
文獻(xiàn)標(biāo)識(shí)碼: A
文章編號(hào): 0258-7998(2013)10-0136-03
隨著高分辨率、高頻幀的CCD相機(jī)在航測(cè)中的廣泛使用,如何對(duì)產(chǎn)生的高速圖像數(shù)據(jù)進(jìn)行實(shí)時(shí)記錄,成為了一個(gè)技術(shù)難題。光纖通信具有帶寬高、價(jià)格低廉、傳輸距離長(zhǎng)等優(yōu)點(diǎn),單根光纖的傳輸帶寬達(dá)到10.2 Tb/s。大量光電轉(zhuǎn)換模塊的出現(xiàn),使光纖在高速圖像采集傳輸系統(tǒng)中大量使用,常規(guī)光模塊帶寬達(dá)到2 Gb/s,而傳統(tǒng)通過PCI總線與主機(jī)通信的理論帶寬只有133 MB/s,但當(dāng)實(shí)際數(shù)據(jù)采集速度到達(dá)100 MB/s左右時(shí)就變得相當(dāng)困難 ,難以滿足對(duì)記錄帶寬的要求。PCIE是繼PCI后的第三代高性能I/O總線,與PCI相比,PCIE屬于串行總線,引腳少,采用基于數(shù)據(jù)包的協(xié)議進(jìn)行事務(wù)編碼,每個(gè)傳輸通道獨(dú)享帶寬;硬件接口簡(jiǎn)單,采用點(diǎn)對(duì)點(diǎn)互聯(lián),X1的單向傳輸理論帶寬即可達(dá)到2.5 Gb/s,用戶可以根據(jù)實(shí)際需要將PCIE鏈路配置為X1、X2、X4、X8、X16等。
PCIE數(shù)據(jù)包在傳輸過程中要經(jīng)過事務(wù)層,數(shù)據(jù)鏈路層及物理層。采用類似網(wǎng)絡(luò)分層的思想,不同之處在于PCIE體系中的各個(gè)層都是采用硬件邏輯來(lái)實(shí)現(xiàn)。事務(wù)層是PCIE架構(gòu)的上層,其主要功能是接收、緩沖和分發(fā)事務(wù)包TLP(Transaction Layer Packet)。TLP通過使用I/O、存儲(chǔ)器 、配置和消息事務(wù)來(lái)傳遞信息。數(shù)據(jù)鏈路層是保證可靠正確的數(shù)據(jù)傳輸,主要負(fù)責(zé)鏈路管理與數(shù)據(jù)完整性相關(guān)的功能,包括錯(cuò)誤檢測(cè)與改正,裝配和拆解數(shù)據(jù)鏈路層包DLLP。物理層是PCIE協(xié)議的最底層,為設(shè)備鏈路提供物理支持,分為邏輯子塊和電氣子塊。邏輯子塊完成對(duì)數(shù)據(jù)包的合成分解、加擾和去擾、8 bit/10 bit編碼和10 bit/8 bit解碼、并串轉(zhuǎn)換和串并轉(zhuǎn)換;電氣物理層負(fù)責(zé)對(duì)每路串行數(shù)據(jù)差分驅(qū)動(dòng)的傳輸與接收及阻抗匹配[1-2]。
1 采集系統(tǒng)簡(jiǎn)述
本文采用CCD相機(jī)的分辨率為2 352×1 728,灰度級(jí)別為8 bit,幀頻為31 F/s,產(chǎn)生的數(shù)據(jù)量為120.2 MB/s,則PCIE接口采用X1通道就可以滿足帶寬需要。采集系統(tǒng)的具體結(jié)構(gòu)如圖1所示。
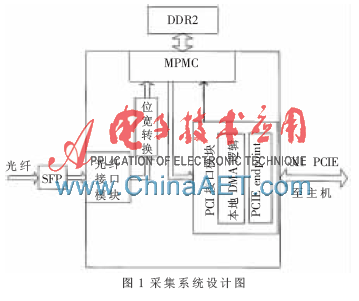
XC5VFX70T是Xilinx公司VIRTEX系列的一款具有5 328 KB RAM資源、內(nèi)嵌3個(gè)PCIE硬核和16個(gè)可配置的高速串行收發(fā)器GTX,速率可達(dá)6.5 Gb/s,采用CML電平標(biāo)準(zhǔn),在系統(tǒng)中和SFP模塊無(wú)縫連接。該芯片在系統(tǒng)中主要實(shí)現(xiàn)高速數(shù)據(jù)的接收和緩存,以及數(shù)據(jù)的實(shí)時(shí)采集[3-4]。
光纖信號(hào)通過光纖接口模塊和位寬轉(zhuǎn)換,數(shù)據(jù)被寫入DDR2中,DDR2分為A、B兩個(gè)獨(dú)立的存儲(chǔ)區(qū)。當(dāng)A儲(chǔ)存區(qū)寫滿時(shí),將數(shù)據(jù)寫入PCIE接口模塊的TX_FIFO中,這時(shí)DMA控制器發(fā)送中斷給主機(jī),主機(jī)會(huì)準(zhǔn)備好接收緩存區(qū),并將緩存區(qū)首地址告知DMA控制器,開始DMA傳輸,將數(shù)據(jù)寫入到主機(jī)內(nèi)存中,同時(shí)將采集的數(shù)據(jù)寫入B存儲(chǔ)區(qū)中。同理,當(dāng)B存儲(chǔ)區(qū)中的數(shù)據(jù)被寫滿時(shí),也通過同樣的方式寫入主機(jī)的內(nèi)存中。主機(jī)內(nèi)存中的數(shù)據(jù)通過SATA總線被寫到SATA硬盤并記錄下來(lái)。DDR2采用交叉緩存工作,以保證高速數(shù)據(jù)流的不間斷采集。
2 功能模塊設(shè)計(jì)
2.1光纖接口模塊邏輯設(shè)計(jì)
光纖接口模塊分為GTX和包數(shù)據(jù)解析兩個(gè)部分。光纖信號(hào)經(jīng)GTX核后,輸出16 bit位寬的并行數(shù)據(jù)和相應(yīng)的K字符信號(hào)。根據(jù)K字符信號(hào)提取數(shù)據(jù)包。包數(shù)據(jù)解析根據(jù)自定義的協(xié)議進(jìn)行數(shù)據(jù)包解析,得到幀頭標(biāo)志、幀尾標(biāo)志、有效圖像數(shù)據(jù)和附加信息等。附加信息是一組固定長(zhǎng)度的雙字組合,含有圖像相關(guān)的一些信息,如大小、位數(shù)、編碼方式等[5-6]。圖2所示為自定義協(xié)議包。

包頭和包尾作為數(shù)據(jù)包的起始和結(jié)尾標(biāo)志,包長(zhǎng)用于指示發(fā)送數(shù)據(jù)的有效長(zhǎng)度,包累加和用于包內(nèi)有效數(shù)據(jù)字節(jié)的統(tǒng)計(jì),包編號(hào)用于統(tǒng)計(jì)發(fā)送的數(shù)據(jù)包有無(wú)丟失。幀頭標(biāo)志、幀尾標(biāo)志、有效圖像數(shù)據(jù)和附加信息等則放在有效數(shù)據(jù)中。
2.2 緩存模塊
本文的DDR2控制器MPMC采用NPI接口,設(shè)計(jì)有2個(gè)NPI接口分別用于讀寫操作。一個(gè)是用于存儲(chǔ)光纖的輸入數(shù)據(jù),另一個(gè)用于輸出內(nèi)存數(shù)據(jù)到PCIE接口。這樣可以避免傳輸過程中內(nèi)存的訪問仲裁,提高系統(tǒng)的傳輸效率。
本文光纖接口模塊輸出的數(shù)據(jù)寬度為16 bit,而采用的NPI接口的數(shù)據(jù)寬度為64 bit。所以需要對(duì)原始數(shù)據(jù)進(jìn)行位寬轉(zhuǎn)換后才能進(jìn)行后續(xù)處理。位寬轉(zhuǎn)換模塊根據(jù)需要將數(shù)據(jù)寬度從16 bit轉(zhuǎn)換為64 bit。
2.3 PCIE接口模塊設(shè)計(jì)
PCIE接口模塊主要是實(shí)現(xiàn)主機(jī)PCIE總線與采集卡之間的通信。為了實(shí)現(xiàn)基于PCIE的DMA傳輸,需要設(shè)計(jì)以下8個(gè)模塊[7-8], 具體PCIE接口模塊設(shè)計(jì)如圖3所示。

圖3中各個(gè)模塊的作用如下:
(1) PCIE硬核:對(duì)外與其他PCIE設(shè)備通信,對(duì)內(nèi)與TX和RX模塊進(jìn)行數(shù)據(jù)傳輸。
(2) TX模塊:將待發(fā)送的數(shù)據(jù)和DMA寄存器中的信息填充到事務(wù)包TLP中,以并行的方式傳輸給PCIE硬核,實(shí)現(xiàn)PCIE寫操作狀態(tài)。
(3) RX模塊:將接收的事務(wù)包TLP解析,根據(jù)TLPs的包頭信息,將數(shù)據(jù)寫入DMA寄存器。
(4) 緩存:匹配FIFO兩邊不同傳輸速率的數(shù)據(jù)流,緩存待處理的數(shù)據(jù)和提高數(shù)據(jù)的傳輸效率。
(5) DMA控制模塊:DMA寄存器是由發(fā)送寄存器、中斷寄存器等構(gòu)成。發(fā)送寄存器用于接收和存放主機(jī)內(nèi)存寫請(qǐng)求的DMA信息,主要為內(nèi)存寫請(qǐng)求地址寄存器及寫長(zhǎng)度寄存器、寫包數(shù)寄存器。中斷寄存器是存放中斷產(chǎn)生的原因,為辨別何種中斷提供依據(jù)。
(6) 用戶邏輯:一方面用戶邏輯通過DMA控制模塊向主機(jī)發(fā)起DMA傳輸中斷,設(shè)置DMA傳輸?shù)拈L(zhǎng)度;另一方面控制數(shù)據(jù)的輸入,保證TX_FIFO不會(huì)溢出,數(shù)據(jù)不會(huì)丟失。
(7) 用戶接口模塊:提供簡(jiǎn)單的數(shù)據(jù)通道和控制信號(hào)通道。
3 DMA傳輸?shù)倪壿嬙O(shè)計(jì)與實(shí)現(xiàn)
3.1 DMA寫操作的設(shè)計(jì)與實(shí)現(xiàn)
首先用戶邏輯檢測(cè)到TX_FIFO中有需要傳輸?shù)臄?shù)據(jù),這時(shí)用戶邏輯通過DMA控制器發(fā)送MSI中斷,請(qǐng)求DMA傳輸。主機(jī)響應(yīng)中斷,配置DMA寄存器,TX模塊啟動(dòng)DMA傳輸,TX模塊向TLP包加載信息,包括了控制字段、地址字段、數(shù)據(jù)長(zhǎng)度字段以及數(shù)據(jù)字段等。當(dāng)一次DMA傳輸結(jié)束后,向主機(jī)發(fā)送DMA傳輸結(jié)束的中斷,這樣一次完整的DMA寫操作就完成了。具體流程圖如圖4所示,TX模塊和PCIE硬核之間采用64 bit并行傳輸, 在本文中一個(gè)TLP的載荷是128 B,一次DMA操作要進(jìn)行65 536次包傳輸,則一次DMA寫操作就傳輸了8 MB的數(shù)據(jù)量,PCIE寫操作狀態(tài)機(jī)是在TX模塊中實(shí)現(xiàn)。

圖6是DMA控制寄存器的設(shè)計(jì)圖,初始化寄存器的Byte0用于DMA傳輸復(fù)位。1DW的Byte0用于讀開始,Byte1用于讀完成,Byte2用于寫開始,Byte3用于寫完成;2DW用于存放主機(jī)寫入的緩存首地址;3DW用于存放一個(gè)TLP包攜帶的有效數(shù)據(jù)量;4DW用于存放一次每次DMA傳輸發(fā)送的TLP包數(shù)量;5DW的Byte0用于指示FPGA請(qǐng)求DMA傳輸,Byte1用于指示DMA傳輸結(jié)束。

4 功能驗(yàn)證與性能測(cè)試
本文PCIE硬核采用X1通道,最大的理論傳輸帶寬為2.5 Gb/s。使用ChipScope對(duì)DMA寫操作進(jìn)行了驗(yàn)證,具體時(shí)序如圖7所示,trn_td是FPGA向主機(jī)發(fā)送的數(shù)據(jù),trn_tsof_n為低時(shí),表示TLP包的第一個(gè)64 bit數(shù)據(jù);trn_teof_n為低時(shí),表示TLP包的最后64 bit數(shù)據(jù),這時(shí)trn_trem_n為0X0F,則說(shuō)明最后一個(gè)64 bit只有高32位有效。傳輸一個(gè)TLP包大約需要108個(gè)時(shí)鐘周期,采用125 MHz的采樣頻率,一個(gè)TLP包有效載荷為128 B,則可得出在X1的配置下,DMA的傳輸速度大約為141.3 MB/s。
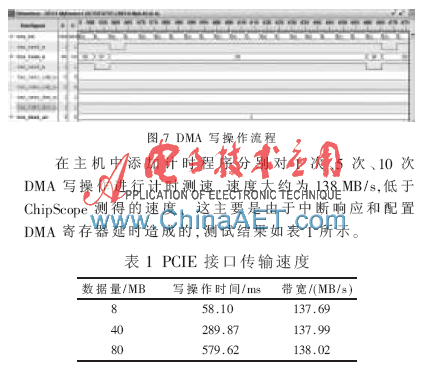
本文針對(duì)高速光纖圖像實(shí)時(shí)采集的需要,設(shè)計(jì)了一種基于PCIE的采集系統(tǒng)。經(jīng)實(shí)際測(cè)試,系統(tǒng)運(yùn)行穩(wěn)定可靠。采用X1的PCIE總線接口,DMA寫操作速度大約為138 MB/s,滿足光纖圖像實(shí)時(shí)記錄的帶寬要求。如果實(shí)際需要更高的采集帶寬,可以參考本文設(shè)計(jì),將PCIE接口設(shè)計(jì)為X4或X8,以實(shí)現(xiàn)更高的采集性能。本設(shè)計(jì)具有通用性,可被移植于其他內(nèi)嵌有PCIE硬核及串行收發(fā)器GTX等資源的 FPGA平臺(tái)。
參考文獻(xiàn)
[1] BUDRUK R, ANDERSON D,SHANLEY T. PCI Express系統(tǒng)體系結(jié)構(gòu)標(biāo)準(zhǔn)教材[M].田玉敏,等譯.北京:電子工業(yè)出版社,2005.
[2] PCI-SIG. PCI express card electromechanical specification Rev 1.0a[Z].USA: PCI-SIG,2003:5-33.
[3] Virtex-5 FPGA RocketIO GTX transceiver v2.1 user guide[Z].USA:Xilinx,2011.
[4] 使用用于PCI Express設(shè)計(jì)的集成端點(diǎn)模塊實(shí)現(xiàn)點(diǎn)到點(diǎn)連接[Z].USA:Xilinx ,2007.
[5] 孫科林,周維超,吳欽章.高速實(shí)時(shí)光纖圖像傳輸系統(tǒng)的實(shí)現(xiàn)[J].光學(xué)精密工程,2011,19(9):2228-2235.
[6] 繆露鵬,涂曉東,張新穎.光纖適配卡數(shù)據(jù)總線的研究與實(shí)現(xiàn)[J].光通信技術(shù),2011(1):8-10.
[7] 汪精華,胡善清,龍騰. 基于FPGA 實(shí)現(xiàn)的高速串行交換模塊實(shí)現(xiàn)方法研究[J].電子技術(shù)應(yīng)用,2010,36(5):37-40.
[8] 何瓊,陳鐵,程鑫. 基于FPGA的DMA方式高數(shù)數(shù)據(jù)采集系統(tǒng)設(shè)計(jì)[J].電子技術(shù)應(yīng)用,2011,37(12):40-43.