
基于H.323高性能MCU的設(shè)計(jì)與實(shí)現(xiàn)
摘要: 針對基于H.323協(xié)議的Openh323開源視頻會議系統(tǒng)中源MCU容納終端有限,圖像質(zhì)量差等缺陷,在VC++6.0開發(fā)平臺上,采用基于幀緩沖映射軟交換技術(shù)改進(jìn)源碼中的MCU,提高其存儲轉(zhuǎn)發(fā)的能力,從而增加參與視頻會議的終端;在占用較少CPU資源的同時,有效提高其傳輸速率,并縮短了傳輸時延,取得了良好的測試結(jié)果。
Abstract:
Key words :
摘要:針對基于H.323協(xié)議的Openh323開源視頻會議系統(tǒng)中源MCU容納終端有限,圖像質(zhì)量差等缺陷,在VC++6.0開發(fā)平臺上,采用基于幀緩沖映射軟交換技術(shù)改進(jìn)源碼中的MCU,提高其存儲轉(zhuǎn)發(fā)的能力,從而增加參與視頻會議的終端;在占用較少CPU資源的同時,有效提高其傳輸速率,并縮短了傳輸時延,取得了良好的測試結(jié)果。
隨著計(jì)算機(jī)的硬件,特別是CPU主頻的不斷提升,基于軟件的音、視頻編碼效率也越來越高,因此考慮到成本與各方面的因素,軟件MCU必然成為以后的主流方向。但現(xiàn)今大多的MCU都是軟硬件相結(jié)合,純軟件的MCU很少且效率不高。
當(dāng)前H.323視頻會議系統(tǒng)大都是以O(shè)penh323協(xié)議庫為基礎(chǔ)開發(fā)的視頻和語音傳輸系統(tǒng)軟件。Openh323是由澳大利亞Equivalence Pty Ltd.公司組織開發(fā)的,能實(shí)現(xiàn)基本的H.323協(xié)議框架,在Openh323 V4中,基于視頻緩存池的MCU最多只能處理合成4路終端,不能適應(yīng)現(xiàn)今市場發(fā)展的需要,因此重新設(shè)計(jì)MCU的架構(gòu),便成為研發(fā)軟件MCU的關(guān)鍵。
l 源MCU的缺陷和不足
(1)OpenH323中源MCU只能形成不超過4個終端畫面的圖像。其中,4×1為CIF格式(352×288);l×1為QCIF格式(176×144),因此視頻混合存在兩種不同方式,包括QCIF格式源圖像混合成CIF格式圖像以及CIF格式源圖像混合成CIF格式圖像,如圖1所示。
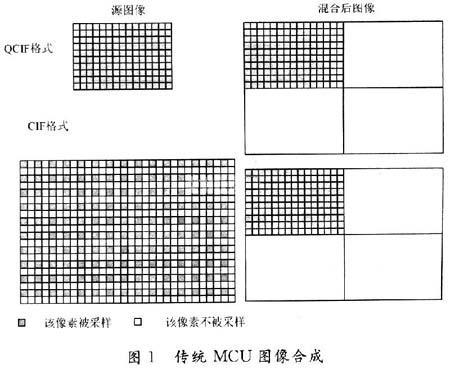
當(dāng)源圖像為QCIF格式時,源圖像大小正好是混合后圖像大小的1/4,這時可以將源圖像整幅地拷貝到混合圖像的相應(yīng)位置;當(dāng)源圖像為CIF格式時,源圖像與混合后圖像的大小一樣,因此源圖像3/4的像素必須被丟掉,采用的方法是:對源圖像在水平方向進(jìn)行隔點(diǎn)采樣,在垂直方向進(jìn)行隔行采樣。這樣處理之后,源圖像大小也正好是混合后圖像大小的1/4,雖然圖像的分辨率已經(jīng)下降,但是保持了源圖像畫面的完整性;如果將MCU變成可容納16個終端的顯示畫面,在將QCIF源圖像轉(zhuǎn)換為CIF的合成圖像過程中,只能將源圖像的采樣點(diǎn)按倍數(shù)減少。也就是將CIF格式等分為16份,相當(dāng)于用88×72的像素點(diǎn)去存儲176×144 QCIF圖像,合成圖像顯示的像素點(diǎn)只有源圖像的1/4;如果將MCU可容納的終端數(shù)目擴(kuò)大為32,甚至更多時,圖像的清晰度將大打折扣。
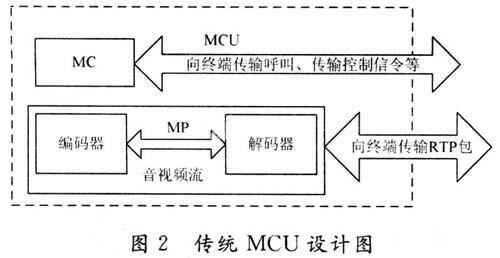
(2)傳統(tǒng)軟件MCU的架構(gòu)是從硬件MCU繼承過來的,MCU包括MC和MP部分。MC部分對終端進(jìn)行連接控制以及邏輯通道的管理;MP部分對音頻進(jìn)行混合,視頻進(jìn)行合成。傳統(tǒng)MCU的設(shè)計(jì)如圖2所示,這種架構(gòu)適用于硬件MCU;但對用軟件實(shí)現(xiàn)的MCU并不太適合。用軟件實(shí)現(xiàn)的MCU的編解碼都是通過CPU來運(yùn)算的,這樣必然增加CPU的運(yùn)算負(fù)荷。例如:要編碼一路30 f/s的CIF(352×288)圖像,大概編碼后的字節(jié)數(shù)為30×352×288×2=6 MB,CPU要處理如此大的視頻數(shù)據(jù)量,經(jīng)測試,P4-2.6 G的CPU在這種架構(gòu)下,最多支持5路終端,如超過5路,CPU運(yùn)算負(fù)荷過大,其資源基本耗盡,圖像合成的效果嚴(yán)重下降。
因此,要實(shí)現(xiàn)高性能的MCU,必須把MCU對多路音、視頻編碼的大數(shù)據(jù)量處理的工作環(huán)節(jié)轉(zhuǎn)移到各個終端上,讓終端對相應(yīng)的音、視頻編碼進(jìn)行處理,而MCU只對各路的音視頻流進(jìn)行存儲轉(zhuǎn)發(fā),這樣才能減輕MCU的負(fù)荷,從而提高系統(tǒng)的整體效率。
2 幀緩沖映射的軟交換模式的MCU的設(shè)計(jì)
綜上所述,在此提出采用基于幀緩沖映射軟交換的 MCU系統(tǒng)設(shè)計(jì)模式,所謂的軟交換模式就是仿照交換機(jī)的模式,不對音、視頻流進(jìn)行編解碼的處理,只對數(shù)據(jù)進(jìn)行轉(zhuǎn)發(fā)與控制。
該MCU也包括MC與MP。基于軟交換的MP,通過幀緩沖映射算法,查找終端對應(yīng)的緩沖區(qū),然后到把接收到的音、視頻流存放到該緩沖區(qū)里面,通過MC控制,把音、視頻數(shù)據(jù)流轉(zhuǎn)發(fā)到終端。
2.1 MC部分總體設(shè)計(jì)思想
MC部分的設(shè)計(jì)主要包括會議組管理、會議RTP流轉(zhuǎn)發(fā)管理。
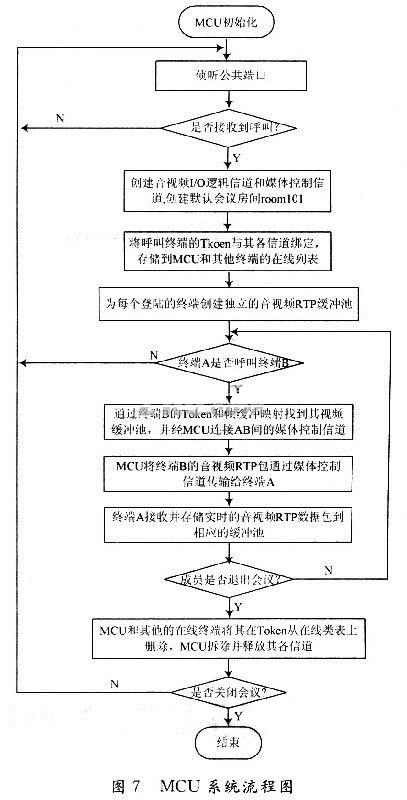
(1)會議管理。該系統(tǒng)只默認(rèn)一組會議,且默認(rèn)的會議房間為“rooml01”。對一組會議來說,主要管理會議的成員信息,處理與會者的加入與退出等。為了實(shí)現(xiàn)這些功能,建立一個會議組類、成員信息類、成員狀態(tài)類、成員身份類和成員視頻緩沖類。會議組類主要記錄終端所選的會議ID;成員信息類主要記錄終端的Token,IP地址等信息;成員類狀態(tài)主要記錄成員是否在線;成員身份類可以確定是主席,還是聽眾;成員視頻緩沖類主要是存放在線各個終端的RTP包,一個緩沖類里面可以存在多個緩沖區(qū)。MC首先通過設(shè)定TCP特定的端口,并在端口上建立一個TCP*線程,終端通過這個端口與MCU進(jìn)行TCP連接,并由MC建立一個H.225呼叫線程,用于*H.225呼叫信令,通過這個H.225通道,終端把自己的會議組ID,IP,Token等身份認(rèn)證注冊到MC。
圖3為MC的會議管理系統(tǒng)框圖。

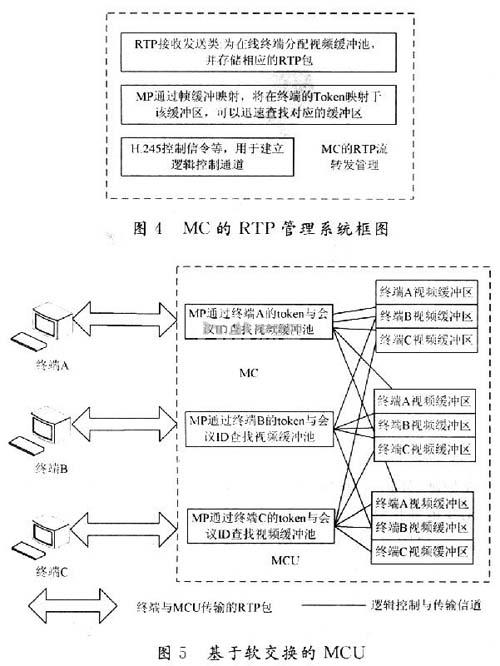
(2)會議RTP流轉(zhuǎn)發(fā)管理。MCU對登陸終端進(jìn)行注冊后,MC建立一個H.245控制信令線程,并與該終端進(jìn)行連接控制,通過H.245控制信令與Mc進(jìn)行呼叫、信令處理與能力協(xié)商、主從決定;然后建立音、視頻的接收邏輯通道,通過RTP接收類開始接收終端發(fā)送的RTP幀。把RTP幀保存到分配給該終端緩存區(qū)里。MC為已經(jīng)進(jìn)行了呼叫連接的終端分配了一一對應(yīng)的視頻緩沖接收區(qū).該緩沖區(qū)是一個分配在堆里面的數(shù)據(jù)結(jié)構(gòu),例如:在終端A的在線人員列表上,可以看到登陸注冊到MCU的人員名單;通過對終端的人員名單的選擇,例如選擇B,那么終端A可以要求MC轉(zhuǎn)發(fā)終端B的音、視頻,當(dāng)MC收到終端A提交的要求轉(zhuǎn)發(fā)終端B的信息后,在MC的A終端緩沖池里面,為終端B新建一個緩沖區(qū),通過MP對終端B的Token的幀緩沖映射查找到終端B的音視頻緩沖池,并在終端A與終端B之間建立一條邏輯通道,用于向終端A傳輸終端B的RTP包,當(dāng)MC的終端A緩沖類接收到終端B的RTP包后,把RTP包拷貝到原來的接收緩沖區(qū)里;然后同樣把終端B的惟一Token通過哈希函數(shù)映射到這個緩沖區(qū)上。
圖4為MC的RTP管理系統(tǒng)框圖。MC的軟交換模式如圖5所示。
2.2 MP部分總體設(shè)計(jì)思想
基于軟交換的MP,通過幀緩沖映射算法查找終端對應(yīng)的緩沖區(qū),然后把接收到的音、視頻流存放到該緩沖區(qū)里面,通過MC的控制,把音、視頻數(shù)據(jù)流轉(zhuǎn)發(fā)到終端。由于MCU需要處理大量的實(shí)時RTP包,效率成為了最主要的問題。因此如何從緩沖區(qū)里面快速搜索相應(yīng)的數(shù)據(jù)包是MP能否快速處理數(shù)據(jù)的關(guān)鍵。考慮到MP要處理不同的終端,不同的終端對應(yīng)不同的緩沖區(qū),所以采用哈希函數(shù)映射法,它將任意長度的二進(jìn)制值映射為固定長度的較小二進(jìn)制值,并把這個哈希表存放到相應(yīng)的內(nèi)存區(qū),以便多次的查找,這樣通過這個較小的二進(jìn)制值就可以以非常快的速度找到比較大的數(shù)值。因此把視頻緩沖區(qū)的首地址存放到一個哈希表里面,并通過這個哈希表把終端的Token映射于這個緩沖區(qū),這樣通過終端的惟一TOken便可以迅速找到其對應(yīng)的緩沖區(qū)。
實(shí)現(xiàn)MP部分幀緩沖映射算法的具體設(shè)計(jì)步驟是:首先MCU把登陸的在線終端Token(終端的惟一標(biāo)識)與會議ID默認(rèn)為roomlol,通過哈希函數(shù),映射到一個緩沖區(qū),通過終端的Token和會議ID,就可以直接找到本終端的緩沖區(qū),當(dāng)MP收到終端的RTP包后,通過RTP包的邊界分析,把多個RTP合成一個數(shù)據(jù)幀,然后把數(shù)據(jù)幀放到相應(yīng)的終端緩沖區(qū)里面。幀緩沖映射的查找如圖6所示。假設(shè)當(dāng)終端A要求轉(zhuǎn)發(fā)終端B的音、視頻數(shù)據(jù)流時,MP通過哈希函數(shù)找到相應(yīng)終端B的緩沖區(qū)域,然后把該緩沖區(qū)的數(shù)據(jù)讀出到數(shù)據(jù)幀里面,最后通過RTP包進(jìn)行發(fā)送到終端A,而終端A在接收到MCU發(fā)送的終端B的音視頻數(shù)據(jù)壓縮包后,再對其進(jìn)行音視頻進(jìn)行解碼。

2.3 MCU系統(tǒng)實(shí)現(xiàn)
根據(jù)以上的設(shè)計(jì)思想,得出如圖7所示的MCU系統(tǒng)流程圖。
2.4 測試結(jié)果與結(jié)論
通過重新設(shè)計(jì)MCU的MC和MP后,MCU的性能有了較大的提高。從性能方面進(jìn)行測試,由于傳統(tǒng)的MCU在MC上進(jìn)行編解碼,只能容納4路音、視頻終端,而通過修改的MCU,MC沒有進(jìn)行編解碼,只對音、視頻進(jìn)行存儲轉(zhuǎn)發(fā),因此在9路音、視頻的情況下,系統(tǒng)的CPU只占有5%。從效率、質(zhì)量方面進(jìn)行比較,由于傳統(tǒng)的MCU進(jìn)行了4路編解碼,返回到終端的數(shù)據(jù)包延遲比較大,而修改過的MCU沒有進(jìn)行到編解碼,因此數(shù)據(jù)包的延時很小。傳統(tǒng)的MCU在MC里面進(jìn)行圖像的混合,圖像的分辨率變?yōu)樵瓉淼?/4,因此圖像質(zhì)量有較大的下降,而基于軟交換的MCU保持了原來圖像的分辨率,因此圖像質(zhì)量較好。從視頻的幀數(shù)來比較,傳統(tǒng)的MCU架構(gòu)不能達(dá)到15 f/s,而基于軟交換的MCU能達(dá)到30 f/s。由于基于軟交換的MCU的視頻傳輸?shù)氖窃瓉韴D像的分辨率,因此傳輸率比傳統(tǒng)的MCU要高,但可以通過在終端采用傳輸率較低的編碼器來降低傳輸率。表1為MCU改進(jìn)前與改進(jìn)后的對比。
終端的6分界面如圖8所示。

3 結(jié)語
從以上的測試證明,基于軟交換的MCU架構(gòu),使MCU的性能有了很大的提高。本文同時也說明了只要系統(tǒng)程序設(shè)計(jì)合理,基于軟件的MCU是切實(shí)可行的。隨著硬件水平的不斷提高,純軟件的MCU將以其低成本、簡易操作而普及到低端用戶。
此內(nèi)容為AET網(wǎng)站原創(chuàng),未經(jīng)授權(quán)禁止轉(zhuǎn)載。