
摘 要: 頻繁項集挖掘是數(shù)據(jù)挖掘過程中的重要部分,,傳統(tǒng)數(shù)據(jù)挖掘算法中常用Apriori算法和FP增長算法來挖掘頻繁項集,。在實(shí)際應(yīng)用中,傳統(tǒng)算法往往不能用于頻繁更新的數(shù)據(jù)庫,,采用IMBT數(shù)據(jù)結(jié)構(gòu)能從不斷更新的數(shù)據(jù)庫中挖掘頻繁項集,,但是這將導(dǎo)致存儲空間不足和運(yùn)行效率低下的問題?;?a class="innerlink" href="http://forexkbc.com/tags/MapReduce" title="MapReduce" target="_blank">MapReduce的增量數(shù)據(jù)挖掘能夠有效解決這些問題,,通過對比基于MapReduce的增量數(shù)據(jù)挖掘和傳統(tǒng)增量數(shù)據(jù)挖掘的運(yùn)行時間可以證明,,基于Mapeduce的增量數(shù)據(jù)挖掘更高效,。
關(guān)鍵詞: 增量數(shù)據(jù)挖掘;MapReduce,;增量挖掘二叉樹,;頻繁項集
目前,數(shù)據(jù)挖掘[1]在計算機(jī)領(lǐng)域正飛速發(fā)展,。數(shù)據(jù)庫系統(tǒng)領(lǐng)域的發(fā)展主要在數(shù)據(jù)收集,、數(shù)據(jù)庫創(chuàng)建、數(shù)據(jù)管理,、數(shù)據(jù)分析,、數(shù)據(jù)挖掘、數(shù)據(jù)倉庫等方面,。在數(shù)據(jù)挖掘中,,挖掘關(guān)聯(lián)規(guī)則是相當(dāng)重要的部分。該部分的主要研究集中在挖掘算法上,。國內(nèi)外對頻繁項集挖掘算法一直都有著很深的研究,,例如:Apriori算法[1],F(xiàn)P增長算法[1-2],。
但是,,現(xiàn)實(shí)應(yīng)用中新的事務(wù)會不斷地錄入數(shù)據(jù)庫,這使得許多挖掘算法不能處理動態(tài)的數(shù)據(jù),。數(shù)據(jù)庫隨機(jī)變動,,這些算法不能有效應(yīng)對數(shù)據(jù)的增添、刪除等操作,,這使得增量數(shù)據(jù)挖掘[3-5]變得尤為重要,。
1 增量數(shù)據(jù)挖掘的必要性
在現(xiàn)實(shí)應(yīng)用中,事務(wù)數(shù)據(jù)庫常處于動態(tài)更新狀態(tài),,這需要對傳統(tǒng)關(guān)聯(lián)規(guī)則挖掘算法做進(jìn)一步改進(jìn),,因此出現(xiàn)了一些新的關(guān)聯(lián)規(guī)則。一些傳統(tǒng)的批量挖掘算法通過反復(fù)掃描數(shù)據(jù)庫來發(fā)現(xiàn)是否有新的事物添加到數(shù)據(jù)庫中,,但是這樣做需要大量的運(yùn)算時間,。
實(shí)際應(yīng)用中,,由于新的事務(wù)不停地添加到數(shù)據(jù)庫中,原先產(chǎn)生的頻繁項集將被淘汰掉,,基于新的數(shù)據(jù)庫會產(chǎn)生新的頻繁項集,。增量挖掘算法能有效避免這樣的問題。增量數(shù)據(jù)挖掘以之前挖掘的結(jié)果為基礎(chǔ),,利用新增的事務(wù)來進(jìn)行增量挖掘,。
2 增量挖掘發(fā)展現(xiàn)狀
2.1 基于IMBT的增量挖掘
為了能更好地利用現(xiàn)成的挖掘結(jié)果,采用了一種新的樹形結(jié)構(gòu)來代替FP樹,。該結(jié)構(gòu)叫做增量挖掘二叉樹(IMBT)[2],,在事務(wù)添加到數(shù)據(jù)庫中或從數(shù)據(jù)庫中刪除后,它能給出每個項集的支持度計數(shù),。與之前的在數(shù)據(jù)庫更新后通過反復(fù)掃描數(shù)據(jù)庫得出的頻繁項集支持度計數(shù)相比,,該算法一次只處理一條事務(wù)并且記錄數(shù)據(jù)集結(jié)構(gòu)中可能的頻繁項集,節(jié)約了大量的時間,。

2.4 在數(shù)據(jù)庫更新后挖掘頻繁項集
給定一個項集X,,如果X在事務(wù)數(shù)據(jù)庫中出現(xiàn)的頻率大于或等于預(yù)設(shè)的最小支持度,X則稱為頻繁項集,。如果項集X不是頻繁項集,,它的左半部分的子項集也不是頻繁的,該算法會停止處理左半部分的子項集,,這樣可以提高挖掘效率,。構(gòu)建好IMBT樹后,需要遍歷該樹來找出滿足最小支持度閾值的頻繁項集,,挖掘結(jié)果被保存在一張表中以便將來使用,。由于IMBT樹的構(gòu)建不需要支持度閾值,所以可以在數(shù)據(jù)庫更新后以任何支持度閾值挖掘頻繁項集,。
該方法采用IMBT樹結(jié)構(gòu),,重用從源數(shù)據(jù)庫中挖掘出來的結(jié)果挖掘新增事務(wù),使得性能有大幅度提升,。但是該方法仍面臨內(nèi)存空間不夠的問題,。隨著程序運(yùn)行,IMBT樹將會逐漸擴(kuò)大,,這使得內(nèi)存空間容納不下IMBT樹,,運(yùn)行效率也將大大降低。采用并行機(jī)制來改進(jìn)現(xiàn)有的串行挖掘算法將在性能上有很大地飛躍,。
3 問題解決方案
3.1 并行算法
在并行計算[6-7]中,,數(shù)據(jù)會被分發(fā)到不同的計算機(jī)節(jié)點(diǎn)中去,并行過程中每臺計算機(jī)對不同的數(shù)據(jù)塊執(zhí)行相同的任務(wù),。
由于真實(shí)環(huán)境中的數(shù)據(jù)庫通常非常大,,把整個數(shù)據(jù)庫保存在每個節(jié)點(diǎn)計算機(jī)上將造成存儲空間過多的浪費(fèi),。將數(shù)據(jù)庫拆分則能成功地將子數(shù)據(jù)庫分發(fā)在不同的計算機(jī)節(jié)點(diǎn)上。由于每臺計算機(jī)都保存子數(shù)據(jù)庫,,節(jié)約了大量的存儲空間,。
3.2 并行算法的優(yōu)勢
隨著數(shù)據(jù)的增加,當(dāng)數(shù)據(jù)量超過了GB的時候,,串行數(shù)據(jù)挖掘算法將很難在短時間內(nèi)給出挖掘結(jié)果,。而且單臺電腦沒有足夠的內(nèi)存來容納全部的數(shù)據(jù)。在并行條件下,,由于聚集了多臺計算機(jī)的存儲空間和處理能力,,因此并行算法能很好地解決運(yùn)行效率低下,存儲空間不足的問題,。
3.3 MapReduce工作流程
要順利實(shí)現(xiàn)并行算法需用MapReduce框架[8],。MapReduce是由谷歌開發(fā)的標(biāo)準(zhǔn)軟件架構(gòu),,主要用于處理大數(shù)據(jù)操作任務(wù),。該架構(gòu)由Map和Reduce組成。
當(dāng)有數(shù)據(jù)輸入時,,輸入數(shù)據(jù)被分割成塊發(fā)送到各個節(jié)點(diǎn)計算機(jī)上,,被分配了任務(wù)的節(jié)點(diǎn)計算機(jī)讀取并處理收到的輸入數(shù)據(jù)塊。Map函數(shù)處理完數(shù)據(jù)后輸出中間數(shù)據(jù):鍵值對,,輸出的中間鍵值對暫時緩沖到內(nèi)存,,這些內(nèi)存中的的鍵值對將會寫入到本地硬盤,然后將中間鍵值對在本地硬盤的位置信息發(fā)送給主節(jié)點(diǎn)計算機(jī),,主節(jié)點(diǎn)計算機(jī)負(fù)責(zé)向執(zhí)行Reduce函數(shù)的計算機(jī)發(fā)送位置信息,,這些計算機(jī)通過位置信息遠(yuǎn)程從運(yùn)行Map函數(shù)的計算機(jī)硬盤上讀取中間鍵值對,并將中間鍵值對按鍵分類,,擁有相同鍵的值都分在一起,,由Reduce函數(shù)處理后輸出最終結(jié)果[8]。圖4給出了其工作流程圖,。
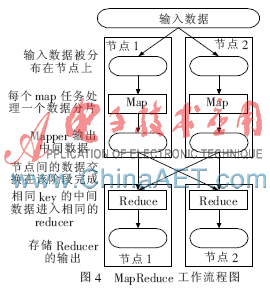
4 提出系統(tǒng)
4.1 系統(tǒng)思路
針對上述內(nèi)存空間和運(yùn)行效率的問題,,提出了一種并行構(gòu)建IMBT樹挖掘頻繁項集的方法。該方法主要完成兩項工作:并行構(gòu)建IMBT樹及頻繁項集計數(shù),。由于單臺計算機(jī)內(nèi)存和處理器能力有限,,該算法不適用于單臺電腦上運(yùn)行。為了讓算法的性能更高,,就需要盡量減少計算機(jī)之間數(shù)據(jù)的傳輸并且避免過多的處理過程,。
4.2 系統(tǒng)設(shè)計
首先將輸入文件分為若干獨(dú)立文件塊。然后并行處理輸入的每一個文件塊,。由于該方法需要用到基本數(shù)據(jù)結(jié)構(gòu)IMBT進(jìn)行增量挖掘,,不需要為IMBT樹定義最小支持度閾值,。當(dāng)本地IMBT樹在各個節(jié)點(diǎn)計算機(jī)中生成后,每個項集將會在獨(dú)立的節(jié)點(diǎn)計算機(jī)中進(jìn)行支持度計數(shù),。然后將生成的局部頻繁項集結(jié)合起來,,在全局?jǐn)?shù)據(jù)庫中生成一個全局的頻繁項集。最后,,由用戶定義一個最小支持度閾值,,并將其用于全局頻繁項集從而計算出真正的頻繁項集。MapReduce框架的工作模式能很好地實(shí)現(xiàn)該方法,,該方法的設(shè)計流程圖如圖5所示,。
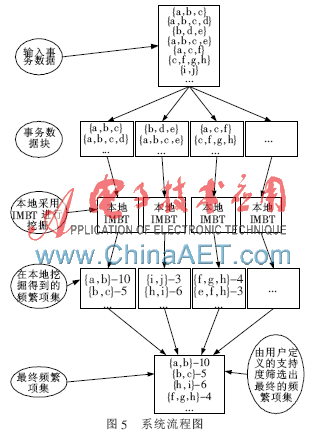
5 性能仿真與結(jié)果分析
為了對比基于MapReduce的增量數(shù)據(jù)挖掘和傳統(tǒng)增量數(shù)據(jù)挖掘的運(yùn)行效率,實(shí)驗(yàn)選取一個擁有85 643條事務(wù)的數(shù)據(jù)庫,,數(shù)據(jù)庫中每條事務(wù)的項目數(shù)平均為7個,,項目總共有1 300種,實(shí)驗(yàn)用計算機(jī)總共3臺,,配置均為雙核CPU AMD Athlon(tm)64 X2 Dual Core Processor 4000+,,內(nèi)存為2 GB,安裝Ubuntu10.10與Window XP雙系統(tǒng),,其中傳統(tǒng)IMBT挖掘算法在單臺電腦上用XP系統(tǒng)運(yùn)行,,基于MapReduce的IMBT在3臺電腦上用Ubuntu10.10運(yùn)行,其中1臺計算機(jī)配置為namenode,,另外2臺配置為datanode,。由于是實(shí)驗(yàn),所以沒有配置second namenode,。
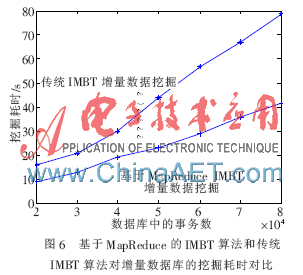
在數(shù)據(jù)挖掘進(jìn)行之前,,數(shù)據(jù)庫中預(yù)存有30 000條事務(wù),在基于MapReduce的IMBT算法中,,這30 000條事務(wù)被平均分配到3臺電腦上,,實(shí)驗(yàn)開始后不斷地向數(shù)據(jù)庫錄入事務(wù)數(shù),兩種算法均取支持度閾值為800,。圖6給出在不斷向數(shù)據(jù)庫中添加事務(wù)時,,兩種算法的耗時對比。
從圖6中可以看出,,基于MapReduce的IMBT算法的運(yùn)行效率幾乎比傳統(tǒng)IMBT算法快一倍,,圖中的運(yùn)行時間并非完全線性增長,這是由于數(shù)據(jù)庫中每條事務(wù)的項目種類和項目數(shù)量不一致導(dǎo)致的,。理論上基于MapReduce的IMBT算法采用2臺計算機(jī)同時進(jìn)行挖掘任務(wù),,效率應(yīng)該快一倍,圖中結(jié)果并未達(dá)到一倍是因?yàn)檎麄€MapReduce過程需要頻繁傳遞信息,namenode需要一定的響應(yīng)時間,,導(dǎo)致實(shí)際效率與理論效率存在一定誤差,。但基于MapReduce的增量數(shù)據(jù)挖掘算法在運(yùn)行效率上比傳統(tǒng)數(shù)據(jù)挖掘算法仍然有了質(zhì)的提升。
傳統(tǒng)數(shù)據(jù)挖掘技術(shù):Apriori,、FP樹等算法,,雖然都能有效地找出頻繁項集,但不能適用于真實(shí)環(huán)境下動態(tài)的數(shù)據(jù),。所以出現(xiàn)了增量數(shù)據(jù)挖掘,,本文給出了一種基于IMBT結(jié)構(gòu)的增量數(shù)據(jù)挖掘算法,該算法能夠在新事務(wù)添加到數(shù)據(jù)庫或從數(shù)據(jù)庫中刪除后有效地列舉出每一個項集的支持度計數(shù),。由于在樹的構(gòu)建過程中不需要預(yù)設(shè)最小支持度閾值,,該算法允許用戶以任何支持度閾值挖掘頻繁項集。結(jié)合之前從數(shù)據(jù)庫中挖掘出來的結(jié)果,,該算法能夠挖掘更新后的數(shù)據(jù)庫,,效率上有很大的提升。但是IMBT樹在單臺計算機(jī)中運(yùn)行時,,該算法面臨存儲空間不足的問題,,隨著算法的進(jìn)行,IMBT樹逐漸擴(kuò)展,,會造成內(nèi)存溢出,,效率降低。
為此提出了一種新的方法,,該方法采用MapReduce框架,將數(shù)據(jù)庫分為若干子數(shù)據(jù)庫然后發(fā)向多個節(jié)點(diǎn)計算機(jī),,由于計算機(jī)集群聚集了多臺計算機(jī)的存儲能力和計算能力,,在存儲空間上可以動態(tài)的增加,并且能夠并行處理數(shù)據(jù),,從而解決了運(yùn)行效率和存儲空間的問題,,因此該方法比傳統(tǒng)的非并行增量算法更高效。
參考文獻(xiàn)
[1] 范明,,孟小峰.數(shù)據(jù)挖掘概念與技術(shù)[M].北京:機(jī)械工業(yè)出版社,,2012.
[2] 蔣翠清,胡俊妍.基于FP-tree的最大頻繁項集挖掘算法[J].合肥工業(yè)大學(xué)學(xué)報(自然科學(xué)版),,2010,,33(9):387-1391.
[3] HONG T P, WANG C Y,, TAO Y H. A new incremental data mining algorithm using pre-large itemsets[J]. Intelligent Data Analysis,, 2001, 5(2): 111-129.
[4] HONG T P,, LIN C W,, WU Y L. Incrementally fast updated frequent pattern trees[J]. Expert Systems With Applications,,2008,34(4):2424- 2435.
[5] YANG C H,, YANG D L. IMBT-a binary Tree for Efficient Support Counting of Incremental Data Mining[J]. 2009 International Conference on Computational Science & Engineering,, 2009,1(1):324-329.
[6] 劉鵬.云計算[M].北京:電子工業(yè)出版社,,2011.
[7] 高嵐嵐.云計算與網(wǎng)格計算的深入比較研究[J].海峽科學(xué),,2009(2):56-57.
[8] LAM C, 韓冀中.Hadoop實(shí)戰(zhàn)[M].北京:人民郵電出版社,,2012.