
摘 要: 智能體對(duì)環(huán)境的認(rèn)識(shí)是其進(jìn)行決策的重要依據(jù)。在機(jī)器人足球仿真比賽(RoboCup)中,視覺感知是智能體獲得信息、構(gòu)建世界模型的主要途徑。針對(duì)仿真比賽中球員智能體進(jìn)行決策時(shí)信息不準(zhǔn)確的問題,結(jié)合優(yōu)先級(jí)和可信值對(duì)智能體的視覺策略進(jìn)行了設(shè)計(jì)。根據(jù)對(duì)觀察目標(biāo)需求的緊迫程度動(dòng)態(tài)地指定觀察目標(biāo)的優(yōu)先級(jí),然后結(jié)合世界模型維護(hù)的觀察目標(biāo)的可信值生成各個(gè)視覺角度的評(píng)價(jià)值,通過搜索評(píng)價(jià)值最大的視覺角度獲得優(yōu)化的視覺信息。實(shí)驗(yàn)結(jié)果表明這種視覺策略使球員動(dòng)作的執(zhí)行更加可靠,增強(qiáng)了球隊(duì)的整體性能。
關(guān)鍵詞: RoboCup仿真比賽;智能體;視覺策略
多智能體系統(tǒng)的研究是計(jì)算機(jī)科學(xué)和人工智能研究的重點(diǎn)。RoboCup機(jī)器人足球比賽是多智能體系統(tǒng)MAS(Multi-Agent System)和分布式人工智能的一個(gè)重要研究平臺(tái)[1]。
RoboCup仿真平臺(tái)中環(huán)境是不可知的,球員對(duì)于環(huán)境的認(rèn)識(shí)主要來源于感知系統(tǒng)[2],感知系統(tǒng)包括視覺感知、聽覺感知和身體感知,這些信息由仿真服務(wù)器按規(guī)定的周期發(fā)送給球員。身體感知只能感知球員自身的信息,而聽覺感知非常有限且不可靠,因此視覺信息是最直接可靠、也是最多使用的信息獲取方式。在復(fù)雜多變的足球比賽中,球員需要依據(jù)當(dāng)前場(chǎng)上的局勢(shì)進(jìn)行最優(yōu)的動(dòng)作決策以及動(dòng)作的精確執(zhí)行,這就要求智能體必須以一種智能的方式合理調(diào)整視覺,準(zhǔn)確、及時(shí)地跟蹤場(chǎng)上狀態(tài)的變化。
目前各個(gè)仿真球隊(duì)采用的視覺策略中,有讓球員始終朝向球看,方法簡(jiǎn)單但卻直接、有效;有的策略則將智能體的多個(gè)觀察目標(biāo)按照其可信值排序,如果可信值低于某個(gè)值,就提出觀察請(qǐng)求,這種方法保證所有觀察目標(biāo)的平均可信值盡量高[3]。實(shí)際上當(dāng)球員在比賽中面臨不同局勢(shì)時(shí),想要觀察的目標(biāo)是不同的,而且對(duì)不同目標(biāo)的關(guān)心程度也是不同的。球員最希望獲得的是那些與其動(dòng)作決策關(guān)系密切的場(chǎng)上信息,采用以上視覺策略會(huì)使球員無法全面、準(zhǔn)確地掌握?qǐng)錾闲畔ⅲ瑥亩鴮?dǎo)致動(dòng)作決策的效率不高。
本文設(shè)計(jì)了一種基于優(yōu)先級(jí)和可信值的視覺策略,通過綜合考慮觀察目標(biāo)的可信值和優(yōu)先級(jí)來調(diào)整球員的最佳視覺角度,優(yōu)化球員視覺信息的獲取。
1 RoboCup中球員智能體的視覺
在RoboCup仿真環(huán)境里,球員有身體朝向和臉朝向兩個(gè)概念。身體朝向決定了每個(gè)球員dash(沖刺)的方向,即每個(gè)球員只能朝身體方向給自己加速。球員觀察的范圍主要由臉朝向決定,球員的視野是一個(gè)以臉朝向?yàn)橹行模?fù)各1/2視野寬度的扇形。球員距離觀察目標(biāo)越遠(yuǎn),看得越不清楚。視野寬度ViewWidth可以為45°(窄視角)、90°(普通視角)和180°(寬視角)。每個(gè)球員在獲取視覺信息時(shí)都是用一種視野寬度的模式觀察,不同視野寬度帶來的觀察效果也不同,較窄的視野寬度所獲得信息的頻率較快。目前仿真環(huán)境規(guī)定45°視野寬度每0.75周期獲得一次視覺信息,90°視野寬度每1.5周期獲得一次視覺信息,180°視野寬度每3個(gè)周期獲得一次視覺信息[4]。
通過調(diào)整視野寬度、身體朝向以及臉朝向可以獲取更多的視覺信息。球員可以通過change_view指令改變視野寬度,turn指令改變身體朝向,turn_neck指令轉(zhuǎn)動(dòng)臉朝向和身體朝向之間的夾角。但是turn指令與dash、kick等指令互斥,不能在同一周期發(fā)送,否則會(huì)與其他決策模塊產(chǎn)生沖突。turn_neck指令則可以和dash、kick、turn等動(dòng)作在同一個(gè)仿真周期內(nèi)執(zhí)行,球員的面朝向和身體朝向最多成90°角,在不轉(zhuǎn)身的情況下球員理論上可以觀察到的最大角度為:
觀察到的最大角度=視野寬度/2+90°(1)
因此,球員的視覺決策一般放在所有動(dòng)作決策模塊之后執(zhí)行,并且要對(duì)產(chǎn)生的決策效果做預(yù)測(cè),預(yù)測(cè)后續(xù)周期需要的信息,然后根據(jù)需求計(jì)算出最終實(shí)際要轉(zhuǎn)動(dòng)脖子的角度,調(diào)整角度,使下個(gè)視覺信息到來時(shí)視野能覆蓋觀察目標(biāo)。
2 視覺策略的設(shè)計(jì)
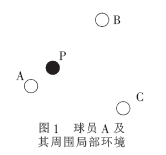
比賽中在一個(gè)仿真周期內(nèi)球員想要觀察的目標(biāo)往往不是唯一的,球和其他隊(duì)友或敵人都有可能成為被觀察的目標(biāo),如圖1所示,球員A控球,球員B和C為隊(duì)友,球員P為敵方隊(duì)員,若A考慮傳球,則B、C和P可能做出截球動(dòng)作,球員A首先需要觀察一下球員B、C和P,以判斷隊(duì)友是否能夠截到球,再做出決策是否應(yīng)該執(zhí)行該動(dòng)作。所以最終視覺角度的確定需要一定的設(shè)計(jì),對(duì)每一個(gè)可能的視角,可以使用一個(gè)評(píng)價(jià)值進(jìn)行評(píng)價(jià),考慮到場(chǎng)上形勢(shì)和決策的需要,在計(jì)算評(píng)價(jià)值時(shí)應(yīng)該綜合考慮各個(gè)被觀察對(duì)象的優(yōu)先級(jí)和可信值,才能兼顧處理多個(gè)觀察請(qǐng)求,獲得較優(yōu)視覺信息。
2.1 目標(biāo)優(yōu)先級(jí)
球員根據(jù)對(duì)各個(gè)觀察目標(biāo)的不同需求程度,設(shè)定優(yōu)先級(jí)priority。對(duì)于球員的n個(gè)觀察目標(biāo)(0<n≤23),設(shè)定的優(yōu)先級(jí)分別為pi(i=1,2,…,n)。以觀察球員為中心,指向?qū)Ψ桨雸?chǎng)的方向?yàn)?角度,則被觀察物體相對(duì)球員的角度分別為θi(i=1,2,…,n),θi∈[-180,180]。
觀察目標(biāo)分為三個(gè)部分:球、動(dòng)態(tài)對(duì)象和固定對(duì)象。球是隊(duì)員必須經(jīng)常觀察的對(duì)象,對(duì)球的信息不準(zhǔn)確,就談不上做各種決策,因此球的優(yōu)先級(jí)是最高的。動(dòng)態(tài)對(duì)象由上層決策模塊決定,比如當(dāng)球員控球時(shí),就把場(chǎng)上可以傳球的隊(duì)友加入到觀察請(qǐng)求中,并把離球員最近的敵方隊(duì)員加入觀察請(qǐng)求。動(dòng)態(tài)對(duì)象的優(yōu)先級(jí)可根據(jù)場(chǎng)上情況做適當(dāng)調(diào)整,對(duì)于可傳球隊(duì)友,傳球成功率越高,優(yōu)先級(jí)越高。固定對(duì)象是預(yù)先規(guī)定好的,它包括某些在大部分時(shí)刻都必須觀察的對(duì)象,如離球員最近的隊(duì)友。進(jìn)入對(duì)方半場(chǎng)時(shí)還要把對(duì)方的守門員加進(jìn)來。固定對(duì)象的優(yōu)先級(jí)是確定的。當(dāng)固定對(duì)象與動(dòng)態(tài)對(duì)象重疊時(shí),觀察請(qǐng)求不進(jìn)行重復(fù)添加,優(yōu)先級(jí)以動(dòng)態(tài)對(duì)象為準(zhǔn)。
球員智能體的多個(gè)觀察請(qǐng)求用C++STL的map模板進(jìn)行保存,定義如下:
map<ObjectT,double>mVisualReqQueue;
MVisualReqQueue的每個(gè)元素是一個(gè)二元組<對(duì)象,優(yōu)先級(jí)>,描述了從對(duì)象到其當(dāng)前的優(yōu)先級(jí)之間的映射。
2.2目標(biāo)可信值
RoboCup中,由于球員智能體每一次獲得的視覺信息十分有限且含有噪聲,因此在對(duì)這些數(shù)據(jù)的加工和對(duì)世界模型的維護(hù)過程中,需要引入記憶模型[5]。記憶模型一方面負(fù)責(zé)保存環(huán)境物體的歷史信息,另一方面通過一個(gè)可信值(confidence)來描述目標(biāo)信息的準(zhǔn)確程度,它的取值范圍是[0,1],每一個(gè)仿真周期目標(biāo)的可信值更新如下:

這種算法是優(yōu)先級(jí)高,可信值低的物體在最終結(jié)果中占的比重大些,既有利于選出觀察優(yōu)先級(jí)高的對(duì)象,又對(duì)可信值低的對(duì)象加以重視。顯然,當(dāng)視野中覆蓋的物體越多,對(duì)這些物體的優(yōu)先級(jí)越高,物體的可信值越低,則該視野所觀察到的有用信息就越多,其評(píng)價(jià)值也越大。
進(jìn)行最佳角度搜索的時(shí)候?qū)⒁^察的目標(biāo)置于球員視野的右邊界,然后搜索請(qǐng)求觀察的每一個(gè)物體。搜索過程用偽碼描述如下:

確定好最佳視覺角度后,即可通過turn_neck指令調(diào)整球員視角,以獲得期望的信息。
此外,根據(jù)比賽規(guī)則,由于球員每周期只能執(zhí)行一個(gè)動(dòng)作,所以過于頻繁的獲取信息也沒有意義,在本策略中的視野寬度ViewWidth采用90°-45°-45°的方案,這樣獲取視覺信息的周期依次是0-1.5周期-2.25周期-3周期,這樣以3周期為一次循環(huán)單位不斷循環(huán),可以保證每周期都可以獲得視覺信息,同時(shí)又可獲得較大的視野范圍。
3 仿真實(shí)驗(yàn)結(jié)果
為測(cè)試本文視覺策略的有效性,先后對(duì)采用和不采用本視覺策略的球隊(duì)作了長(zhǎng)時(shí)間測(cè)試,為減少比賽隨機(jī)性對(duì)結(jié)果的影響,取同一支球隊(duì)作為對(duì)抗球隊(duì),表1給出統(tǒng)計(jì)的對(duì)比數(shù)據(jù)。從表1可以看出,采用改進(jìn)的視覺策略后,我方平均控球率提高了8.6個(gè)百分點(diǎn),進(jìn)球機(jī)會(huì)增加了。

RoboCup仿真比賽的環(huán)境是復(fù)雜多變的,球員智能體需要依據(jù)當(dāng)前場(chǎng)上的形勢(shì)進(jìn)行決策,信息的準(zhǔn)確獲取是智能體動(dòng)作決策和執(zhí)行的前提,智能體應(yīng)能以一種高效的方式合理調(diào)整視覺才能保證準(zhǔn)確地跟蹤場(chǎng)上狀態(tài)的變化。本文對(duì)球員的視覺策略進(jìn)行了設(shè)計(jì),根據(jù)動(dòng)作決策的需要,考慮球員當(dāng)前觀察目標(biāo)的優(yōu)先級(jí),結(jié)合它們的可信值,計(jì)算出各個(gè)視覺角度的評(píng)價(jià)值,最后通過搜索比較確定一個(gè)最佳的視覺角度,為多智能體的團(tuán)隊(duì)協(xié)作提供了全面、準(zhǔn)確而及時(shí)的信息。
將本文提出的視覺策略應(yīng)用在RoboCup仿真球隊(duì)后,球隊(duì)的平均控球率提高了8.6%,球員之間的傳球成功率有所提高,說明新的視覺策略為智能體間的協(xié)作提供了較為可靠的信息,對(duì)增強(qiáng)球隊(duì)整體性能具有一定效果。
參考文獻(xiàn)
[1] 李實(shí),徐旭明,葉榛,等.機(jī)器人足球仿真比賽的Server模型[J].系統(tǒng)仿真學(xué)報(bào),2000,12(2):138-141.
[2] 郭定明,張樹林,李璞.淺談RoboCup中的感知系統(tǒng)及相關(guān)決策[A].2004中國機(jī)器人足球比賽暨研討會(huì)論文集[C].廣州:中國自動(dòng)化學(xué)會(huì)機(jī)器人競(jìng)賽工作委員會(huì),2004:15-18.
[3] REIS L P, LAU N. FC Portugal Team Description: RoboCup 2000 Simulation League Champion[J]. Springer Verlag Lecture Notes in Artificial Intelligence, 2001(2019):175-197.
[4] CHEN M, FOROUGHI E, HENITZ F, et al. RoboCup Soccer Server Manual for Soccer Server Version 7.07[EB/OL]. http://sserver.sourceforge.net/. 2003.
[5] DE BOER R, KOK J. The Incremental Development of a Synthetic Multi-Agent System: The UvA Trilearn 2001 Robotic Soccer Simulation Team[D]. University of Amsterdam, 2002.