
摘 要:提出了一種改進(jìn)互信息的譯文選擇方法,認(rèn)為詞語(yǔ)的譯文的選擇不是孤立進(jìn)行的,上下文對(duì)譯文的選擇有著重要的意義,通過(guò)對(duì)已有的互信息公式加入翻譯模型特征進(jìn)行改進(jìn),結(jié)合翻譯模型與互信息來(lái)選擇最佳譯文,經(jīng)過(guò)BLEU(BiLingual Evaluation Understudy)作為機(jī)器評(píng)價(jià)準(zhǔn)則的實(shí)驗(yàn)結(jié)果表明,該方法優(yōu)于傳統(tǒng)的互信息詞語(yǔ)譯文選擇的方法。
關(guān)鍵詞:互信息;譯文選擇;翻譯模型;譯文選擇模型
譯文選擇是指根據(jù)從語(yǔ)料庫(kù)中學(xué)習(xí)翻譯知識(shí),為源語(yǔ)言詞選擇對(duì)應(yīng)的目標(biāo)語(yǔ)言詞。詞譯文選擇的好壞決定了機(jī)器翻譯系統(tǒng)的質(zhì)量。Gale等人[1]應(yīng)用基于大型英法對(duì)齊語(yǔ)料庫(kù)的統(tǒng)計(jì)方法,對(duì)6個(gè)常見(jiàn)的歧義詞的消歧正確率在82%~86%。劉小虎建立多上下文特征的詞義消歧統(tǒng)計(jì)模型,對(duì)歧義詞“interest”消歧測(cè)試的正確率達(dá)到80%[2];而通過(guò)在英漢機(jī)譯系統(tǒng)的譯文選擇中引入改進(jìn)的ID3機(jī)器學(xué)習(xí)方法[3],歧義詞“interest”消歧測(cè)試的正確率可達(dá)到91%,荀恩東[4]在譯文選擇中使用以消歧矩陣為計(jì)算背景的貪心算法。Dagan[5]等人提出利用目標(biāo)語(yǔ)同現(xiàn)統(tǒng)計(jì)消除源語(yǔ)言歧義的思想。哈爾濱工業(yè)大學(xué)BT863-2英漢機(jī)譯系統(tǒng)繼承Dagan的思想,譯文選擇的正確率為75%。術(shù)語(yǔ)相關(guān)性計(jì)算的研究比較典型,有EMMI weighting measure[6]、Term Similarity[7-9],本文方法與參考文獻(xiàn)[10]中提出的查詢翻譯中用到的方法有些相似。
1 譯文選擇模型
Ballesteros和Croft[8]認(rèn)為對(duì)語(yǔ)料庫(kù)進(jìn)行共現(xiàn)頻率的統(tǒng)計(jì)有助于消除翻譯的歧義問(wèn)題。他們假定正確的翻譯更可能在同一個(gè)目標(biāo)句子中共現(xiàn),否則相反。參考文獻(xiàn)[7-9]也使用相類似的方法選擇最佳的詞語(yǔ)翻譯。
正是因?yàn)楦鱾€(gè)詞之間的關(guān)系不是相互獨(dú)立的,本文提出詞語(yǔ)相關(guān)性和翻譯概率相結(jié)合的方法來(lái)選擇相應(yīng)的詞語(yǔ)翻譯,而不是逐詞孤立地翻譯。當(dāng)翻譯一個(gè)詞語(yǔ)時(shí),其他待翻譯詞的候選翻譯會(huì)成為它的上下文信息,這是本文進(jìn)行翻譯選擇的原則。給定一個(gè)待翻譯的英文詞語(yǔ)的集合,通過(guò)貪心算法和下文中的公式(5)找到每個(gè)詞的正確譯文。
例如,輸入NP(Noun Phrase):IC card intelligent door lock。
在本文的雙語(yǔ)詞典中,“intelligent”對(duì)應(yīng)的翻譯候選有:(1) 智能?chē)?guó);(2) 智力。依次類推本例中的目標(biāo)集合T為{“IC”,“卡”,“門(mén)”,“通道”,“鎖”,“鎖頭”}。目標(biāo)集合的獲得是通過(guò)在雙語(yǔ)詞典中查找每個(gè)源語(yǔ)言詞對(duì)應(yīng)的漢語(yǔ)翻譯候選組成的集合。通過(guò)公式(1)~(3)[11]計(jì)算,找到最可能的目標(biāo)翻譯,上例計(jì)算得到的翻譯結(jié)果為“IC 卡 智能 門(mén) 鎖”。
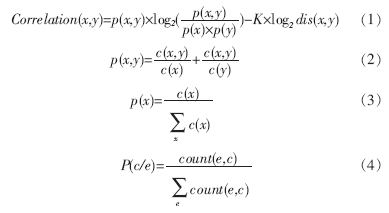

具體算法如圖1所示。

2 實(shí)驗(yàn)結(jié)果及分析
本文將翻譯概率加入到公式(1)中,結(jié)合翻譯概率與互信息來(lái)進(jìn)行譯文的選擇,對(duì)比實(shí)驗(yàn)結(jié)果可知,翻譯概率對(duì)翻譯結(jié)果有較大的提高。
為了充分證明該結(jié)果,從英漢術(shù)語(yǔ)實(shí)例庫(kù)中,隨機(jī)挑選500個(gè)實(shí)例進(jìn)行對(duì)比測(cè)試,采用NIST發(fā)布的最新版本mteval-v11b.pl作為自動(dòng)翻譯結(jié)果的評(píng)測(cè)工具,實(shí)驗(yàn)結(jié)果的曲線圖如圖2所示。

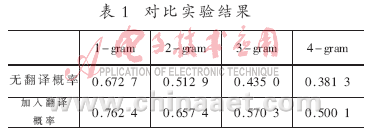
從表1中可以看出,加入翻譯概率后,從1-gram到4-gram的BLEU值都有所提高。為了更加清楚地顯示其對(duì)比效果,可以參見(jiàn)圖2。
舉一具體實(shí)例來(lái)說(shuō)明上面原因。例如:輸入NP:Safety non-tipping mosquito incense device,在不加入翻譯概率時(shí),只通過(guò)公式(1)計(jì)算得出翻譯結(jié)果為:“安全不倒蚊蚊扣掣座”。
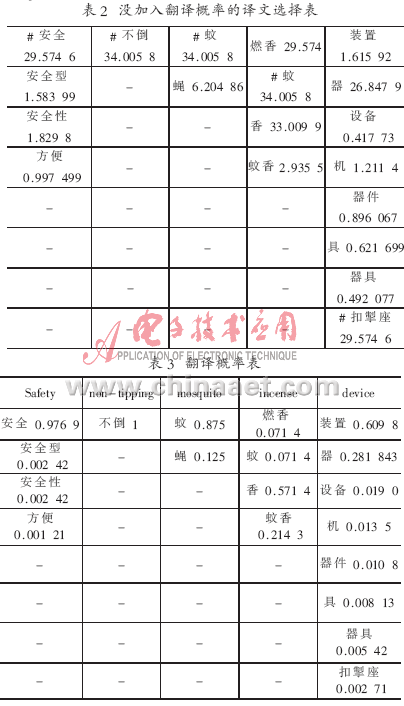
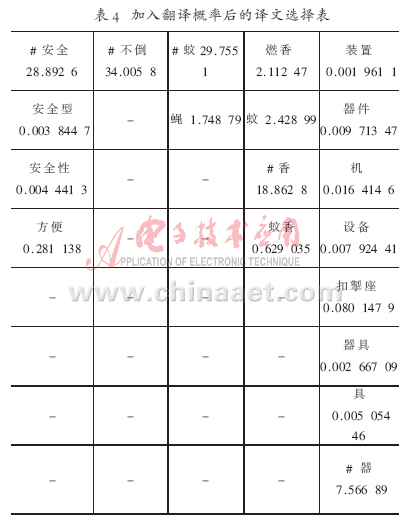
分析其原因,從表2可知,在沒(méi)有加入翻譯概率之前,通過(guò)公式(2)計(jì)算,“incense”選擇了“蚊”這個(gè)譯文,因?yàn)?ldquo;蚊”的值最大,如表3所示。在加入翻譯概率改進(jìn)之后,通過(guò)公式(5)計(jì)算,結(jié)果如表2所示,由于其翻譯概率很小,因此就會(huì)選擇到更合適的譯文“香”。(“#”表示選擇的譯文)根據(jù)表4,正確的譯文為:“安全 不倒 蚊 香 器”。
譯文選擇的好壞是機(jī)器翻譯質(zhì)量提高的關(guān)鍵。本文提出的改進(jìn)互信息的譯文選擇方法,其中對(duì)互信息的理論作了簡(jiǎn)單介紹,對(duì)譯文選擇的相關(guān)研究也進(jìn)行了簡(jiǎn)單描述。通過(guò)對(duì)比實(shí)驗(yàn)分析證明了該方法在已有的互信息方法上加入翻譯模型特征后,翻譯效果得到顯著地提高,BLEU值提高了0.1左右。
參考文獻(xiàn)
[1] WILLIAM G, KENNETH C, DAVID Y. Using bilingual materials to develop word sense disambiguation methods[C]. The 4th Int’l Conf on Theoretical and Methodological Issues in Machine Translation, Montreal, Canada, 1992.
[2] LIU Xiao Hu, Li Sheng , Zhao Tie Jun . Statistical model selection for word sense disambiguation(in Chinse)[J]. Communications of Chinese and Oriental Languages Information Processing Society, 1997, 7(2): 69-75.
[3] 劉小虎. 英漢機(jī)器翻譯中詞義消歧的研究[M]. 哈爾濱:哈爾濱工業(yè)大學(xué), 1997.
[4] 荀恩東, 李生, 趙鐵軍. 基于漢語(yǔ)二元同現(xiàn)的統(tǒng)計(jì)詞義消歧方法研究[J].高技術(shù)通訊, 1998, 10(8): 21-25.
[5] DAGAN, LILLIAN L, FERNANDO P. Similarity-based models of cooccurrence probabilities[J]. Machine Learning, Special Issue on Natural Language Learning, 1999, 34(1-3): 43-69.
[6] RIJSBERGEN V . Information retrieval[J]. 2nd ed. Butterworths, London, 1979.
[7] ADRIANI M. Using statistical term similarity for sense disambiguation in cross-language information Retrieval[C]. Information Retrieval, 2000,2: 69-80.
[8] BALLESTEROS L, CROFT W B Resolving ambiguity for cross-language retrieval[C]. In Proceedings of the 21st International Conference on Research and Development in Information Retrieval,1998.
[9] BALLESTEROS L , CROFT W B. Phrasal translation and query expansion techniques for cross-language information retrieval[C]. In: Proceedings of the 20th International Conference on Research and Development in Information Retrieval, 1997: 84-91.
[10] GAO J F , NIE J Y. A study of statistical models for query translation:finding a good unit of translation[C]. In SIGIR, 2006.
[11] GAO Jian Feng, NIE Jian Yun, ZHANG Jian, et al. Improving query translation for cross-language information retrieval using statistical models[C]. In SIGIR’01, NewOrleans, Louisiana, 2001: 96-104.