行工作的線程,以單指令多數(shù)據(jù)SIMD(Single Instruction Multiple Data)方式完成整個(gè)內(nèi)核的計(jì)算任務(wù)。CUDA采用網(wǎng)格(grid)和線程塊(block)來(lái)組織線程[6]。一個(gè)block的線程又被劃分為一個(gè)或多個(gè)線程組(warp)。warp是CUDA程序最基本的調(diào)度單位,屬于同一個(gè)warp的各個(gè)線程會(huì)從CUDA程序代碼段中相同的程序地址同時(shí)開(kāi)始執(zhí)行,但是各線程具有獨(dú)立的當(dāng)前指令指針和寄存器狀態(tài)。因此,各線程可能會(huì)有不同的執(zhí)行路徑,例如執(zhí)行不同的分支選擇結(jié)構(gòu)代碼或循環(huán)結(jié)構(gòu)代碼[7]。warp執(zhí)行特點(diǎn)如圖2所示。

假設(shè)一個(gè)warp中共有4個(gè)線程:線程1~線程4,它們的執(zhí)行時(shí)間分別是t1~t4,并且t3<t1<t2<t4。因?yàn)镃UDA的基本調(diào)度單位是一個(gè)完整的warp而非單個(gè)線程,所以整個(gè)warp的執(zhí)行時(shí)間取決于執(zhí)行時(shí)間最長(zhǎng)的線程t4。其他3個(gè)線程在執(zhí)行完畢后必須等待還沒(méi)有執(zhí)行完畢的線程,因此有一段時(shí)間處于空閑狀態(tài),相應(yīng)的計(jì)算資源也就被閑置了。例如,線程3閑置的計(jì)算資源最多,其空閑時(shí)長(zhǎng)為(t4-t3)。造成計(jì)算資源閑置的原因是同一warp中各個(gè)線程的執(zhí)行路徑不同;而CUDA采用的是SIMD并行方式,執(zhí)行路徑的不同是由每個(gè)線程所處理的數(shù)據(jù)差異造成的。因此,依照一定規(guī)則對(duì)數(shù)據(jù)進(jìn)行重新排列是減少這種計(jì)算資源閑置狀況的常用方法[8]。重排規(guī)則通常視具體應(yīng)用而定。
2 使用CUDA加速DNA-蛋白質(zhì)匹配
2.1 從計(jì)算角度分析匹配算法
匹配方法的流程已由圖1給出,除參數(shù)初始化外,該方法可分為三部分: (1)平移、旋轉(zhuǎn)DNA和蛋白質(zhì);(2)計(jì)算DNA-蛋白質(zhì)組合體的能量;(3)后續(xù)處理。這3部分在普通CPU平臺(tái)上所耗時(shí)間依次為: 73.624 s、1 138.945 s、110.809 s(僅使用一個(gè)隨機(jī)初始種子,退火算法參數(shù)的預(yù)設(shè)值及軟硬件平臺(tái)參數(shù)指標(biāo)見(jiàn)本文第3部分),實(shí)驗(yàn)使用的DNA、蛋白質(zhì)結(jié)構(gòu)數(shù)據(jù)來(lái)自參考文獻(xiàn)[9]編號(hào)為2GLI的文件。其他的DNA、蛋白質(zhì)結(jié)構(gòu)數(shù)據(jù)的實(shí)驗(yàn)結(jié)果也顯示了計(jì)算能量所耗費(fèi)的時(shí)間遠(yuǎn)超過(guò)其他兩個(gè)部分。計(jì)算能量時(shí),DNA-蛋白質(zhì)組合體所處的三維空間被劃分成若干個(gè)棱長(zhǎng)為埃米(10-10 m)級(jí)的晶格。一條DNA鏈由若干個(gè)DNA原子構(gòu)成,一條蛋白質(zhì)鏈由若干個(gè)蛋白質(zhì)原子構(gòu)成;以2GLI組合體為例,共有855個(gè)DNA原子和1 270個(gè)蛋白質(zhì)原子。每次平移和旋轉(zhuǎn)前后,每個(gè)原子所屬的晶格都可能發(fā)生改變,每個(gè)晶格所包含的原子個(gè)數(shù)也可能發(fā)生改變。Di(i=1,2,…,ND),Pj(j=1,2,…,NP)分別代表組合體中的DNA原子數(shù)量和蛋白質(zhì)原子數(shù)量。DNA原子i(i=1,2,…,ND)在三維空間中所處的晶格和相鄰的晶格共有27個(gè),統(tǒng)稱(chēng)為原子i的臨近晶格(Neighboring Lattice),以pi,j(x,1,2,…,ni)代表這27個(gè)晶格中的所有蛋白質(zhì)原子,這些原子即原子i的相鄰蛋白質(zhì)原子。以di,j代表DNA原子i與蛋白質(zhì)原子jx之間的歐式距離,兩個(gè)原子之間的能量是di,j的函數(shù):E(di,j)。則組合體的總能量為:
通過(guò)累加各線程的能量部分和可以得到組合體的總能量。另外,如果B<ND,則需要把ND個(gè)DNA原子平均分成「ND/B?骎塊(最后一塊可能不足B個(gè)原子),然后,由整個(gè)block的線程依次處理各塊,算法2第3行的循環(huán)結(jié)構(gòu)即為了達(dá)到這個(gè)目的。
2.3 優(yōu)化并行算法
考慮到本文1.2節(jié)所述warp的執(zhí)行特點(diǎn),上述并行方式存在一定的不足。算法2中第7行的循環(huán)次數(shù)取決于當(dāng)前晶格中蛋白質(zhì)原子的個(gè)數(shù),同一warp中各線程的循環(huán)次數(shù)可能會(huì)不同,如果差異過(guò)大,會(huì)造成嚴(yán)重的計(jì)算資源閑置;對(duì)所有線程而言,算法2第3行、第6行循環(huán)結(jié)構(gòu)的循環(huán)次數(shù)是確定的。
假設(shè)DNA存儲(chǔ)在一個(gè)數(shù)組中,且該數(shù)組位于GPU主存(global memory)中。為了盡量減少計(jì)算資源閑置,重排DNA原子的原有次序(DNA鏈中的次序),處于同一個(gè)晶格中的DNA原子被存儲(chǔ)在數(shù)組的某一段連續(xù)區(qū)域內(nèi)。采用這種優(yōu)化措施是基于以下原因:(1)由式(1)可知,總能量由E(di,j)做算術(shù)加法得到,與E(di,j)的計(jì)算次序無(wú)關(guān);(2)為了提高GPU主存的帶寬利用率,同一warp中的線程通常從主存中的臨近區(qū)域讀取數(shù)據(jù),即內(nèi)存訪問(wèn)對(duì)齊(coalescing)[6];(3)DNA的雙螺旋結(jié)構(gòu)是非線性的,DNA在鏈中相鄰的原子未必處于同一晶格中;(4)同一晶格中的DNA原子的臨近蛋白質(zhì)原子數(shù)量相同,重排可以減少因線程執(zhí)行路徑差異造成的計(jì)算資源閑置。重排的效果如圖3所示。
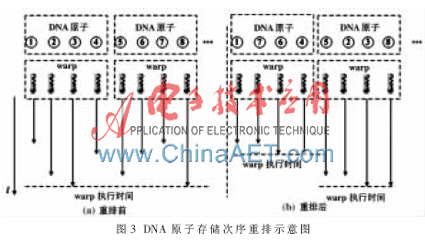
3 實(shí)驗(yàn)
3.1 實(shí)驗(yàn)平臺(tái)
硬件平臺(tái):Intel CoreTM2 E7500 CPU,2.93 GHz,NVIDIA GTX 660圖形處理器(單個(gè)warp包含 32個(gè)線程),CPU主存4 GB。
軟件平臺(tái):Linux操作系統(tǒng)內(nèi)核版本2.6.18-194.el5,gcc版本4.1.2,CUDA版本5.0。
3.2 實(shí)驗(yàn)參數(shù)設(shè)置與結(jié)果
DNA-蛋白質(zhì)結(jié)構(gòu)數(shù)據(jù)編號(hào)為2GLI。CPU版程序以單線程串行方式執(zhí)行;GPU版程序block size固定為512;各block從不同的初始種子出發(fā),分別基于退火算法進(jìn)行搜索,每個(gè)block對(duì)應(yīng)一個(gè)初始種子。退火算法參數(shù):初始溫度T0=120℃,最低溫度Tmin=0.001℃,溫度衰減周期interval=800,溫度衰減系數(shù)a=0.99,最大平移旋轉(zhuǎn)次數(shù)Smax=106。
實(shí)驗(yàn)結(jié)果如表1所示。與單線程CPU程序相比,未經(jīng)優(yōu)化的GPU程序?qū)@得最高可達(dá)8倍左右的加速比;而經(jīng)過(guò)重排優(yōu)化后,加速比在此基礎(chǔ)上進(jìn)一步顯著提升,最高可達(dá)15倍左右。
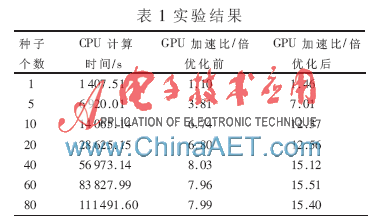
本文針對(duì)一種典型的DNA-蛋白質(zhì)匹配算法,設(shè)計(jì)實(shí)現(xiàn)了基于CUDA的并行化方法,從線程調(diào)度的角度對(duì)該方法進(jìn)行優(yōu)化,并通過(guò)實(shí)驗(yàn)驗(yàn)證了加速性能。實(shí)際應(yīng)用往往需要為一個(gè)組合體產(chǎn)生大量的初始種子(數(shù)百個(gè)),并為每個(gè)種子開(kāi)啟一個(gè)基于退火算法的搜索過(guò)程;其目的是達(dá)到較高的匹配精度。實(shí)驗(yàn)顯示,使用單個(gè)GPGPU加速,在單個(gè)block包含的線程數(shù)不變的前提下,隨著初始種子數(shù)量的增加,加速比逐漸趨于穩(wěn)定。例如,當(dāng)初始種子個(gè)數(shù)超過(guò)40后,加速比基本穩(wěn)定在15倍左右。其原因在于單個(gè)GPGPU的計(jì)算能力存在上限,當(dāng)種子足夠多時(shí),其計(jì)算能力已得到較充分利用,無(wú)法繼續(xù)提高加速比。為了滿(mǎn)足實(shí)際應(yīng)用的需求,下一步的工作將考慮使用基于GPGPU的集群來(lái)加速匹配算法,以進(jìn)一步提高加速比。
參考文獻(xiàn)
[1] BOURNE P E,WEISSIG H. Structural bioinformatics[M]. Hoboken: Wiley-Liss Inc, 2003.
[2] Liu Zhijie, Guo Juntao, Li Ting, et al. Structure-based prediction of transcription factor binding sites using a protein-DNA docking approach[J]. Proteins, 2008,72(4):1114-1124.
[3] 戴東波,熊赟,朱揚(yáng)勇.基于參考集索引的高效序列相似性查找算法[J].軟件學(xué)報(bào),2011(4):718-731.
[4] Zhang Zhang, Xiao Jingfa, Wu Jiayan, et al. ParaAT: A parallel tool for constructing multiple protein-coding DNA alignments[J]. Biochemical Biophysical Research Communications, 2012,419(4):779-781.
[5] 徐新海,楊學(xué)軍,林宇斐,等.一種面向CPU-GPU異構(gòu)系統(tǒng)的容錯(cuò)方法[J].軟件學(xué)報(bào),2011,22(10):2538-2552.
[6] NVIDIA Cooperation.CUDA programming guide version 5.0[EB/OL].[2013-05-15].http://docs.nvidia.com/cuda/cudac-programming-guide/.
[7] TIANYI D H,TAREK S A. Reducing branch divergence in GPU programs[A]. In Proceedings of the Fourth Workshop on General Purpose Processing on Graphics Processing Units[C]. London: ACM.2012.
[8] IMEN C, AHCENE B, NOUREDINE M. Reducing thread divergence in GPU-based b&b applied to the flow-shop problem[A]. In Proceedings of the 9th International Conference on Parallel[C]. Berlin: Springer-Verlag.2011.
[9] Rutgers and UCSD. Protein Data Bank [DB/OL].[2009-02-24].http://www.rcsb.org/pdb/explore/explore.do?structureId=2gli.
[10] GENE A. Validity of the single processor approach to achieving large-scale computing capabilities[A]. In Proceedings of the April 18-20(AFIPS′67)[C]. New York:ACM.1967.