
摘 要: 對搜索引擎個性化服務(wù)技術(shù)中的用戶描述文檔、資源描述文檔、個性化推薦技術(shù)、個性化服務(wù)體系結(jié)構(gòu)以及該領(lǐng)域的主要研究成果進行了綜述。通過比較現(xiàn)有原型系統(tǒng)的實現(xiàn)方式,詳細討論了實現(xiàn)個性化服務(wù)的關(guān)鍵技術(shù)。
關(guān)鍵詞: 數(shù)據(jù)挖掘;搜索引擎;個性化;網(wǎng)絡(luò)資源
隨著網(wǎng)絡(luò)的迅猛發(fā)展,互聯(lián)網(wǎng)已成為人們獲得信息的重要手段[1]。海量信息在給人們帶來方便的同時也帶來了許多問題。人們經(jīng)常要耗費大量寶貴的時間在大量組織松散的信息中尋找有用信息,因此搜索引擎網(wǎng)上檢索信息的重要工具[2-3]越來越流行。如何準確高效地為用戶提供需要的信息,是搜索引擎信息推薦研究的核心[4]。在搜索引擎中提供個性化服務(wù)技術(shù)就是針對這個問題而提出的,它為不同用戶提供不同的服務(wù),以滿足不同的需求。個性化服務(wù)通過收集和分析用戶信息來學(xué)習(xí)用戶的興趣和行為,達到主動推薦的目的。個性化服務(wù)技術(shù)能充分提高站點的服務(wù)質(zhì)量和訪問效率,從而吸引更多的訪問者[5]。個性化服務(wù)系統(tǒng)根據(jù)其所采用的推薦技術(shù)可以分為2種:基于規(guī)則的系統(tǒng)和信息過濾系統(tǒng)。信息過濾系統(tǒng)又可分為基于內(nèi)容過濾的系統(tǒng)和協(xié)同過濾系統(tǒng)[6]。
基于規(guī)則的系統(tǒng),如IBM的WebSphere,其優(yōu)點是簡單、直接,缺點是規(guī)則質(zhì)量很難保證,而且不能動態(tài)更新。此外,系統(tǒng)隨著規(guī)則的數(shù)量增多,變得越來越難以管理。基于內(nèi)容過濾的系統(tǒng)有:PersonalWebWatcher,Letizia等[7],其優(yōu)點是簡單、有效,缺點是難以區(qū)分資源內(nèi)容的品質(zhì)和風(fēng)格,而且不能為用戶發(fā)現(xiàn)新的感興趣的資源,只能發(fā)現(xiàn)與用戶已有興趣相似的資源[8]。協(xié)同過濾系統(tǒng)如WebWatcher、GroupLens等,其優(yōu)點是能為用戶發(fā)現(xiàn)新的感興趣的信息,缺點是存在2個很難解決的問題:一個是稀疏性,亦即在系統(tǒng)使用初期,由于系統(tǒng)資源還未獲得足夠多的評價,很難利用這些評價來發(fā)現(xiàn)類似的用戶;另一個是可擴展性,隨著用戶和資源的增多,系統(tǒng)的性能會越來越低[9]。還有一些個性化服務(wù)系統(tǒng)如WebSIFT、FAB等,結(jié)合了基于內(nèi)容過濾和協(xié)同過濾2種技術(shù)。為了克服協(xié)同過濾的稀疏性問題,可以利用用戶瀏覽過的資源內(nèi)容預(yù)期用戶對其他資源的評價,這樣可以增加資源評價的密度。利用這些評價再進行協(xié)同過濾,從而提高協(xié)同過濾的性能[10]。
1 國內(nèi)外的研究現(xiàn)狀
為了實現(xiàn)個性化服務(wù),首先需要跟蹤和學(xué)習(xí)用戶的行為和興趣,并設(shè)計一種合適的表達方式。必須組織好資源,選取資源特征,采用合適的推薦方式。此外還必須考慮系統(tǒng)的體系結(jié)構(gòu),以及在服務(wù)器端、客戶端和代理端實現(xiàn)的利弊。
1.1 用戶描述文檔
在個性化服務(wù)系統(tǒng)來說,最重要的是用戶的參與,有必要為每個用戶建立一個用戶描述文檔(user profile)。用戶描述文檔用來刻畫用戶特征,在制定用戶描述文檔之前,需考慮下面幾個問題[11]:
(1)描述文檔有沒有現(xiàn)成的標準?
(2)收集什么數(shù)據(jù)?收集數(shù)據(jù)的目的?
(3)如何收集數(shù)據(jù)?根據(jù)什么信息源來收集?
(4)收集的數(shù)據(jù)如何組織?
(5)可自適應(yīng)用戶信息進行更新?
在收集用戶的信息之前,首先需分析用戶愿意提供什么信息。用戶一般都很注意個人信息的保密性,調(diào)查顯示,83%的用戶愿意向Web站點提供自己的姓名、性別、年齡、教育背景和興趣,但大多數(shù)用戶不愿意提供私有、敏感的信息,如個人收入和信用卡號等。另一項調(diào)查顯示,39%的用戶愿意Web站點向其他Web站點共享自己的信息。
1.2 資源描述文檔
個性化服務(wù)系統(tǒng)處理的資源是由其應(yīng)用范圍確定的[12]。Anatagonomy、SmartPush應(yīng)用的范圍是報紙;GroupLens應(yīng)用的范圍是Usenet新聞;CiteSeer應(yīng)用的范圍是科技文檔;FireFly應(yīng)用的范圍是音樂和電影;Amazon.com、eBay應(yīng)用的范圍是電子商務(wù)。還有一些個性化服務(wù)系統(tǒng)用于導(dǎo)航、推薦、幫助或搜索,但它們所處理的資源不太相同,如Personal WebWatcher、WebWatcher、Letizia處理Web頁與鏈接;WebSIFT處理Web訪問日志;SiteSeer、PowerBookmark處理BookMark和相關(guān)文檔;Syskill & Webert、ProFusion處理從其他搜索引擎返回的查詢結(jié)果等。目前,個性化服務(wù)系統(tǒng)所處理的資源都是文本資源,F(xiàn)ireFly面向音樂和電影,其通過用戶評價喜歡的音樂家和電影來進行協(xié)同過濾,所以仍然屬于文本處理。資源的描述與用戶的描述密切相關(guān),通常是用同樣的機制來表達用戶和資源。資源描述文檔可以用基于內(nèi)容的方法和基于分類的方法來表示[13]。
(1)基于內(nèi)容的方法
基于內(nèi)容的方法是從資源本身抽取信息來表示資源,使用最廣泛的方法是用加權(quán)關(guān)鍵詞矢量。這種方法的關(guān)鍵的問題是特征選取,特征選取要達到2個目標:一是選取最好的詞;二是選取最少的詞。要抽取特征詞條,需要利用停用詞列表對文檔進行詞的切分,在完成詞切分后,接著除去文檔集中出現(xiàn)次數(shù)過少和過多的詞。經(jīng)過這些處理后,還需對特征進行進一步的選取,以降低特征的維數(shù)。常用的特征選擇方法有:信息熵(entropy)、信息增益(IG)、互信息(MI)、X2統(tǒng)計方法(CHI)、TF-IDF方法等。比較簡單的做法就是計算每個特征的熵值,選取具有最大熵值的若干個特征,即信息量最大的若干個特征;也可以計算每個特征的信息增量,即每個特征在文檔中出現(xiàn)前后的信息熵之差;還可以計算每個特征的互信息即每個特征和文檔的相關(guān)性;還可使用X2統(tǒng)計方法。以上的計算方法中,信息增量方法和X2統(tǒng)計方法表現(xiàn)較好,但這兩種方法的計算量比較大。在完成文檔特征的選取后,還要計算每個特征的權(quán)值,使用最廣泛的是TFIDF方法,其思想是出現(xiàn)次數(shù)越多且罕見的詞匯越能代表文檔內(nèi)容,具有很好的類別區(qū)分能力,適合用來分類。對某一特征,TF表示該特征在文檔中出現(xiàn)的次數(shù),某一特定詞語的IDF,可以由總文檔數(shù)目除以包含該詞語之文檔的數(shù)目,再將得到的商取對數(shù)。矢量模型的代價是比較大的,有時為了加快處理速度,可以只考慮TF一項,矢量模型在只考慮TF,IDF以及沒有考慮TF和IDF時都使效果顯著下降。在資源描述中特征選擇非常重要,一個合理、有效的特征選擇方法可以在信息處理階段去掉數(shù)據(jù)中的冗余,降低特征空間的維數(shù),提高效率。
(2)基于分類的方法
基于分類的方法是利用類別來表示資源,在給定的分類體系下,根據(jù)內(nèi)容確定所屬類別的過程。對文檔資源進行分類有利于將文檔推薦給對該類文檔感興趣的用戶。文本分類方法有多種,常用的有K近鄰法(kNN),樸素貝葉斯(Na?觙ve-Bayes)和支持向量機(Support Vector Machines)等。K近鄰法是一種簡單而常用的文本分類方法。該方法的思想是給定一個經(jīng)過分類的訓(xùn)練文檔集合,在對新文檔進行分類時,首先從訓(xùn)練文檔集合中找出與測試文檔最相關(guān)的k篇文檔,然后按照這k篇文檔所屬的類別來對該測試文檔進行分類處理。樸素貝葉斯方法將概率模型應(yīng)用于自動分類,是種簡單而有效的分類方法。它的分類思想是使用貝葉斯公式通過先驗概率和類別的條件概率來估計文檔對類別的后驗概率。支持向量機的理論基礎(chǔ)是統(tǒng)計學(xué)習(xí)理論,作為一種相對較新的通用機器學(xué)習(xí)方法,最近十年來成為自動分類領(lǐng)域的研究和應(yīng)用熱點。資源的類別可以預(yù)先定義,也可以利用聚類技術(shù)自動產(chǎn)生。許多研究表明:聚類在精度上非常依賴于文檔的數(shù)量,而且由聚類產(chǎn)生的類型可能對用戶來說是毫無意義的,因此可以先使用手工選定的類型來分類文檔,在沒有對應(yīng)的候選類型或需要進一步劃分某類型時,才使用聚類產(chǎn)生的類型。
1.3 個性化推薦
個性化推薦目前大多采用基于規(guī)則的技術(shù)、基于內(nèi)容過濾的技術(shù)和協(xié)同過濾技術(shù)。
(1)基于規(guī)則的技術(shù)
規(guī)則可以由用戶定制,也可以使用基于關(guān)聯(lián)規(guī)則的挖掘技術(shù)來發(fā)現(xiàn),基于規(guī)則的推薦信息依賴于規(guī)則的質(zhì)量和數(shù)量,其缺點是隨著規(guī)則的數(shù)量增多,系統(tǒng)將變得越來越難以管理。規(guī)則本質(zhì)上是一個If-Then語句,它可以利用用戶靜態(tài)屬性或動態(tài)信息來建立。為了能夠使用規(guī)則來推薦資源,用戶描述文檔和資源描述文檔需用相同的關(guān)鍵詞集合進行描述。信息推薦時的工作過程為:首先根據(jù)當(dāng)前用戶閱讀過的感興趣的內(nèi)容,通過規(guī)則推算出用戶還沒有閱讀過的感興趣的內(nèi)容,然后根據(jù)規(guī)則的支持度,對這些內(nèi)容排序并展現(xiàn)給用戶。基于規(guī)則的系統(tǒng)組成如圖1所示。
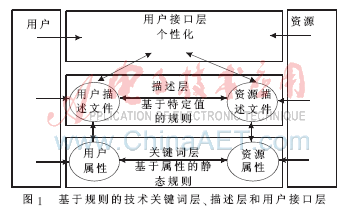
關(guān)鍵詞層提供上層描述所需的關(guān)鍵詞,并定義關(guān)鍵詞間的依賴關(guān)系,該層可以定義靜態(tài)屬性的個性化規(guī)則。描述層定義用戶描述和資源描述,由于描述層是針對具體的用戶和資源,所以描述層的個性化規(guī)則是動態(tài)變化的。用戶接口層提供個性化服務(wù),根據(jù)下面2層定義的個性化規(guī)則將滿足規(guī)則的資源推薦給用戶。
(2)信息過濾技術(shù)
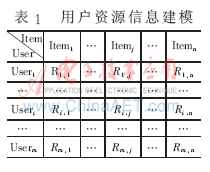
信息過濾技術(shù)可分為基于內(nèi)容過濾的技術(shù)和協(xié)同過濾技術(shù)[15-16]。基于內(nèi)容過濾的系統(tǒng),如PersonalWebWatcher、Letizia等,它們利用資源與用戶興趣的相似性來過濾信息。其優(yōu)點是簡單、有效,缺點是難以區(qū)分資源內(nèi)容的品質(zhì)和風(fēng)格,而且不能為用戶發(fā)現(xiàn)新的感興趣的資源,只能發(fā)現(xiàn)和用戶已有興趣相似的資源。協(xié)同過濾系統(tǒng),如WebWatcher、GroupLens等,它們利用用戶之間的相似性來過濾信息,優(yōu)點是能為用戶發(fā)現(xiàn)新的感興趣的信息,缺點是存在2個很難解決的問題。一個是稀疏性,即在系統(tǒng)使用初期由于系統(tǒng)資源還未獲得足夠多的評價,系統(tǒng)很難利用這些評價來發(fā)現(xiàn)相似的用戶;另一個是可擴展性,即隨著系統(tǒng)用戶和資源的增多,系統(tǒng)的性能會越來越低。還有一些個性化服務(wù)系統(tǒng),如WebSIFT、FAB等,同時采用了基于內(nèi)容過濾和協(xié)同過濾這2種技術(shù)。這2種過濾技術(shù)結(jié)合可以克服各自的一些缺點,利用用戶瀏覽預(yù)期用戶對其他資源的評價,增加資源評價的密度克服協(xié)同過濾的稀疏性問題,利用這些評價再進行協(xié)同過濾,從而提高協(xié)同過濾的性能。用戶與資源的關(guān)系數(shù)據(jù)可以用m×n階矩陣來表示,m代表用戶數(shù)量,n代表項目數(shù)量,Rij代表第i個用戶對項目j的評分。用戶資源信息建模如表1。
1.4 個性化服務(wù)體系結(jié)構(gòu)
基于Web的個性化服務(wù)體系結(jié)構(gòu)與用戶描述文檔分布的位置有很大關(guān)系。用戶描述文檔可以存儲在服務(wù)器端、客戶端、代理端[17-18]。大部分個性化服務(wù)系統(tǒng)的用戶描述文檔都存放在服務(wù)器端,如Syskill&Webert、Letizia、GroupLens、Anatagonomy等。優(yōu)點是可以避免用戶描述文檔的傳輸,除了支持基于內(nèi)容的過濾,還可以支持協(xié)同過濾;缺點是用戶描述文檔不能在不同的Web應(yīng)用之間共享。也有一些系統(tǒng)的用戶描述文檔是存儲在客戶端的,如PointCast Network,這種體系的個性化服務(wù)可以在服務(wù)器端實現(xiàn),也可以在客戶端實現(xiàn)。它的優(yōu)點是用戶描述文檔可以在不同的應(yīng)用之間共享,缺點是只能進行基于內(nèi)容的過濾。還有一些系統(tǒng)的用戶描述文檔是存儲在代理上的,如Personal WebWatcher、PVA等,這種體系的個性化服務(wù)可以在服務(wù)器端實現(xiàn),也可以在代理上實現(xiàn)。其優(yōu)點是不僅可以支持基于內(nèi)容的過濾和協(xié)同過濾,還支持用戶描述文檔在不同Web應(yīng)用之間的共享;缺點是可能需要傳輸用戶描述文檔。
2 關(guān)鍵問題
(1)綜合各系統(tǒng)優(yōu)點
基于規(guī)則的系統(tǒng)其優(yōu)點是簡單、直接,缺點是規(guī)則質(zhì)量很難保證,不能動態(tài)更新。此外,隨著規(guī)則的數(shù)量增多,系統(tǒng)將變得越來越難以管理。基于內(nèi)容過濾的系統(tǒng)其優(yōu)點是簡單、有效,缺點是難以區(qū)分資源內(nèi)容的品質(zhì)和風(fēng)格,而且不能為用戶發(fā)現(xiàn)新的感興趣的資源,只能發(fā)現(xiàn)和用戶已有興趣相似的資源。基于協(xié)同過濾系統(tǒng)的優(yōu)點是能為用戶發(fā)現(xiàn)新的感興趣的信息,缺點是它的稀疏性和可擴展性,結(jié)合基于內(nèi)容的過濾和協(xié)同過濾這兩種技術(shù)可以克服各自的缺點,可以利用用戶的瀏覽記錄推測用戶對其他資源的評價,增加資源評價的密度,來克服協(xié)同過濾的稀疏性問題。利用這些評價進行協(xié)同過濾,從而提高協(xié)同過濾的性能。
(2)用戶描述文檔的存放
用戶描述文檔可以存放在服務(wù)器端、客戶端、代理端,大部分個性化服務(wù)系統(tǒng)的用戶描述文檔都存放在服務(wù)器端。其優(yōu)點是可以避免用戶描述文檔的傳輸,支持基于內(nèi)容的過濾和協(xié)同過濾;缺點是用戶描述文檔不能在不同的Web應(yīng)用之間共享。用戶描述文檔存儲在客戶端,優(yōu)點是用戶描述文檔可以在不同的Web應(yīng)用之間共享,缺點是只能進行基于內(nèi)容的過濾。用戶描述文檔存儲在代理上,優(yōu)點是不僅可以支持基于內(nèi)容的過濾和協(xié)同過濾,還支持用戶描述文檔在不同的Web應(yīng)用之間共享,缺點是需要傳輸用戶描述文檔。
(3)為推薦文檔評分和排名
個性化服務(wù)技術(shù)是目前非常流行的一種技術(shù),本文分析了各種具有代表性的個性化服務(wù)系統(tǒng),并在此基礎(chǔ)上詳細描述了建立個性化服務(wù)的關(guān)鍵技術(shù)。要將個性化服務(wù)引入搜索引擎中,面對日益增長的Web信息,要滿足不同背景、不同目的和不同時期的查詢請求,必須針對不同用戶提供不同的服務(wù)才能真正解決這個問題。個性化服務(wù)技術(shù)在搜索引擎上仍有很多值得研究和探討的問題。
參考文獻
[1] PRETSCHNER A. Ontology based personalized search[MS. Thesis]. Lawrence, KS: University of Kansas, 1999.
[2] LEE D L, CHUANG H, SEAMONS K. Document ranking and the vector-space model. IEEE Softwar, 1997,14(2).
[3] XUE Gui Rong, LIN Chen Xi. Scalable collaborative filtering using cluster-based. In: Hong Kong University of Science and Technology, ACM, 2005.
[4] Jun Wang, Arjen P. de Vries, Marce J. T. Reinders1: unifying user-based and item-based collaborative filtering approaches by similarity fusion. Faculty of Electrical Engineering, Mathematics and Computer Science, Delft University of Technology, ACM, 2006.
[5] 曾春,邢春曉,周立柱.基于內(nèi)容過濾的個性化搜索算法[J].軟件學(xué)報,2003,14(5):999-1004.
[6] 曾春,邢春曉,周立柱.個性化服務(wù)技術(shù)綜述[J].軟件學(xué)報,2002,13(10):1952-1961.
[7] 劉均,李人厚.一種面向個性化協(xié)同學(xué)習(xí)的任務(wù)生成方法[J].軟件學(xué)報,2006,17(1).
[8] 陳健,印鑒.基于影響集的協(xié)同過濾推薦算法.軟件學(xué)報[J],2007,18(7).
[9] 韓立新,陳貴海,謝立.一個面向Internet的個性化信息檢索系統(tǒng)模型[J].電子學(xué)報,2002,30(2).
[10] 邢春曉,高鳳榮,戰(zhàn)思南,等.適應(yīng)用戶興趣變化的協(xié)同過濾推薦算法[J].計算機研究與發(fā)展,2007,44(2).
[11] 張鋒.使用BP神經(jīng)網(wǎng)絡(luò)緩解協(xié)同過濾推薦算法的稀疏性問題[J].計算機研究與發(fā)展,2006,43(4).
[12] SRIVASTAVA J, COOLEY R, DESHPANDE M, et al. Web usage mining: discovery and applications of usage patterns from Web data. In:Fayyad, U., ed. Proceedings of the ACM SIGKDD Explorations. New York: ACM Press, 2000,1(2):12-23.
[13] 趙亮,胡乃靜,張守志.個性化推薦算法設(shè)計[J].計算機研究與發(fā)展,2002,39(8):986-991.
[14] 汪曉巖,胡慶生.面向Internet的個性化智能信息檢索[J].計算機研究與發(fā)展,1999,36(9):1039-1046.
[15] VOLOKH E. Personalization and privacy[J]. Communications of the ACM, 2000,43(8):84-88.
[16] WU Y H, CHEN Y C, CHEN A L P. Enabling personalized recommendation on the web based on user interests and behaviors. In:Klas, W., ed. Proceedings of the 11th International Workshop on Research Issues in Data Engineering. Los Alamitos, CA: IEEE CS Press, 2001.
[17] 沈云斐,沈國強,蔣麗華,等.基于時效性的Web頁面?zhèn)€性化推薦模型的研究[J].計算機工程,2006,32(13):80-81,99.
[18] 秦國,杜小勇.基于用戶層次信息的協(xié)同推薦算法[J].計算機科學(xué),2004,31(10):138-140.