
文獻(xiàn)標(biāo)識(shí)碼: A
文章編號: 0258-7998(2013)12-0145-04
隨著CT(X射線)、MR(核磁共振)等醫(yī)學(xué)影像設(shè)備的迅速發(fā)展,拍攝出來的醫(yī)學(xué)影像清晰度顯著提高,但所占空間也明顯增大[1]。與此同時(shí),重大疾病發(fā)生率的增高等因素導(dǎo)致醫(yī)學(xué)影像數(shù)據(jù)量增加迅速。目前,一個(gè)大型醫(yī)院每天將產(chǎn)生50 GB以上的數(shù)據(jù),全院總數(shù)據(jù)量已經(jīng)達(dá)到了30 TB級別,醫(yī)生每天都需要頻繁地讀取影像數(shù)據(jù)來輔助診斷。因此,一個(gè)性能良好的醫(yī)學(xué)影像傳輸及存儲(chǔ)系統(tǒng)顯得格外重要。近年來云計(jì)算技術(shù)正逐步從理論研究走向?qū)嶋H應(yīng)用,作為一種新型的體系架構(gòu),云計(jì)算是一個(gè)充分利用信息資源的平臺(tái)。對于對應(yīng)用平臺(tái)高要求、且資金受限的醫(yī)院來說,云計(jì)算有望為其提供一個(gè)新的解決方案。
1 系統(tǒng)技術(shù)概述
1.1 云計(jì)算
云計(jì)算(Cloud computing)融合了分布式并行計(jì)算、網(wǎng)絡(luò)存儲(chǔ)、負(fù)載均衡等多種傳統(tǒng)計(jì)算機(jī)和網(wǎng)絡(luò)技術(shù),以其獨(dú)特的擴(kuò)展性、廉價(jià)性及容錯(cuò)力受到廣泛關(guān)注。Hadoop是Apache開發(fā)的一個(gè)云計(jì)算的開源平臺(tái),主要包括分布式文件系統(tǒng)(HDFS)和并行計(jì)算框架(MapReduce)。Hadoop集群的規(guī)模少則幾臺(tái),多則可上千臺(tái),其存儲(chǔ)與計(jì)算能力也隨著規(guī)模的擴(kuò)大而穩(wěn)步提高。
HDFS是Hadoop的文件存儲(chǔ)系統(tǒng),適合于大規(guī)模數(shù)據(jù)集上的應(yīng)用。HDFS將一個(gè)大文件分成若干個(gè)數(shù)據(jù)塊,并創(chuàng)建多份復(fù)制保存在多個(gè)數(shù)據(jù)節(jié)點(diǎn)集合中,避免發(fā)生單點(diǎn)故障。因此利用HDFS能使系統(tǒng)實(shí)現(xiàn):大規(guī)模數(shù)據(jù)存儲(chǔ)、高冗余、輕松擴(kuò)容、負(fù)載均衡[2]等功能。
MapReduce是Hadoop在HDFS基礎(chǔ)上的并行計(jì)算框架,為用戶提供方便實(shí)用的并行編程模式,實(shí)現(xiàn)大規(guī)模數(shù)據(jù)的并行計(jì)算。MapReduce的主節(jié)點(diǎn)根據(jù)輸入數(shù)據(jù)的鍵(key),通過映射函數(shù)(Mapper)將輸入數(shù)據(jù)映射給不同的從節(jié)點(diǎn)進(jìn)行并行運(yùn)算,隨后再通過規(guī)約函數(shù)(Reducer)將各個(gè)從節(jié)點(diǎn)的運(yùn)行結(jié)果進(jìn)行歸約合并,形成最終的計(jì)算結(jié)果[3]。
1.2 DICOM概述
數(shù)字影像和通信標(biāo)準(zhǔn)3.0(DICOM3.0)是由美國放射學(xué)會(huì)與美國國家電器制造商協(xié)會(huì)聯(lián)合制定的標(biāo)準(zhǔn),規(guī)定了不同的醫(yī)療影像設(shè)備標(biāo)準(zhǔn)化的數(shù)據(jù)格式,從而使數(shù)字影像更有效率地傳輸和交換。DICOM主要的操作協(xié)議有C_STORE、C_FIND、C_MOVE,分別執(zhí)行存儲(chǔ)、查找與獲取。
2 系統(tǒng)架構(gòu)
目前醫(yī)院采用PACS來進(jìn)行醫(yī)學(xué)影像數(shù)據(jù)存儲(chǔ)與傳輸。數(shù)據(jù)讀寫速度和冗余性、系統(tǒng)擴(kuò)展性、負(fù)載均衡等都是設(shè)計(jì)PACS所要考慮的重要方面。由于當(dāng)前醫(yī)院數(shù)據(jù)全部存儲(chǔ)于光纖存儲(chǔ)局域網(wǎng)絡(luò)(FC-SAN)集中式存儲(chǔ)服務(wù)器中,因此在使用PACS過程中尚存以下問題:(1)數(shù)據(jù)讀寫速度慢。由于資金的限制,醫(yī)院將使用頻率較低的數(shù)據(jù)轉(zhuǎn)移到二級存儲(chǔ)設(shè)備中,導(dǎo)致讀寫效率十分低下。(2)服務(wù)器負(fù)載重。PACS依靠影像中心服務(wù)器和集中式存儲(chǔ)服務(wù)器進(jìn)行數(shù)據(jù)調(diào)度和讀寫,而大量來自工作站的請求對影像中心服務(wù)器的處理器性能和存儲(chǔ)服務(wù)器的讀寫能力帶來極大的考驗(yàn)。(3)計(jì)算能力差。工作站目前只能在單機(jī)環(huán)境下進(jìn)行有限的圖像處理,無法提供大規(guī)模運(yùn)算的服務(wù)。(4)不同醫(yī)院間數(shù)據(jù)難以共享。
2.1 架構(gòu)設(shè)計(jì)
為了解決上述問題,本文設(shè)計(jì)了一種將分布式與集中式存儲(chǔ)相結(jié)合的混合式PACS架構(gòu)。在各醫(yī)院園區(qū)網(wǎng)內(nèi)部搭建Hadoop云集群,利用Hadoop集群的HDFS分布式存儲(chǔ)數(shù)據(jù),采用MapReduce進(jìn)行大規(guī)模數(shù)據(jù)計(jì)算。系統(tǒng)整體示意圖如圖1所示。

系統(tǒng)將所有原有的數(shù)據(jù)移至HDFS,集中式存儲(chǔ)服務(wù)器只保留近期數(shù)據(jù)。而新產(chǎn)生的圖像數(shù)據(jù)同時(shí)保存于集中式存儲(chǔ)服務(wù)器和HDFS中。通過這樣的方式節(jié)省集中式存儲(chǔ)服務(wù)器的空間,解決原二級存儲(chǔ)讀寫速度慢的問題,同時(shí)將數(shù)據(jù)存儲(chǔ)在HDFS中也有利于使用Hadoop的MapReduce框架進(jìn)行并行計(jì)算。在后期系統(tǒng)升級過程中,只需要簡單地增加Hadoop集群的節(jié)點(diǎn)數(shù)目,即可提升系統(tǒng)存儲(chǔ)容量與計(jì)算性能。為了實(shí)現(xiàn)不同醫(yī)療組織間的資源共享,醫(yī)院園區(qū)網(wǎng)可以通過防火墻連接公網(wǎng)。對于來自公網(wǎng)上的工作站的請求,防火墻需要先對其進(jìn)行安全認(rèn)證和訪問控制,只有符合安全規(guī)定的請求才被遞交至影像中心服務(wù)器。
此外,本文開發(fā)了SDCMO組件與WDO組件。作為中間件,它們屏蔽底層操作細(xì)節(jié),為上層的應(yīng)用系統(tǒng)提供統(tǒng)一的圖像寫入、讀取和查詢接口。系統(tǒng)架構(gòu)圖如圖2所示。

2.2 SDCMO組件
由于每個(gè)醫(yī)學(xué)影像文件不大,而HDFS會(huì)為每個(gè)文件分配固定的內(nèi)存空間,因此處理大量的醫(yī)學(xué)影像文件會(huì)造成極大的內(nèi)存開銷[4]。本文采用文件序列化技術(shù)(Sequence File),將儲(chǔ)存于HDFS的每個(gè)DICOM數(shù)據(jù)映射成鍵值對(Key/Value)的形式。其中Key是DICOM數(shù)據(jù)文件名,而Value保存DICOM數(shù)據(jù)內(nèi)容。每個(gè)DICOM數(shù)據(jù)被視為一條記錄,將每一組DICOM圖像合并成一個(gè)包含多條記錄的序列化的文件SDCM(Sequence-DICOM),從而減少文件數(shù)目,節(jié)省內(nèi)存空間,同時(shí)還利用了圖像序列之間的相關(guān)性進(jìn)行無損壓縮。
SDCMO(SDCM Operator)組件提供對SDCM文件操作的方法。主要包括4個(gè)部分:(1)SDCM定位器,負(fù)責(zé)獲取文件位置信息;(2)SDCM寫入器,負(fù)責(zé)向HDFS寫入SDCM數(shù)據(jù);(3)SDCM讀取器,向HDFS讀取SDCM數(shù)據(jù);(4)SDCMO Converter負(fù)責(zé)DICOM與SDCM之間的類型轉(zhuǎn)換。
2.3 WDO組件
為了實(shí)現(xiàn)不同設(shè)備之間數(shù)據(jù)的透明交換與傳輸,本文開發(fā)了適配于DICOM 3.0數(shù)據(jù)標(biāo)準(zhǔn)的WDO(Web DICOM Operator)組件,該組件能夠解析、響應(yīng)和封裝來自HTTP的C_STORE,C_MOVE和C_FIND報(bào)文,使HDFS能夠在接收存儲(chǔ)、獲取、查找請求報(bào)文時(shí)可執(zhí)行相應(yīng)操作[5]。該組件主要包括6個(gè)部分:(1)HTTP請求接收器, 負(fù)責(zé)接收和發(fā)送HTTP報(bào)文;(2)釋義器,負(fù)責(zé)解析HTTP的請求報(bào)文,并將其轉(zhuǎn)換為DICOM 3.0標(biāo)準(zhǔn)的請求;(3)DICOM請求器負(fù)責(zé)發(fā)送和處理DICOM響應(yīng)報(bào)文;(4)STORE封裝器,提供封裝DICOM3.0標(biāo)準(zhǔn)的C_STORE報(bào)文的方法;(5)FIND封裝器,提供封裝DICOM3.0標(biāo)準(zhǔn)的C_FIND報(bào)文的方法;(6)MOVE封裝器,提供封裝DICOM3.0標(biāo)準(zhǔn)的C_MOVE報(bào)文的方法。
2.4 工作流程
2.4.1 圖像寫入流程
考慮到安全問題,只有園區(qū)網(wǎng)內(nèi)的影像設(shè)備和內(nèi)部工作站有寫入權(quán)限。而對于來自公網(wǎng)的外部工作站無權(quán)對HDFS和FC-SAN進(jìn)行寫入操作。圖像寫入流程如下:
(1)工作站向影像中心服務(wù)器發(fā)送寫入請求(C_STORE)
報(bào)文;
(2)影像中心服務(wù)器根據(jù)業(yè)務(wù)需求的不同選擇文件存儲(chǔ)位置,并修改索引表。若要存儲(chǔ)到HDFS,則執(zhí)行步驟(3)、步驟(4),若存儲(chǔ)到FC-SAN則執(zhí)行步驟(5);
(3)Hadoop名稱節(jié)點(diǎn)創(chuàng)建文件,分配存放數(shù)據(jù)各分塊的數(shù)據(jù)節(jié)點(diǎn)列表;
(4)調(diào)用SDCMO組件中的數(shù)據(jù)轉(zhuǎn)換器,將DICOM文件轉(zhuǎn)換為SDCM類型,并調(diào)用SDCMO組件中的文件寫入器,將文件寫入HDFS的數(shù)據(jù)節(jié)點(diǎn)中,返回寫入成功信息,寫入過程結(jié)束。
(5)直接寫入FC-SAN,寫入過程結(jié)束。
對于需要從FC-SAN遷移備份至HDFS的數(shù)據(jù),需遞歸地遍歷源文件夾下的所有子文件夾,不斷執(zhí)行步驟(3)、步驟(4)執(zhí)行寫入,完成數(shù)據(jù)遷移。文件寫入流程圖如圖3所示。

2.4.2 讀取/查詢流程
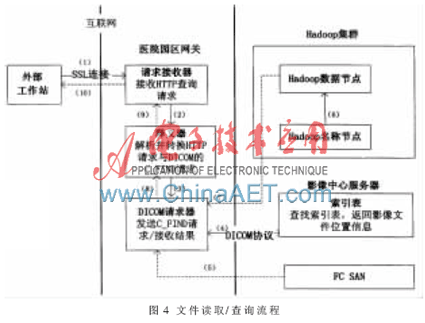
文件讀取/查詢流程如下:
(1)來自公網(wǎng)的外部工作站與醫(yī)院園區(qū)網(wǎng)關(guān)建立SSL連接,發(fā)出查詢請求。
(2)網(wǎng)關(guān)的請求接收器與外部建立合法的SSL
連接,接收HTTP請求。
(3)網(wǎng)關(guān)的釋義器將HTTP請求轉(zhuǎn)化為DICOM3.0標(biāo)準(zhǔn)的C_FIND報(bào)文。
(4)DICOM請求器將C_FIND報(bào)文發(fā)送給影像中心服務(wù)器,影像中心服務(wù)器接收C_FIND請求,查找索引表中文件的位置信息。根據(jù)文件位置的不同跳至步驟(5)或步驟(6)。
(5)接收來自FC-SAN的數(shù)據(jù),跳至步驟(8)。
(6)接收來自HDFS的數(shù)據(jù)名稱節(jié)點(diǎn)根據(jù)元數(shù)據(jù),調(diào)度文件分塊所在的數(shù)據(jù)節(jié)點(diǎn)。
(7)根據(jù)名稱節(jié)點(diǎn)中元數(shù)據(jù)的分塊信息,利用SDCMO組件中的文件讀取器得到SDCM數(shù)據(jù),使用SDCMO組件中的數(shù)據(jù)轉(zhuǎn)換器將SDCM數(shù)據(jù)轉(zhuǎn)換為DICOM數(shù)據(jù),并調(diào)用WDO組件中C_FIND報(bào)文的封裝接口FIND,將DICOM數(shù)據(jù)封裝為DICOM的響應(yīng)報(bào)文。
(8)釋義器將響應(yīng)報(bào)文轉(zhuǎn)為HTTP報(bào)文。
(9)將HTTP報(bào)文發(fā)送給HTTP請求器。
(10)請求接收器將HTTP報(bào)文通過SSL連接發(fā)送給外部工作站,讀取過程結(jié)束。
對于來自局域網(wǎng)的內(nèi)部工作站的請求,由于其已在局域網(wǎng)環(huán)境中,且請求報(bào)文已經(jīng)是DICOM3.0格式,只需直接將請求發(fā)送給DICOM請求器,并從步驟(4)開始執(zhí)行即可。文件讀取/查詢流程如圖4所示。
2.4.3 圖像檢索流程
當(dāng)工作站需要執(zhí)行圖像檢索等大規(guī)模運(yùn)算時(shí),執(zhí)行流程與圖4大體一致,在步驟(4)的過程中還需要利用MapReduce進(jìn)行特征計(jì)算、匹配以獲取檢索結(jié)果。
3 實(shí)驗(yàn)測試
3.1系統(tǒng)配置
在實(shí)驗(yàn)環(huán)境中,采用Hadoop集群為基本配置,其中1臺(tái)作為HDFS的名稱節(jié)點(diǎn)兼MapReduce的主節(jié)點(diǎn),4臺(tái)為HDFS的數(shù)據(jù)節(jié)點(diǎn)兼MapReduce的從節(jié)點(diǎn)。集群工作站配置一致,使用Intel(R) Core(TM) i3-2310M的CPU,內(nèi)存2 GB,硬盤500 GB,并在Ubuntu操作系統(tǒng)上搭建Hadoop-1.1.2。
3.2 實(shí)驗(yàn)結(jié)果分析
(1)寫入與讀取測試:從圖5可以看出,HDFS的平均寫入、讀取速度分別為4.72 Mb/s和27 Mb/s,相比原系統(tǒng)FC-SAN的1.5 Mb/s和2.26 Mb/s,讀寫速度有了明顯的提升。
(2)壓縮比測試:將一個(gè)病人產(chǎn)生的大約306 MB的MR圖像數(shù)據(jù)轉(zhuǎn)換為SDCM后,數(shù)據(jù)只有125 MB,壓縮率為40.8%;全系統(tǒng)平均壓縮率為40.6%。而采用SDCM不僅將原有數(shù)據(jù)進(jìn)行無損壓縮,同時(shí)還將數(shù)據(jù)轉(zhuǎn)換為鍵值對的形式,有利于后期利用MapReduce對數(shù)據(jù)直接進(jìn)行處理運(yùn)算,省去了重新格式化數(shù)據(jù)的時(shí)間,提高了運(yùn)算效率。
(3)計(jì)算測試:由于特征提取是圖像計(jì)算的基本步驟,本系統(tǒng)就一個(gè)4.2 GB的DICOM數(shù)據(jù)(10 290個(gè)圖像文件)進(jìn)行全局特征提取計(jì)算,以測試系統(tǒng)計(jì)算性能。在集群數(shù)目為1、2、3、4(集群數(shù)目為1時(shí),即為原系統(tǒng)的單機(jī)運(yùn)算模式)各自執(zhí)行5次測試計(jì)算,取各自的平均計(jì)算時(shí)間。從圖6的實(shí)驗(yàn)結(jié)果可以看出,對于較復(fù)雜的運(yùn)算,多節(jié)點(diǎn)比單機(jī)下運(yùn)行速度有了明顯的提高。

云計(jì)算是一項(xiàng)新興技術(shù),但目前并未廣泛地應(yīng)用到醫(yī)療機(jī)構(gòu)中。本文首先利用HDFS分布式文件系統(tǒng)與MapReduce計(jì)算框架技術(shù)設(shè)計(jì)了一個(gè)基于云計(jì)算技術(shù)的PACS混合架構(gòu),為原有PACS提供了一個(gè)低成本、易擴(kuò)展、高效的技術(shù)方案;設(shè)計(jì)和實(shí)現(xiàn)了SDCMO組件和WDO組件,并簡述了系統(tǒng)在公網(wǎng)環(huán)境下的讀寫流程;然后通過硬件部署的設(shè)計(jì)討論其可行性;最后在實(shí)驗(yàn)環(huán)境中測試了本系統(tǒng)的存儲(chǔ)傳輸、壓縮和計(jì)算性能。經(jīng)測試,系統(tǒng)初步達(dá)到了節(jié)省存儲(chǔ)空間、提高讀寫效率、提升計(jì)算能力的目的,為云計(jì)算技術(shù)真正應(yīng)用到醫(yī)院信息化建設(shè)中提供了理論基礎(chǔ)。
參考文獻(xiàn)
[1] 樊一鳴.云計(jì)算技術(shù)與區(qū)域醫(yī)學(xué)影像系統(tǒng)結(jié)合的探討[J]. 中國衛(wèi)生信息管理, 2011,8(1):21-22.
[2] 高林,宋相倩,王潔萍.云計(jì)算及其關(guān)鍵技術(shù)研究[J].微型機(jī)與應(yīng)用, 2011,30(10):5-7.
[3] 趙凱.基于云存儲(chǔ)的醫(yī)院PACS系統(tǒng)存儲(chǔ)設(shè)計(jì)[J].信息安全與技術(shù), 2012,3(4):92-93.
[4] 李彭軍,陳光杰,郭文明,等.基于HDFS的區(qū)域醫(yī)學(xué)影像分布式存儲(chǔ)架構(gòu)設(shè)計(jì)[J].南方醫(yī)科大學(xué)學(xué)報(bào),2011,31(3):495-498.
[5] LUÍS A,SILVA B. A PACS archive architecture supported on Cloud services[C].International Journal of Computer Assisted Radiology and Surgery,2011.