
1 概 述
由于串口在電報通信、工控和數(shù)據(jù)采集等領(lǐng)域有著廣泛的應(yīng)用,絕大多數(shù)嵌入式處理器都內(nèi)置了通用異步收發(fā)器(UART)。UART數(shù)據(jù)傳輸主要通過中斷或DMA的方式實現(xiàn)。
中斷方式是在接收到數(shù)據(jù)或需要發(fā)送數(shù)據(jù)時產(chǎn)生中斷,在中斷服務(wù)程序中讀寫UART的緩沖區(qū)(FIFO)實現(xiàn)數(shù)據(jù)傳輸。由于串口通信速率一般比較低(典型值不超過115 200 bps),大多數(shù)嵌入式系統(tǒng)都采用中斷方式來傳輸串口數(shù)據(jù)。然而,中斷服務(wù)程序需要占用CPU的時間,而串口速度的提升也必將導(dǎo)致CPU更頻繁地響應(yīng)UART中斷,這勢必會造成嵌入式系統(tǒng)的性能下降。
DMA數(shù)據(jù)傳輸無需CPU的參與,是一種更加高效的數(shù)據(jù)傳輸方式。現(xiàn)有的DMA數(shù)據(jù)傳輸方案都是基于DMA塊傳輸方式(即Block DMA)。這種方式下每次傳輸完一個數(shù)據(jù)塊后產(chǎn)生一個DMA中斷,在高速串口通信中,頻繁的DMA中斷仍然會影響系統(tǒng)的性能。本文基于散列DMA(seatter DMA)的傳輸方式提出了一套完整的工業(yè)級高速串口驅(qū)動設(shè)計方案,實現(xiàn)了波特率高達12 Mbps的UART數(shù)據(jù)傳輸。
2 DMA數(shù)據(jù)傳輸?shù)奶攸c
DMA(Direct Memory Access,直接存儲器訪問),是指數(shù)據(jù)在內(nèi)存與I/O設(shè)備間的直接傳輸,數(shù)據(jù)操作由DMA控制器(DMAC)完成而不需要CPU的參與,大大提高了CPU的利用率。因此,DMA是高速數(shù)據(jù)傳輸?shù)睦硐敕绞健@肈MA進行數(shù)據(jù)傳輸時應(yīng)注意以下幾點:
①DMA傳輸需要占用系統(tǒng)總線,在此期間CPU不能使用總線。如果外設(shè)在進行數(shù)據(jù)傳輸時不能有任何的間斷,就必須保證傳輸期間DMAC對系統(tǒng)總線的獨占,這可能會影響其他需要使用總線進行數(shù)據(jù)傳輸?shù)脑O(shè)備。所以,系統(tǒng)總線在DMA傳輸期間是否可被搶占,要依據(jù)嵌入式系統(tǒng)的特定環(huán)境來決定。
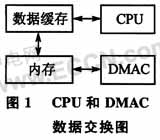
②DMA傳輸存在緩存一致性(cache coherency)問題。如圖1所示,DMAC和CPU是兩個平行的單元,CPU總是通過數(shù)據(jù)緩存來訪問內(nèi)存中的數(shù)據(jù),而DMAC則直接訪問內(nèi)存。如果內(nèi)存中的數(shù)據(jù)被DMAC更新,而數(shù)據(jù)緩存中的數(shù)據(jù)尚未被更新,CPU獲得的某些地址的值可能并不是內(nèi)存中的真實值。為了避免這個問題,可在DMAC更新完內(nèi)存數(shù)據(jù)后或CPU讀取被更新過的數(shù)據(jù)前刷新數(shù)據(jù)緩存,或是使用不被數(shù)據(jù)緩存映射的非緩存(non-cacheable)內(nèi)存區(qū)域。
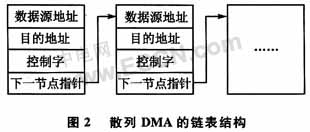
DMA數(shù)據(jù)傳輸可分為塊傳輸和散列傳輸兩種方式。在DMA傳輸數(shù)據(jù)的過程中,要求源物理地址和目標(biāo)物理地址必須是連續(xù)的。但是在某些計算機體系中(如IA架構(gòu)),連續(xù)的存儲器地址在物理上不一定是連續(xù)的,所以DMA傳輸要分成多次完成。傳輸完一塊物理上連續(xù)的數(shù)據(jù)后引發(fā)一次中斷,然后進行下一塊物理上連續(xù)的數(shù)據(jù)傳輸,這就是DMA塊傳輸方式(Block DMA)。散列傳輸是在塊傳輸方式上發(fā)展起來的,它與一個傳輸鏈表相關(guān),如圖2所示。該鏈表可以是單向結(jié)構(gòu)或環(huán)形結(jié)構(gòu)。控制字中包含數(shù)據(jù)位寬、數(shù)據(jù)塊大小、當(dāng)前塊傳輸結(jié)束是否引發(fā)中斷等控制信息。DMA塊傳輸可看作是只含有一個節(jié)點,且下一節(jié)點指針總是指向當(dāng)前節(jié)點的散列傳輸。采用散列DMA方式能更靈活、高效地傳輸數(shù)據(jù)。
3 在SPEAR300平臺上實現(xiàn)高速串口
3.1 硬件平臺
SPEAR300是ST公司在ARM926EJ-S核的基礎(chǔ)上開發(fā)的高性能嵌入式處理器。其最高工作頻率為333MHz,有8個獨立的DMA通道,支持散列DMA;UART支持DMA傳輸,發(fā)送和接收FIFO大小均為16字節(jié),在192 MHz的外設(shè)總線(APB)頻率下支持的最高波特率為12 Mbps,如果提高APB的頻率還可以獲得更高的波特率。本文的硬件平臺是以SPEAR300為核心的人機界面產(chǎn)品,主要外設(shè)包括觸摸屏、液晶顯示模組、網(wǎng)口和串口(串口要支持最高波特率為12 Mbps的西門子MPI通信協(xié)議)。
3.2 驅(qū)動程序設(shè)計
串口驅(qū)動程序的核心是實現(xiàn)數(shù)據(jù)高效穩(wěn)定的收發(fā)。為了實現(xiàn)UART的高速數(shù)據(jù)傳輸,UART中斷設(shè)置為最高優(yōu)先級;同時在操作系統(tǒng)中允許中斷嵌套,打開UART接收超時中斷RTI并使能UART的DMA傳輸。這樣,當(dāng)UART的發(fā)送FIFO數(shù)據(jù)減少到設(shè)定的參考值(FIFOLevel)時,發(fā)送DMA傳輸就會被觸發(fā)。同樣,當(dāng)接收FIFO的數(shù)據(jù)增長到設(shè)定值時,接收DMA傳輸就會被觸發(fā)。為了減少DMA傳輸被觸發(fā)的次數(shù)同時保證數(shù)據(jù)被及時傳輸,發(fā)送FIFO Level設(shè)定為2字節(jié),而接收FIFOLevel設(shè)定為14字節(jié),將發(fā)送和接收的FIFO Level分別設(shè)定為0和16字節(jié)是有很大風(fēng)險的。MPI協(xié)議要求傳輸?shù)囊粠瑪?shù)據(jù)不能有間斷,所以在使用DMA傳輸UART數(shù)據(jù)時DMAC必須獨占系統(tǒng)總線。為了避免產(chǎn)生緩存一致性問題,使用2塊非緩存內(nèi)存區(qū)域存放待發(fā)送的數(shù)據(jù)和已接收到的數(shù)據(jù)。
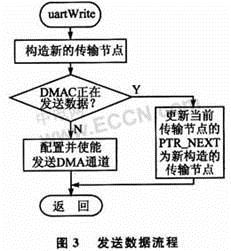
發(fā)送數(shù)據(jù)時,待發(fā)送的數(shù)據(jù)量總是已知的。先構(gòu)造一個傳輸節(jié)點,數(shù)據(jù)源地址為數(shù)據(jù)包的首地址,目的地址為UART寄存器,數(shù)據(jù)位寬為8,下一節(jié)點指針(PTR_NEXT)為空。當(dāng)前數(shù)據(jù)包發(fā)送結(jié)束前,如果PTR_NEXT被更新,則下一個數(shù)據(jù)包的傳輸自動開始。當(dāng)前數(shù)據(jù)包是否發(fā)送完畢,可通過讀取DMAC寄存器DMACCnControl的TransferSize字段得知。整個發(fā)送數(shù)據(jù)的過程無需觸發(fā)任何中斷,流程圖如圖3所示。如果采用DMA塊傳輸方式,就需要在每次傳輸完畢后產(chǎn)生DMA中斷,重新裝載數(shù)據(jù)到內(nèi)存中的發(fā)送數(shù)據(jù)區(qū)以發(fā)送下一個數(shù)據(jù)包。
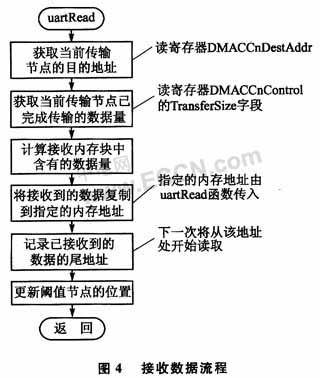
接收數(shù)據(jù)時,對方發(fā)過來的數(shù)據(jù)量一般是未知的。構(gòu)造含有100個節(jié)點的循環(huán)鏈表結(jié)構(gòu),每個節(jié)點對應(yīng)的傳輸塊大小為接收FIFO Level。數(shù)據(jù)源地址為UART數(shù)據(jù)寄存器的地址,首節(jié)點的目的地址為接收數(shù)據(jù)內(nèi)存區(qū)域的首地址,此后節(jié)點的目的地址每次向后偏移(FIFO Level×2)個字節(jié),數(shù)據(jù)位寬為16(8個數(shù)據(jù)位,4個狀態(tài)位,4個保留位)。當(dāng)接收到的數(shù)據(jù)達到接收內(nèi)存區(qū)域的80%(RECV_TH)時,需要通知數(shù)據(jù)發(fā)送方停止數(shù)據(jù)傳輸,在第80個節(jié)點處設(shè)置DMA中斷,該節(jié)點為閾值節(jié)點。采用本文的設(shè)計方案接收1幀不超過RECV_TH大小的數(shù)據(jù),最多產(chǎn)生一次RTI中斷。當(dāng)接收到的數(shù)據(jù)量少于FIFOLevel時不會觸發(fā)DMA接收,在RTI中斷中把UART接收FIFO中的數(shù)據(jù)復(fù)制到內(nèi)存中的數(shù)據(jù)接收區(qū),同時使DMA接收節(jié)點的目的地址向后偏移相應(yīng)的長度并更新閾值節(jié)點的位置。接收數(shù)據(jù)流程如圖4所示。如果采用DMA塊傳輸方式,就必須額外使用一個環(huán)形數(shù)據(jù)緩沖區(qū)(Ring Buffer),每次接收到指定大小的數(shù)據(jù)塊后產(chǎn)生DMA中斷,在中斷服務(wù)程序中將接收到的數(shù)據(jù)復(fù)制到環(huán)形數(shù)據(jù)緩沖區(qū)中。
3.3 驅(qū)動測試
本文的設(shè)計方案直接應(yīng)用于工業(yè)級的HMI產(chǎn)品,必須經(jīng)過嚴(yán)格的測試。利用3臺西門子S7系列PLC和1臺產(chǎn)品樣機搭建令牌網(wǎng),使用西門子MPI協(xié)議進行測試,并利用數(shù)據(jù)分析工具ProfiTrace監(jiān)測通信過程。測試結(jié)果表明,2 400 bps~12 Mbps的各個波特率下都能進行穩(wěn)定的數(shù)據(jù)通信。
結(jié) 語
本文詳細介紹了DMA數(shù)據(jù)傳輸?shù)奶攸c和散列DMA的工作方式。在此基礎(chǔ)上,提出了一套基于散列DMA的高速串口驅(qū)動設(shè)計方案,發(fā)送數(shù)據(jù)完全由DMAC完成,無需觸發(fā)任何中斷,接收1幀不超過接收區(qū)閾值的數(shù)據(jù)最多產(chǎn)生1次RTI中斷。和現(xiàn)有的各種利用DMA塊傳輸進行串口數(shù)據(jù)通信的方案相比,中斷次數(shù)大幅減少,大大提高了數(shù)據(jù)傳輸?shù)男省T趹?yīng)用了本方案的人機界面產(chǎn)品上,實現(xiàn)了波特率高達12 Mbps的穩(wěn)定數(shù)據(jù)傳輸。對于在其他平臺上設(shè)計實現(xiàn)高速串口,本方案是一個很好的參考。