
摘要:為滿足彈上信號處理領(lǐng)域不斷增長的任務(wù)需求并適應(yīng)不同的應(yīng)用場合,設(shè)計(jì)高性能通用并行計(jì)算機(jī),進(jìn)而構(gòu)建各類信號處理系統(tǒng)是一種趨勢。基于時(shí)共享總線和分布式兩種并行結(jié)構(gòu)的理論分析,結(jié)合信號處理系統(tǒng)的特點(diǎn),設(shè)計(jì)了一種高性能通用并行彈載計(jì)算機(jī),它具有標(biāo)準(zhǔn)化、模塊化、可擴(kuò)展、可重構(gòu)、混合并行模式、多層次互聯(lián)的特性,通過構(gòu)建典型彈載計(jì)算機(jī)驗(yàn)證了這些特性。
關(guān)鍵詞:彈載計(jì)算機(jī);并行處理;TS201;FPGA
0 引 言
隨著技術(shù)的發(fā)展,在導(dǎo)彈控制和通信等領(lǐng)域,需要處理的任務(wù)規(guī)模越來越大。雖然隨著VLSI技術(shù)的發(fā)展,已產(chǎn)生了運(yùn)算能力達(dá)每秒幾十億次的處理器,但還遠(yuǎn)遠(yuǎn)不能滿足這些領(lǐng)域的需求。而VLSI技術(shù)的發(fā)展已受到其開關(guān)速度的限制,進(jìn)一步提高處理器主頻遇到的困難越來越大。為此,把用于大型計(jì)算機(jī)的并行處理技術(shù)應(yīng)用到信號處理中來,在信號處理系統(tǒng)中引入并行多處理器技術(shù)是必然趨勢。傳統(tǒng)彈載計(jì)算機(jī)一般針對特定場合,先確定算法,再根據(jù)算法確定系統(tǒng)結(jié)構(gòu),由于系統(tǒng)結(jié)構(gòu)與算法嚴(yán)格相關(guān),因此通用性較差。隨著一些標(biāo)準(zhǔn)技術(shù)(標(biāo)準(zhǔn)板型、接口、互聯(lián)協(xié)議等)在彈上控制系統(tǒng)中的應(yīng)用,設(shè)計(jì)標(biāo)準(zhǔn)化、模塊化的通用型計(jì)算機(jī)成為了可行。而且所設(shè)計(jì)的還要可擴(kuò)展、可重構(gòu),進(jìn)而根據(jù)不同的應(yīng)用場合和算法構(gòu)建各種彈載計(jì)算機(jī)系統(tǒng)。
1 并行彈載計(jì)算機(jī)處理結(jié)構(gòu)模型
普遍的兩種并行處理結(jié)構(gòu)如圖1所示,一種是共享總線結(jié)構(gòu),另一種是分布式并行結(jié)構(gòu)。其中,P(Proces-sor):處理器;M(Memory):存儲(chǔ)器;MB(Memory Bus):存儲(chǔ)器總線;NIC(Network Interface Circuitry):網(wǎng)絡(luò)接口電路。共享總線結(jié)構(gòu)中多個(gè)處理器P經(jīng)由高速總線連向共享存儲(chǔ)器,每個(gè)處理器等同地訪問共享存儲(chǔ)器、I/O設(shè)備和操作系統(tǒng)服務(wù)。分布式并行結(jié)構(gòu)中多個(gè)處理節(jié)點(diǎn)通過高通信帶寬、低延遲的定制網(wǎng)絡(luò)互聯(lián),每個(gè)處理節(jié)點(diǎn)都有物理上的分布存儲(chǔ)器,節(jié)點(diǎn)間通過消息傳遞相互作用。
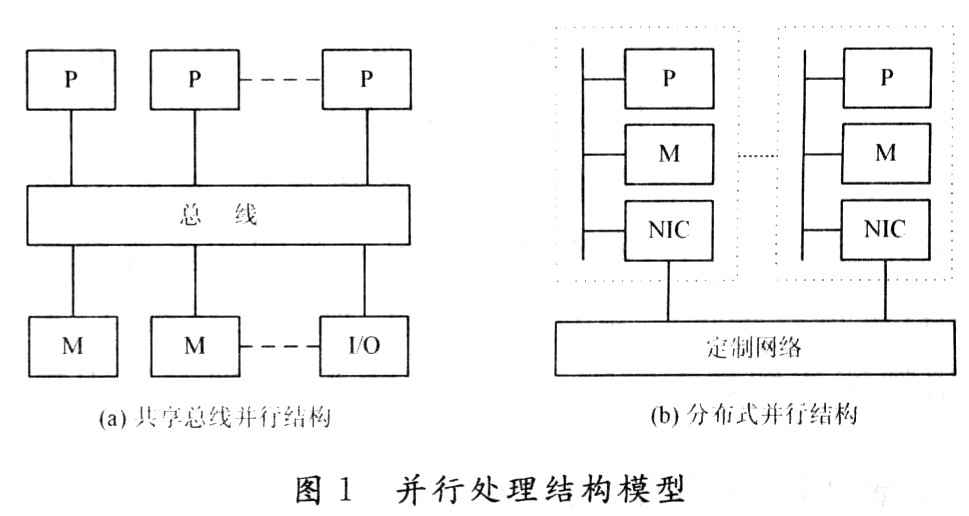
并行處理的目的是采用多個(gè)處理器同時(shí)對任務(wù)處理,從而減小任務(wù)執(zhí)行時(shí)間,它主要反映在加速比(S)和并行效率(E)上。加速比是指對于一個(gè)特定應(yīng)用,并行算法的執(zhí)行速度相對串行算法加快了很多倍。效率則是針對每個(gè)處理器來衡量的。依據(jù)并行處理中可擴(kuò)放性(Sealability)評測的等效率度量標(biāo)準(zhǔn)可從理論上評測這兩種結(jié)構(gòu)。
首先考慮共享總線結(jié)構(gòu)。設(shè)![]() 分別是并行系統(tǒng)上第i個(gè)處理器的有用處理時(shí)間和額外開銷時(shí)間。設(shè)每個(gè)處理器上子任務(wù)的運(yùn)算量和通信量之比為r,即平均r次運(yùn)算中有一個(gè)數(shù)據(jù)需要交換。總線被p個(gè)處理器輪流訪問,tio。是處理器完成一次總線存取所需的相對時(shí)間,等效為處理器運(yùn)算能力和總線訪問能力之比。一般情況下,總的處理時(shí)間和額外開銷時(shí)間如下:
分別是并行系統(tǒng)上第i個(gè)處理器的有用處理時(shí)間和額外開銷時(shí)間。設(shè)每個(gè)處理器上子任務(wù)的運(yùn)算量和通信量之比為r,即平均r次運(yùn)算中有一個(gè)數(shù)據(jù)需要交換。總線被p個(gè)處理器輪流訪問,tio。是處理器完成一次總線存取所需的相對時(shí)間,等效為處理器運(yùn)算能力和總線訪問能力之比。一般情況下,總的處理時(shí)間和額外開銷時(shí)間如下:
![]()
假設(shè)任務(wù)均勻分成p部分,就有:Te=pt。在最壞情況下,p個(gè)處理器總是同時(shí)訪問總線,考慮最后得到總線訪問權(quán)的處理器:
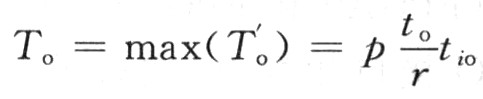
Tp是每個(gè)處理器上并行算法運(yùn)行時(shí)間,在最壞情況下,Tp=Te+To。設(shè)問題規(guī)模W為最佳串行算法完成的計(jì)算量,即W=Te,加速度比:
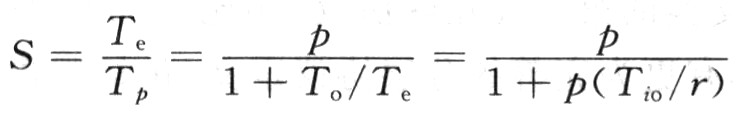
顯而易見,共享總線系統(tǒng)的并行效率隨著處理器數(shù)目p的增大而下降。
而在分布式并行系統(tǒng)中,理想情況下任一時(shí)刻都可有兩個(gè)處理器通過其通信口相互交換數(shù)據(jù),設(shè)一個(gè)通信口傳送一個(gè)數(shù)據(jù)的相對時(shí)間為tcomm,等效為處理器運(yùn)算能力和通信口傳輸能力之比。同時(shí),假設(shè)每次交換還需對本地存儲(chǔ)器訪問。這樣就有通信開銷:
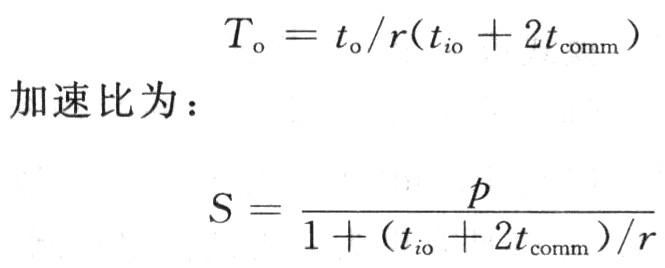
和處理規(guī)模p成線性關(guān)系,并行效率與p無關(guān)。
以上討論的是假設(shè)任意兩個(gè)處理器之間可以直接進(jìn)行數(shù)據(jù)交換,而在實(shí)際情況下,尤其是處理器數(shù)目p多于處理器的通信口數(shù)量時(shí),兩個(gè)非直接相連的處理器之間的數(shù)據(jù)交換所需開銷與其經(jīng)過的路徑成正比關(guān)系。但這并不影響以上討論的公式。因?yàn)樵谝?guī)則網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)中最大或平均路徑是一個(gè)定值n,那么這時(shí),分布式并行系統(tǒng)的加速比公式為:
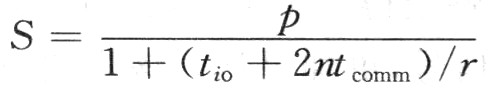
可見,在這種情況下分布式并行系統(tǒng)同樣能獲得線性加速比。由以上理論分析可知,共享總線并行結(jié)構(gòu)適合共享存儲(chǔ)編程模型,進(jìn)行細(xì)粒度的并行處理,但其擴(kuò)展性能較差,處理器的數(shù)目有限,單機(jī)處理性能有限;分布式并行結(jié)構(gòu)采用消息傳遞的機(jī)制,適合進(jìn)行粗粒度的并行處理,便于大規(guī)模的系統(tǒng)擴(kuò)展,提供強(qiáng)大的整體性能。
2 彈載計(jì)算機(jī)的設(shè)計(jì)實(shí)現(xiàn)
由于彈上信號處理算法的復(fù)雜性,信號處理系統(tǒng)具有復(fù)雜多樣的并行處理模式,如基于空間的數(shù)據(jù)并行處理、基于時(shí)間的流水并行處理等。另外,彈上計(jì)算機(jī)系統(tǒng)具有多種類型的數(shù)據(jù)流,如原始數(shù)據(jù)流(A/D采集之后的數(shù)據(jù)流)、中間數(shù)據(jù)流(各處理節(jié)點(diǎn)之間傳遞的數(shù)據(jù)流)、定時(shí)同步信號以及控制數(shù)據(jù)流等。這些不同的數(shù)據(jù)流的傳輸帶寬不同,因此系統(tǒng)中要有與這些不同數(shù)據(jù)流相匹配的互聯(lián)網(wǎng)絡(luò)。
高性能通用并行彈載計(jì)算機(jī)是構(gòu)建信號處理系統(tǒng)的基礎(chǔ)。它除了選用高性能的處理器外,為了具有通用性,還要具有標(biāo)準(zhǔn)化、模塊化、可擴(kuò)展、可重構(gòu)的特點(diǎn),以便構(gòu)建各類控制和信號處理系統(tǒng)。同時(shí)為了適應(yīng)控制和信號處理系統(tǒng)復(fù)雜并行處理模式和多種數(shù)據(jù)流的特點(diǎn),它要具有混合的并行模式和多層次的互聯(lián)網(wǎng)絡(luò)。基于這些要求和上文中對并行處理結(jié)構(gòu)模型的理論分析,筆者選用當(dāng)前業(yè)界最高性能的浮點(diǎn)DSP芯片TS201和大規(guī)模FPGA,設(shè)計(jì)了一個(gè)標(biāo)準(zhǔn)化、模塊化、可擴(kuò)展、可重構(gòu)、混合并行模式、多層次互聯(lián)的高性能通用并行彈載計(jì)算機(jī)。圖2是其結(jié)構(gòu)框圖。
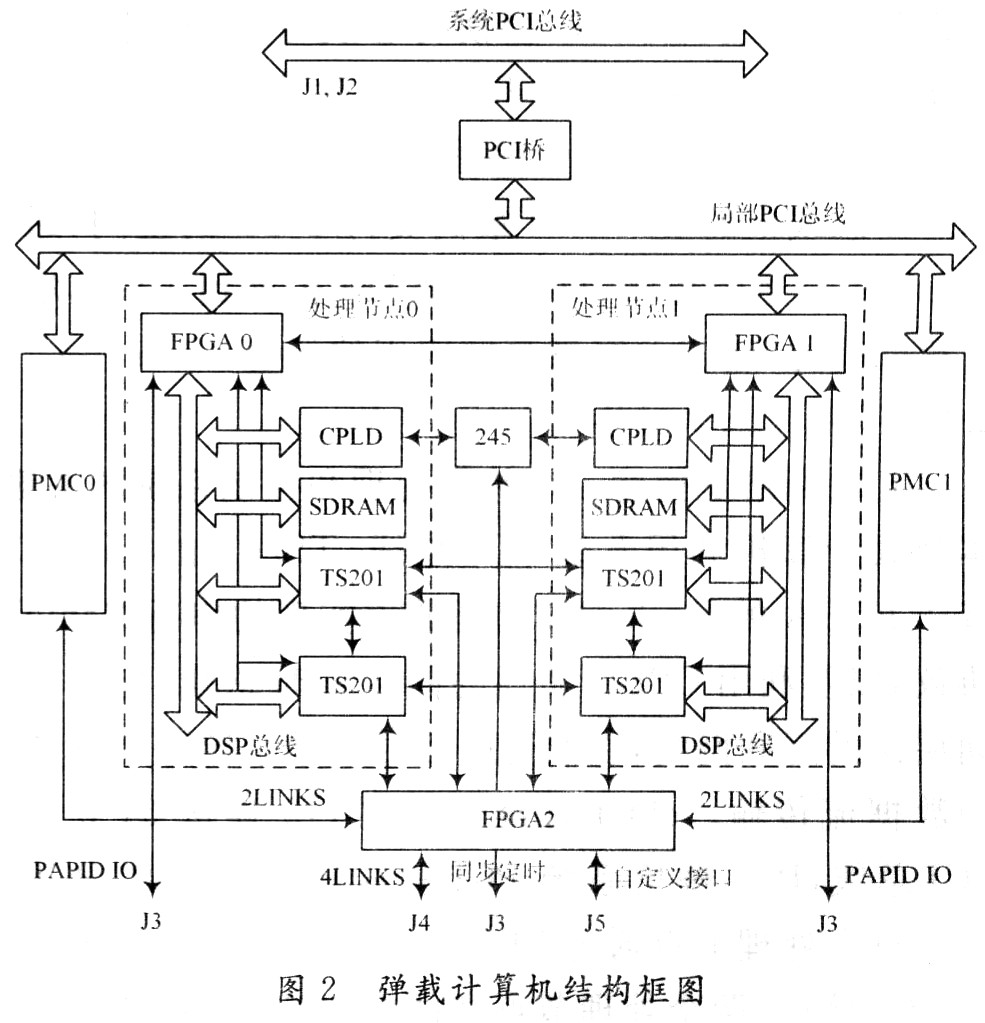
該彈載計(jì)算機(jī)選用標(biāo)準(zhǔn)cPCI 6U板型,板內(nèi)集成了兩個(gè)處理節(jié)點(diǎn),同時(shí)可承載兩個(gè)PMC子板。
2.1 DSP+FPGA共享總線型處理節(jié)點(diǎn)
彈上控制和信號處理系統(tǒng)中,低層的信號處理算法處理的數(shù)據(jù)量大,對處理速度要求高,但運(yùn)算結(jié)構(gòu)相對簡單,適于用FPGA實(shí)現(xiàn),這樣能同時(shí)兼顧速度及靈活性。高層處理算法處理的數(shù)據(jù)量較低層算法少,但算法的控制結(jié)構(gòu)復(fù)雜,適于用運(yùn)算速度高,尋址方式靈活,通信機(jī)制強(qiáng)大的DSP來實(shí)現(xiàn)。
為此,筆者設(shè)計(jì)的彈載計(jì)算機(jī)主要包括DSP,F(xiàn)PGA,SDRAM和CPLD。DSP主要實(shí)現(xiàn)數(shù)據(jù)的高層算法處理和控制,F(xiàn)PGA實(shí)現(xiàn)對外的接口,并可對輸入輸出的數(shù)據(jù)進(jìn)行低層算法預(yù)處理,SDRAM用來緩存數(shù)據(jù),CPLD用來實(shí)現(xiàn)一些輔助邏輯。選用的DSP芯片是ADI公司的TS201,單片處理能力3.6 GFLOPS,內(nèi)核時(shí)鐘頻率600 MHz,片內(nèi)內(nèi)存24 Mb,125 MHz/64 b片外總線,具有1 GB的SDRAM訪問能力,還有4個(gè)Link口,每個(gè)Link口收發(fā)獨(dú)立,最高帶寬為1.2 GB/s。
所有特點(diǎn)都使得TS201適合多片擴(kuò)展,構(gòu)成一個(gè)大規(guī)模高性能的信號處理系統(tǒng)。選用的FPGA芯片為Xilinx公司的VirtexⅡpro系列XC2VP20,它的規(guī)模約200萬門,內(nèi)部集成了1 584 Kb的RAM,88個(gè)18×18 b的乘法器,8個(gè)傳輸速率可達(dá)3.125 Gb/s的Rock-etIO高速通道,這些特點(diǎn)使得該FPGA適合實(shí)現(xiàn)數(shù)據(jù)的傳輸和預(yù)處理。而且它的管腳兼容XC2VP30/40,可實(shí)現(xiàn)FPGA規(guī)模的進(jìn)一步擴(kuò)展。每個(gè)處理節(jié)點(diǎn)包括兩片TS201,一片F(xiàn)PGA,最高4 GB的SDRAM,以及一片CPLD,并共享總線。之所以只用兩片TS201,是考慮到總線上設(shè)備太多,會(huì)使得總線時(shí)鐘頻率降低,帶寬變小,并行度和效率都不高。兩片TS201共享總線充分發(fā)揮了處理能力、傳輸能力、存儲(chǔ)能力的匹配性。TS201總線上的SDRAM最高支持1 GB的空間,通過CPLD進(jìn)行邏輯控制,可使SDRAM擴(kuò)展到4 GB,增加了存儲(chǔ)能力,適應(yīng)大容量存儲(chǔ)應(yīng)用的場合。
2.2 多層次互聯(lián)網(wǎng)絡(luò)
互聯(lián)網(wǎng)絡(luò)是構(gòu)建一個(gè)并行處理和控制系統(tǒng)的關(guān)鍵。本彈載計(jì)算機(jī)利用系統(tǒng)PCI總線、TS201的Link口,基于FPGA的RocketIO物理通道實(shí)現(xiàn)的串行RapidIO協(xié)議,以及利用CPLD實(shí)現(xiàn)的同步定時(shí)總線,構(gòu)成了不同層次的互聯(lián)網(wǎng)絡(luò),以便適應(yīng)信號處理系統(tǒng)中不同類型的數(shù)據(jù)流傳輸。cPCI標(biāo)準(zhǔn)通過J1,J2連接64 b系統(tǒng)PCI總線,PCI橋把系統(tǒng)PCI總線轉(zhuǎn)換為局部PCI總線。每個(gè)處理節(jié)點(diǎn)通過FPGA(FPGA 0和FPGA 1)實(shí)現(xiàn)PCI接口,兩個(gè)處理節(jié)點(diǎn)和兩個(gè)PMC子板共享局部PCI總線,并通過PCI橋與系統(tǒng)PCI總線連接在一起。這使得系統(tǒng)主控模塊可以通過PCI總線實(shí)現(xiàn)對每個(gè)處理節(jié)點(diǎn)以及PMC子板的控制。同時(shí)各個(gè)節(jié)點(diǎn)之間也可通過。PCI總線交換數(shù)據(jù)。但由于總線的限制,只能實(shí)現(xiàn)一些低速、非實(shí)時(shí)的數(shù)據(jù)交換。TS201具有4個(gè)高速Link口,可實(shí)現(xiàn)多片TS201之間的高速數(shù)據(jù)傳輸。對于板內(nèi)的4片TS201,利用各自2個(gè)Link口構(gòu)成1個(gè)環(huán)形Link連接,使得板內(nèi)4片TS201緊密耦合在一起。另外,每片TS201的1個(gè)Link口共4個(gè)Link口連到FPGA 2(稱之為Link Switch)上,同時(shí)每個(gè)PMC的PJ4上也定義兩個(gè)Link口,板卡的J4上定義4個(gè)Link口,所有這些Link口都連到FPGA2上。通過FPGA2,可以靈活地配置板內(nèi)、板內(nèi)與PMC子板、板間不同節(jié)點(diǎn)構(gòu)成不同的Link互聯(lián)網(wǎng)絡(luò),并且可以利用。FPGA的動(dòng)態(tài)加載功能,動(dòng)態(tài)地配置不同的Link互聯(lián)網(wǎng)絡(luò)結(jié)構(gòu)。FPGA2同時(shí)還與J5上的32 b自定義接口連接,可實(shí)現(xiàn)一些用戶自定義接口。同時(shí)每個(gè)處理節(jié)點(diǎn)內(nèi)的2片TS201還有1個(gè)Link口都連到了節(jié)點(diǎn)內(nèi)總線上的FPGA(FPGA0和FPGA1),與該FPGA對外的串行RapidIO接口相配合,實(shí)現(xiàn)外部串行RapidIO數(shù)據(jù)流與TS201內(nèi)部數(shù)據(jù)的交換。Link口具有大帶寬、低延時(shí)的特點(diǎn),因此適合用來傳輸原始數(shù)據(jù)流和一些帶寬大,實(shí)時(shí)性強(qiáng)的中間數(shù)據(jù)流。串行RapidIO是基于包交換的第三代互聯(lián)協(xié)議,相比TS201的Link協(xié)議,它具有更為完善的分層協(xié)議定義(包括邏輯層、傳輸層和物理層)。該協(xié)議使得模塊具有更強(qiáng)的通用性,不僅可以與同類型的各模塊互聯(lián),還可以與任何具有串行RapidIO接口的異構(gòu)模塊互聯(lián)。利用FPGA的Rocke-tIO物理通道,通過FPGA編程可實(shí)現(xiàn)串行RapidIO協(xié)議。FPGA0和FPGA1通過4個(gè)RocketIO通道直接相連,可實(shí)現(xiàn)二者之間4個(gè)1×模式或1個(gè)4×模式的串行RapidIO接口。同時(shí),F(xiàn)PGA0和FPGAl還各自通過4個(gè)RocketIO與J3相連,這樣通過J3,彈載計(jì)算機(jī)就可以以8個(gè)1×模式或2個(gè)4×模式的串行RapidIO接口與其他模塊互聯(lián),構(gòu)成多個(gè)模塊之間的串行Ra-pidIO互聯(lián)網(wǎng)絡(luò)。串行RapidIO網(wǎng)絡(luò)也具有大帶寬的特性,而且相比Link口具有更為完善的協(xié)議控制,但正是由于復(fù)雜的協(xié)議控制,使它的傳輸延時(shí)相比Link口更大。因此,它可與Link網(wǎng)絡(luò)形成很好的互補(bǔ),用來傳輸大帶寬,延時(shí)要求不高的數(shù)據(jù)流。在J3上定義了8 b同步定時(shí)信號,用來實(shí)現(xiàn)各個(gè)節(jié)點(diǎn)之間的同步定時(shí)控制。這些信號通過RS 245驅(qū)動(dòng)后與每個(gè)節(jié)點(diǎn)內(nèi)部的CPLD相連。每片TS201可通過中斷或讀寫寄存器等方式對節(jié)點(diǎn)內(nèi)的CPLD進(jìn)行操作,進(jìn)而通過CPLD內(nèi)部邏輯產(chǎn)生相應(yīng)的同步定時(shí)信號進(jìn)行各個(gè)節(jié)點(diǎn)之間的同步。RS 245的雙向性使得每個(gè)節(jié)點(diǎn)既可以發(fā)出同步信號,也可以接收同步信號,更加靈活。該模塊所有對外的互聯(lián)接口都是通過J1~J5接插件連接,這樣就可以在底板上把各個(gè)模塊之間的各個(gè)接口連接起來。而且既可以使用固定拓?fù)浣Y(jié)構(gòu)的無源底板,也可以使用帶有交換芯片的有源底板或?qū)iT的交換板,靈活構(gòu)建各類互聯(lián)網(wǎng)絡(luò)。
3 應(yīng)用驗(yàn)證
該彈載計(jì)算機(jī)具有通用化、可擴(kuò)展、可重構(gòu)的特點(diǎn)。可根據(jù)不同的需求,通過增減彈載計(jì)算機(jī)來改變處理能力,通過改變各模塊之間的互聯(lián)形式來適應(yīng)不同的算法。下面以基于該彈載計(jì)算機(jī)構(gòu)建數(shù)據(jù)并行的相控陣?yán)走_(dá)信號處理系統(tǒng)來驗(yàn)證這些特點(diǎn)。圖3是以該彈載計(jì)算機(jī)構(gòu)建的某相控陣?yán)走_(dá)信號處理系統(tǒng)結(jié)構(gòu)框圖。
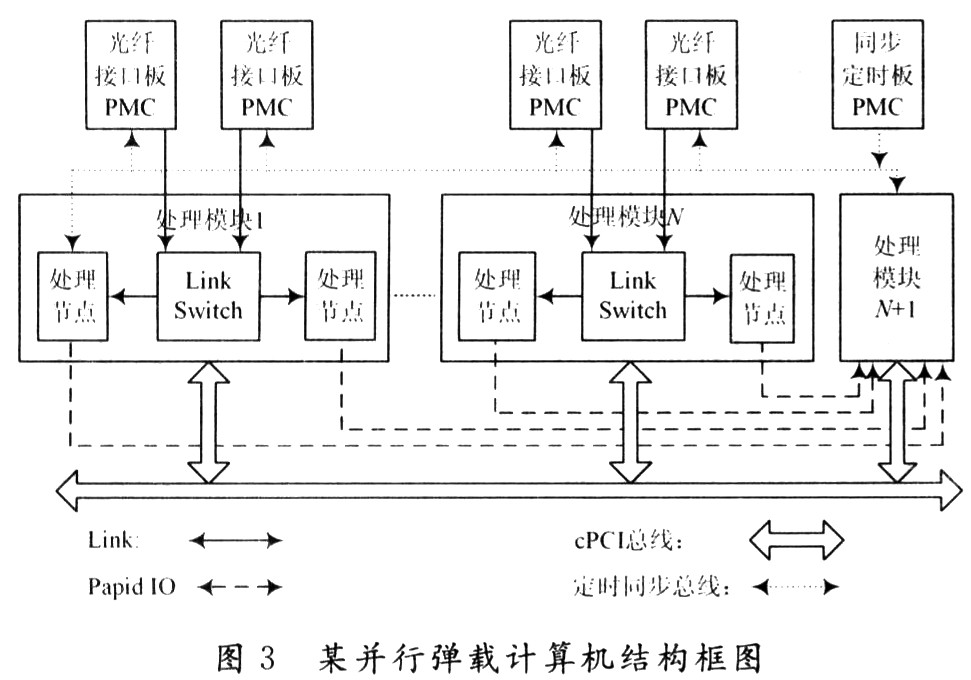
該系統(tǒng)采用光纖與相控陣天線陣列之間傳輸數(shù)據(jù),把光纖接口板做成標(biāo)準(zhǔn)PMC板型,可以集成在彈載計(jì)算機(jī)中。每個(gè)彈載計(jì)算機(jī)集成兩個(gè)光纖接口板,一個(gè)光纖接口板接收一個(gè)子陣的回波數(shù)據(jù),并通過彈載計(jì)算機(jī)上每個(gè)PMC板卡的PJ4上定義的Link口,經(jīng)LinkSwitch把數(shù)據(jù)傳給每個(gè)處理節(jié)點(diǎn)。每個(gè)處理節(jié)點(diǎn)對數(shù)據(jù)進(jìn)行波束形成,然后再把形成的子陣波束通過J3定義的串行RapidIO接口傳給進(jìn)行子陣級波束形成的彈載計(jì)算機(jī)。該模塊進(jìn)行子陣級波束的形成以及其他雷達(dá)信號的處理,并承載PMC板型同步定時(shí)模塊,由其產(chǎn)生系統(tǒng)中各個(gè)模塊的同步定時(shí)信號,使各個(gè)模塊同步工作。該處理系統(tǒng)采用數(shù)據(jù)并行的處理模式,每個(gè)節(jié)點(diǎn)處理一個(gè)子陣的回波,可以通過增減處理節(jié)點(diǎn)來靈活適應(yīng)天線陣列的增減。
4 結(jié) 語
并行計(jì)算機(jī)是解決信號處理控制領(lǐng)域任務(wù)規(guī)模不斷增大、問題不斷復(fù)雜的關(guān)鍵技術(shù)。本文在分析了共享總線和分布式并行兩種并行模型優(yōu)缺點(diǎn)的基礎(chǔ)上,設(shè)計(jì)并實(shí)現(xiàn)了一種適應(yīng)信號處理系統(tǒng)需求的混合并行、多層次互聯(lián)、標(biāo)準(zhǔn)化、模塊化、可擴(kuò)展、可重構(gòu)的高性能通用并行彈載計(jì)算機(jī)。實(shí)際中,使用該彈載計(jì)算機(jī),配合相應(yīng)的I/O模塊,構(gòu)建了多個(gè)相控陣?yán)走_(dá)、合成孔徑雷達(dá)、圖像處理等彈載計(jì)算機(jī)系統(tǒng),獲得了廣泛的應(yīng)用,驗(yàn)證了該彈載計(jì)算機(jī)的高性能、通用性。