
摘 要: 利用網(wǎng)頁的視覺特征和DOM樹的結(jié)構(gòu)特性對網(wǎng)頁進行分塊,并采用逐層分塊逐層刪減的方法將與正文無關(guān)的噪音塊刪除,從而得到正文塊。對得到的正文塊運用VIPS算法得到完整的語義塊,最后在語義塊的基礎(chǔ)上提取正文內(nèi)容。試驗表明,這種方法是切實可行的。
關(guān)鍵詞: 頁面分塊;信息提取;視覺特征
隨著互聯(lián)網(wǎng)的迅速發(fā)展,互聯(lián)網(wǎng)上的信息量以幾何級數(shù)倍增。人們需要在海量的信息庫中查找自己需要的信息。雖然搜索引擎能幫助人們快速地搜索到想要的信息,但每個網(wǎng)頁除了正文內(nèi)容外還摻雜了很多用戶不需要的信息。例如,為了方便用戶瀏覽而加入的導(dǎo)航鏈接、出于商業(yè)利益而加入的廣告鏈接、版權(quán)信息以及相關(guān)主題閱讀推薦鏈接等。這些信息摻雜在網(wǎng)頁中,影響了用戶對主題內(nèi)容的瀏覽。因此,如何從包含大量噪音內(nèi)容的網(wǎng)頁中將正文信息準(zhǔn)確、完整地提取出來成為眾多研究者研究的課題。
1 相關(guān)工作
在Web信息抽取領(lǐng)域,已經(jīng)有大量的研究工作,包括HTML結(jié)構(gòu)分析方法(如XWRAP和Lixto)、基于自然語言處理的方法(如SRV和WHISK)、機器學(xué)習(xí)方法等。但是這些方法都是針對特定網(wǎng)站或特定格式的,不具有通用性,并且不能完成自動抽取。眾多的Web網(wǎng)頁正文信息提取方法都有各自的優(yōu)缺點。
參考文獻(xiàn)[1]采用機器學(xué)習(xí)的方法提取網(wǎng)頁正文信息。此方法通過對網(wǎng)頁集的學(xué)習(xí),不斷生成新的模板,從而建立模板庫。提取信息時,查找對應(yīng)的模板,利用模板中主題結(jié)點信息,直接定位主題信息塊,快速提取主題信息。雖然此方法采用自動抽取的方式,其智能化程度也在一定程度上方便了用戶的使用,但對于一個新的網(wǎng)頁,若找不到匹配的模板,此方法就不適用了。而且隨著模板數(shù)量的增加,模板庫的維護工作也變得越來越復(fù)雜。
從頁面視覺特征的角度對網(wǎng)頁結(jié)構(gòu)進行挖掘也是很有效的途徑。典型的代表就是微軟亞洲研究院提出的VIPS(Vision-based Page Segmentation)算法[2]。它利用背景顏色、字體顏色和大小、邊框、邏輯塊和邏輯塊之間的間距等視覺特征,通過制定相應(yīng)的規(guī)則把頁面分成了各個視覺信息塊。這能在一定程度上滿足復(fù)雜頁面對算法的要求,但由于視覺特征的復(fù)雜性,運用的啟發(fā)知識往往較為模糊,需要人工不斷地總結(jié)調(diào)整規(guī)則,因此如何保證規(guī)則集的一致性是一大難點。
有許多研究者考慮使用HTML標(biāo)簽信息來劃分頁面。其中,中科院計算所軟件研究室提出利用TABLE標(biāo)記和視覺特征對頁面進行語義塊劃分,并識別各語義塊屬性的算法TVPS(Table and Vision based Page Segmentation)[3]。TVPS算法中的分塊方法只考慮了各個最底層的TABLE標(biāo)記,但是實際情況中網(wǎng)頁樣式結(jié)構(gòu)和TABLE標(biāo)記的嵌套關(guān)系都非常復(fù)雜,網(wǎng)頁正文信息不一定全在最底層的TABLE標(biāo)記中。如果只考慮最底層的TABLE標(biāo)記,會遺漏部分正文信息。
參考文獻(xiàn)[4]根據(jù)正文字?jǐn)?shù)多、標(biāo)點符號多2個特征,提出一種基于正文特征的網(wǎng)頁正文信息提取方法。該方法利用HTML標(biāo)簽對網(wǎng)頁內(nèi)容進行分塊,把具有正文特征的塊保留,不具有正文特征的塊舍棄,從而進行網(wǎng)頁正文信息的提取。這種方法對于新聞、財經(jīng)、科技等類型網(wǎng)頁提取效果較好,但對于圖片多文字少或?qū)τ谟脩艋靥謹(jǐn)?shù)較少的論壇型網(wǎng)頁提取效果較差。
以往的基于分塊的網(wǎng)頁信息提取算法都是對整個網(wǎng)頁進行處理,并分完塊后再對頁面塊進行取舍,確定正文塊。這類方法對與頁面主題無關(guān)的噪音信息也進行了處理,增加了算法的復(fù)雜度。本文在前人工作的基礎(chǔ)上結(jié)合參考文獻(xiàn)[3]、[4]、[7],提出采用逐層分塊逐層刪減的方法對Web網(wǎng)頁進行信息提取,以降低算法的復(fù)雜度,提高抽取的準(zhǔn)確度,并用試驗驗證其可行性。
2 正文提取算法
Web網(wǎng)頁通常分為3種類型:主題型網(wǎng)頁、圖片型網(wǎng)頁、目錄型網(wǎng)頁[5]。主題型網(wǎng)頁通常通過成段的文字描述1個或多個主題(如新聞網(wǎng)頁);圖片型網(wǎng)頁中內(nèi)容是通過圖片體現(xiàn)的,只用少量文字對圖片進行說明;目錄型網(wǎng)頁通常不會用成段的文字描述,而是提供指向相關(guān)網(wǎng)頁的超鏈接,也可稱為索引頁。本文所研究的網(wǎng)頁正文提取是針對主題型網(wǎng)頁展開的。
2.1 VIPS算法
VIPS算法充分利用了Web頁面的布局特征。它首先從DOM樹中提取出所有合適的頁面塊,然后根據(jù)這些頁面塊檢測出它們之間所有的分割條,包括水平和垂直方向;最后基于這些分割條,重新構(gòu)建Web頁面的語義結(jié)構(gòu)。對于每一個語義塊又可以使用VIPS算法繼續(xù)分割為更小的語義塊。該算法分為頁面塊提取、分隔條提取和語義塊重構(gòu)3部分,并且是遞歸調(diào)用的過程,直到條件不滿足為止。在此僅對頁面塊提取方法做簡單介紹。
整個VIPS算法自頂向下,圖1(a)顯示的是一個表格,該表格是整個Web頁面的一部分,它的DOM樹結(jié)構(gòu)如圖1(b)所示。在頁面塊的提取過程中,當(dāng)遇到<TABLE>結(jié)點時,它只有1個有效的孩子結(jié)點<TR>。根據(jù)參考文獻(xiàn)[2]中規(guī)則,進入<TR>標(biāo)簽。該<TR>結(jié)點具有5個<TD>孩子結(jié)點,但是它們中只有3個是有效結(jié)點,而且第1個孩子結(jié)點的背景顏色與父親結(jié)點的顏色不同。根據(jù)參考文獻(xiàn)[2]中規(guī)則,該<TR>結(jié)點將被分割,而第1個<TD>結(jié)點在本次迭代中不進行分割,將其保存到頁面塊池中。第2個和第4個<TD>結(jié)點為無效結(jié)點,因此將被刪除。對于第3個和第5個<TD>結(jié)點,根據(jù)參考文獻(xiàn)[2]中規(guī)則,在本次迭代中不再分割,被保存到頁面塊池中。因此最終得到3個頁面塊VB2_1、VB2_2和VB2_3。
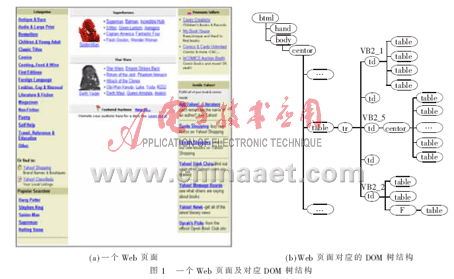
2.2 頁面塊提取和過濾
由于VIPS算法的重點是對網(wǎng)頁進行分塊,所以其要對網(wǎng)頁上的所有內(nèi)容進行處理。而對于網(wǎng)頁信息提取,只有與主題相關(guān)的正文信息才有意義,其他內(nèi)容(如導(dǎo)航欄、相關(guān)閱讀、廣告鏈接、用戶評論等)都屬于噪音信息,只需要識別出來,并不需要對其進行處理。如果直接利用VIPS算法對網(wǎng)頁進行頁面塊的劃分,則會將那些與正文內(nèi)容無關(guān)的噪音內(nèi)容也進行處理,需要大量的內(nèi)存來保存結(jié)點信息,增加了算法的時間和空間開銷,也不利于提高提取的準(zhǔn)確度。所以本文采用逐層分塊逐層刪減的方法,將網(wǎng)頁中的噪音信息盡早地刪除,以節(jié)省開銷、提高準(zhǔn)確度。本文在頁面塊提取和過濾階段只利用了VIPS算法中的頁面塊提取方法,并未進行分隔條的提取和語義塊的重構(gòu),而是在過濾完成后對保留的頁面塊進行相應(yīng)的處理。
由于VIPS算法中的頁面塊提取過程是結(jié)合DOM樹和視覺特征,利用人工制定的規(guī)則來判斷該結(jié)點是否需要再分,并用頁面塊池來存儲要被繼續(xù)提取的頁面塊,所以可以對每一層完全提取后頁面塊池中保存的頁面塊進行相應(yīng)的判斷,將與標(biāo)題內(nèi)容無關(guān)的噪音塊刪除。這樣將每1次提取出來的頁面塊中的噪音塊都刪除,當(dāng)頁面塊提取完后,剩下的頁面塊即為要進行信息提取的頁面塊。
對網(wǎng)頁信息的抽取包括:頁面主題、發(fā)表時間、正文內(nèi)容,抽取流程如圖2所示。

(1)構(gòu)建DOM樹。由于HTML書寫的隨意性,首先對HTML代碼進行預(yù)處理,例如對書寫不規(guī)范的標(biāo)簽進行補全處理,以免在后面的程序處理中造成錯誤,并去除一些無用標(biāo)簽,如<script>、注釋信息等。網(wǎng)絡(luò)上有很多網(wǎng)頁預(yù)處理工具可以將不規(guī)范的html代碼規(guī)范化,例如HTML Tidy等。構(gòu)造DOM樹的過程中要保存每個結(jié)點的字體大小、顏色、粗細(xì)、背景色等視覺信息,方便后續(xù)處理。
(2)對網(wǎng)頁進行逐層分塊逐層刪減。根據(jù)對大量網(wǎng)頁的統(tǒng)計,處于網(wǎng)頁最上方和最下方的頁面塊基本全部是網(wǎng)站的導(dǎo)航鏈接和版權(quán)聲明,這2個頁面塊可以直接刪除。而頁面塊的中心位置與網(wǎng)頁的左邊框或右邊框的距離小于一定閾值的基本全為廣告信息。在實驗數(shù)據(jù)中有的廣告可以占到網(wǎng)頁寬度的40%。可以利用這一特征將網(wǎng)頁四周的噪音塊刪除。定義網(wǎng)頁的左上角頂點為坐標(biāo)原點,網(wǎng)頁的右下角頂點坐標(biāo)為(WIDTH,HEIGHT),每個頁面塊的中心點坐標(biāo)為(Center_X,Center_Y),定義4個閾值:上臨界值(TOP)、下臨界值(BOTTOM)、左臨界值(LEFT)、右臨界值(RIGHT),據(jù)此可以得出對頁面塊進行刪減的2個判斷規(guī)則:
規(guī)則1:IF Center_X<LEFT‖Center_X>RIGHT,則刪除該塊。
規(guī)則2:IF Center_Y<TOP‖Center_Y>BOTTOM, 則刪除該塊。
進行完第1次頁面塊提取后可以利用這2個判斷規(guī)則將位于頁面四周的導(dǎo)航欄、廣告內(nèi)容、版權(quán)聲明等頁面塊刪除。
網(wǎng)頁中不僅包括正文標(biāo)題、發(fā)表時間、主題相關(guān)圖片、正文內(nèi)容等要抽取的信息,還包括相關(guān)閱讀等與頁面主題相關(guān)但不需要抽取的信息以及圖片廣告、搜索欄等噪音內(nèi)容。在頁面塊提取過程中記錄該頁面塊的中心位置的坐標(biāo)、文字長度(TextLength)、鏈接文字長度(LinkTextLength)、圖片數(shù)量(ImageNum)。記正文字?jǐn)?shù)和鏈接個數(shù)的比值為F。設(shè)置閾值T(試驗中T=2)。據(jù)此可以得出對頁面塊進行刪減的3個判斷規(guī)則:
規(guī)則3:IF F<T && ImageNum=0,則說明該塊為相關(guān)閱讀或文字廣告鏈接,刪除該塊
規(guī)則4:IF F<T && ImageNum>0 && CENTER_Y>HEIGHT/2,即鏈接較多,文字較少且位于網(wǎng)頁的下方,則為圖片廣告,刪除該塊。
規(guī)則5:IF TextLength<100,可能為搜索欄或用戶評論等噪音,刪除該塊。
對逐層提取出來的頁面塊按照以上5個判斷規(guī)則逐層將噪音塊刪除。
2.3 正文信息提取
逐層分塊逐層刪減后仍保留在內(nèi)存塊池中的頁面塊被認(rèn)為是正文頁面塊,下面的工作是對這些頁面塊進行信息抽取。在正式提取內(nèi)容前要對這些頁面塊進行分隔條提取和語義塊的重構(gòu),以保證提取內(nèi)容的語義完整性。
(1)提取頁面主題。包含主題的頁面塊一般具有以下視覺特征:字號比其他頁面塊都大;字體顏色與其他塊不同;周圍有較多的空白;位置在網(wǎng)頁的上方。在此假定滿足以上條件中的3個或3個以上即被認(rèn)為是頁面主題塊。
(2)提取發(fā)表時間。本文利用視覺信息識別包含發(fā)表時間的頁面塊。在視覺上,發(fā)表時間一般位于頁面主題下方,且字號相對其他內(nèi)容塊較小。利用參考文獻(xiàn)[3]中提到的位置和詞性雙重約束的方式對發(fā)表時間進行識別:考慮頁面塊標(biāo)題和正文之間的文字,判斷它們的詞性,對詞性為“數(shù)詞(m)”或“時間詞(t)”的文字串,把它挖掘出來作為發(fā)表時間。本文采用中國科學(xué)院計算技術(shù)研究所軟件室研發(fā)的詞法分析器ICTCLAS[6]進行詞性的判斷。其對時間信息的分析結(jié)果如下所示:
“2004-06-15/m 08: /m 57: /m 45/m”、“2004年/t06月/t 5日/t05: /m 37/m”。
(3)提取正文內(nèi)容。需要注意的是:有的正文中有小標(biāo)題,其視覺信息與其他正文內(nèi)容不同,這上面的分塊中已有體現(xiàn)。
3 試驗與分析
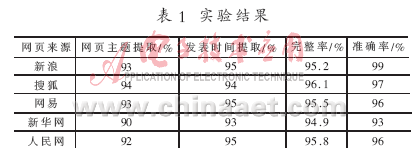
為驗證該方法的可行性,從新浪、搜狐、網(wǎng)易、新華網(wǎng)、人民網(wǎng)5大熱門網(wǎng)站中各抽取100篇網(wǎng)頁,共500篇網(wǎng)頁進行試驗,網(wǎng)頁內(nèi)容涉及新聞、財經(jīng)、軍事等多個領(lǐng)域。從頁面標(biāo)題、發(fā)表時間、提取的完整率和準(zhǔn)確率等方面進行評價。為驗證其性能,從中抽取200篇進行人工抽取,并進行比對。實驗結(jié)果如表1所示。
準(zhǔn)確率和完整率的計算公式如下:
準(zhǔn)確率=(正確提取正文信息網(wǎng)頁個數(shù)/網(wǎng)頁總數(shù))×100%
完整率=(完整提取正文信息的網(wǎng)頁個數(shù)/正確提取正文信息網(wǎng)頁個數(shù))×100%
通過對實驗結(jié)果的分析發(fā)現(xiàn),有些網(wǎng)頁的發(fā)表時間前后都帶有網(wǎng)站的鏈接,導(dǎo)致該頁面塊被當(dāng)作噪音刪除。實驗數(shù)據(jù)表明,正文抽取完整率和準(zhǔn)確率都達(dá)到90%以上,證明了該方法的可行性。
本文在VIPS算法的基礎(chǔ)上結(jié)合網(wǎng)頁正文抽取的特點,實現(xiàn)了一種根據(jù)頁面視覺特征對Web頁面進行逐層分塊逐層刪減的正文信息抽取方法。下一步將對判斷規(guī)則進行完善,以達(dá)到更好的抽取效果。
參考文獻(xiàn)
[1] 歐健文,董守斌,蔡斌.模板化網(wǎng)頁主題信息的提取方法[J].清華大學(xué)學(xué)報,2005,45(S1):1743-1747.
[2] CAI D, YU S, WEN J R, et al. VIPS: A vision-based page segmentation algorithm. Microsoft Technical Report, MSR-TR-2003-79. 2003:10.
[3] 于滿泉,陳鐵睿,許洪波.基于分塊的網(wǎng)頁信息解析器的研究與設(shè)計[J].計算機應(yīng)用,2005,25(4):974-976.
[4] 孫桂煌,劉發(fā)升.基于正文特征的網(wǎng)頁正文信息提取方法[J].現(xiàn)代計算機,2008(9):34-37.
[5] JOHNSON R,HOELLOR J,ARENDSEN A,et al.Spring框架高級編程[M].蔣培,譯.北京:機械工業(yè)出版社,2006.
[6] 張華平.ICTCLAS[EB/OL]. [2009-08-15].http://mtgroup.
ict.ac.cn/~zhp/ICTCLAS.htm. 2002.
[7] 黃文蓓,楊靜,顧君忠.基于分塊的網(wǎng)頁正文信息提取算法研究[J].計算機應(yīng)用,2007,27(B06):24-26.