
摘 要: 設(shè)計了一種基于FPGA平臺的并行處理" title="并行處理">并行處理流水線結(jié)構(gòu),配合高速查表" title="查表">查表,可支持10Gbps" title="10Gbps">10Gbps接口的報文轉(zhuǎn)發(fā)。該設(shè)計已應(yīng)用在國家863計劃重大課題“可擴展到T比特的高性能IPv4/v6路由器基礎(chǔ)平臺及實驗系統(tǒng)”中,并通過測試。
關(guān)鍵詞: 并行處理 流水線 轉(zhuǎn)發(fā)引擎
當(dāng)前,線路傳輸技術(shù)發(fā)展迅速,光傳輸技術(shù)更是進步飛速,無論是單波長載荷速率還是單纖可用波長數(shù)量,都以驚人的速度增長。目前,已出現(xiàn)各種10Gbps的接口類型,如POS、LAN、WAN等。作為T比特路由器的核心部分,轉(zhuǎn)發(fā)引擎" title="轉(zhuǎn)發(fā)引擎">轉(zhuǎn)發(fā)引擎的線速報文轉(zhuǎn)發(fā)能力決定了路由器所能夠支持的最高端口速率。T比特路由器中線速轉(zhuǎn)發(fā)引擎必須支持10Gbps接口,而傳統(tǒng)的報文處理結(jié)構(gòu)由于單包處理時間過長,已無法滿足線速轉(zhuǎn)發(fā)的性能需求。
1 線速轉(zhuǎn)發(fā)引擎的結(jié)構(gòu)設(shè)計
轉(zhuǎn)發(fā)引擎是高性能T比特路由器的關(guān)鍵部分之一,其設(shè)計的合理性、性能的優(yōu)劣直接影響路由器的整體性能。當(dāng)前,業(yè)界的硬件轉(zhuǎn)發(fā)引擎主要有兩種方案:一種是基于網(wǎng)絡(luò)處理器" title="網(wǎng)絡(luò)處理器">網(wǎng)絡(luò)處理器的轉(zhuǎn)發(fā)引擎,一種是基于FPGA平臺的轉(zhuǎn)發(fā)引擎。本設(shè)計采用FPGA作為設(shè)計平臺,如此選擇主要是出于以下兩點考慮:
(1)目前支持端口速率為10Gbps的線速處理的商用網(wǎng)絡(luò)處理器還不成熟,尤其是沒有自主知識產(chǎn)權(quán)、安全性弱、受芯片提供商的制約,所以網(wǎng)絡(luò)處理器并不是最佳選擇;
(2)采用FPGA是為設(shè)計單片轉(zhuǎn)發(fā)系統(tǒng)(SOC)奠定基礎(chǔ),最終目的是要實現(xiàn)我國自主的高性能網(wǎng)絡(luò)處理器。
數(shù)據(jù)包的10Gbps線速轉(zhuǎn)發(fā),報文轉(zhuǎn)發(fā)率達到31.25Mpps以上,支持IPv4、IPv6和MPLS三種類型報文的處理,支持IPv4、IPv6優(yōu)先級分類,支持組播以及1M路由表項等,都是T比特路由器必須實現(xiàn)的關(guān)鍵技術(shù)指標(biāo)。為此,10Gbps線速轉(zhuǎn)發(fā)引擎采用基于大規(guī)模FPGA、TCAM和SRAM的全硬件流水并行結(jié)構(gòu),利用硬件的高速特性和高可靠性,實時處理路由分組的各項信息并對路由分組進行硬件線速轉(zhuǎn)發(fā)。
下面給出一種基于FPGA的轉(zhuǎn)發(fā)引擎結(jié)構(gòu),該引擎采用并行處理方式和流水線結(jié)構(gòu),有效地降低了報文的處理時間,實現(xiàn)了對多協(xié)議報文的支持,達到了10Gbps線速轉(zhuǎn)發(fā)的性能需求。
2 并行處理結(jié)構(gòu)的設(shè)計
并行機制就是對同一段時間內(nèi)需要處理的每個任務(wù)各采用一個處理通道的并行方式進行操作,從而使多個任務(wù)所需的處理時間降至最少。轉(zhuǎn)發(fā)引擎要進行報頭分析、QoS實現(xiàn)、安全檢測、直連檢查、單播查表、組播查表等處理。并行處理方式就是按照各個功能模塊之間在處理順序上的關(guān)聯(lián)性,將以上的功能模塊進行并行處理;并盡可能對并行技術(shù)進行進一步挖掘。以報頭分析模塊為例,可進一步分為版本號檢查、TTL檢查、地址范圍檢查、有效負(fù)載長度檢查等四個小模塊,進而進行小模塊的并行處理。并行處理結(jié)構(gòu)如圖1所示。
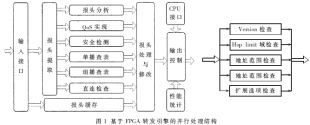
采用并行處理技術(shù)之后的總處理時間只是其中關(guān)鍵并行模塊的處理時間,關(guān)鍵并行模塊是指所有并行處理模塊中處理時間最長的模塊。
3 流水線機制的設(shè)計
若要在數(shù)據(jù)速率高達10Gbps的條件下實現(xiàn)IPv6最短包(長度為40字節(jié))的線速轉(zhuǎn)發(fā),則轉(zhuǎn)發(fā)引擎處理一個數(shù)據(jù)包的最長時間為:IP報文長度(字節(jié))×8(比特)/端口速率(Gbps)=40×8/10=32ns。即使采用100MHz的時鐘,處理時間也只有3.2個周期,要在如此短的時間里完成復(fù)雜的IP報文處理,必須采用流水線設(shè)計。
3.1 系統(tǒng)級流水線
基于FPGA的轉(zhuǎn)發(fā)引擎內(nèi)部各大模塊間的流水線,本文稱為系統(tǒng)級流水線。轉(zhuǎn)發(fā)引擎的系統(tǒng)級流水線結(jié)構(gòu)如圖2所示。
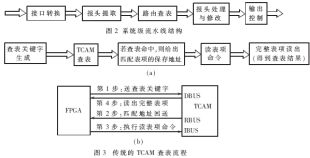
該流水線結(jié)構(gòu)將轉(zhuǎn)發(fā)處理分為接口轉(zhuǎn)換、報頭提取、路由查表、報頭處理與修改、輸出控制等五個流水操作子進程。它們都是在時間上先后執(zhí)行的串行任務(wù)單元,且前后子進程之間的操作相互獨立。轉(zhuǎn)發(fā)引擎采用流水線操作以后,只要各子進程能滿足給定接口速率下最短報文的處理時間要求,則整個轉(zhuǎn)發(fā)引擎就支持該接口速率。
3.2 流水線查表設(shè)計
在該流水線各段中,需要時間最長的功能段為路由查表。在查表模塊進一步引入流水線設(shè)計,可以減少整個轉(zhuǎn)發(fā)處理的流水時間,使之能夠滿足路由器性能要求。
硬件查表通常由TCAM完成,傳統(tǒng)的TCAM查表流程如圖3所示。
傳統(tǒng)查表由TCAM搜索和TCAM讀表項兩個操作串行進行,無流水線操作,整個過程需要十幾個時鐘周期。
在本文提出的由TCAM和SRAM共同完成路由查表的流水線結(jié)構(gòu)中,查表分兩級進行:由TCAM完成搜索過程,再由SRAM讀出查表結(jié)果。這樣可將查表時間縮短為4個周期。
在本流水查表方案中,TCAM表項僅存儲查表關(guān)鍵字,查表結(jié)果則存儲在SRAM的相應(yīng)地址空間中。對于單播查表,目的IP地址作為查表關(guān)鍵字保存在TCAM的某個地址中,目的接口號作為查表結(jié)果則保存在SRAM中的相應(yīng)地址空間中,這樣就構(gòu)成一條完整的單播表項。其流程如圖4所示。
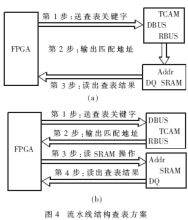
圖4給出了兩種流水線設(shè)計方案,它們的區(qū)別主要在于是否將TCAM的RBUS直接連接到SRAM的地址總線上。
(1) 方案(a)是將TCAM的RBUS直接作為SRAM的讀取地址,優(yōu)點是PCB制作略為簡單,減少FPGA中User I/O資源緊張的問題,缺點是寫表項的時間較長。因為寫SRAM表項必須通過相應(yīng)的TCAM操作才能進行,即寫TCAM表項和寫SRAM表項均通過TCAM來完成,所以寫一條完整表項的時間為二者處理時間之和。
(2)方案(b)是將TCAM的結(jié)果總線RBUS與SRAM的地址總線通過FPGA連接起來,雖然增加了PCB制作的難度,但由于寫表項時TCAM和SRAM的寫操作可同時進行,因而寫一條完整表項的時間為這二者處理時間的較大值。通常TCAM的讀寫時間遠(yuǎn)大于SRAM的讀寫時間。
通過TCAM寫SRAM表項的時間往往與單獨寫TCAM表項的時間相當(dāng),即方案(a)寫表項的時間大大超過方案(b),因而方案(b)具有更好的線速轉(zhuǎn)發(fā)性能。
4 工程實現(xiàn)
通過采用并行處理技術(shù)和流水線技術(shù)設(shè)計的轉(zhuǎn)發(fā)引擎在實際工程中得到了很好的應(yīng)用,工程中采用的FPGA為VIRTEX PRO系列的XC2VP70芯片。借助思博倫通信公司(Spirent Communications)的Adtech AX/4000網(wǎng)絡(luò)測試儀構(gòu)造的測試環(huán)境如圖5所示。

圖5中,測試儀與10GPOS線卡相連,雙向發(fā)送與接收數(shù)據(jù),線卡將10Gbps數(shù)據(jù)輸入轉(zhuǎn)發(fā)引擎,再由轉(zhuǎn)發(fā)引擎送往高速交換網(wǎng)絡(luò)。在測試過程中,選擇40、64、128、256、512、1024、1280和1500字節(jié)的定長包進行分組轉(zhuǎn)發(fā)率和丟包率測試。測試表明,在10G VAN和10G LAN接口下,轉(zhuǎn)發(fā)引擎不丟包,即丟包率為0。在10GPOS接口下,轉(zhuǎn)發(fā)引擎的吞吐率和丟包率如圖6所示。
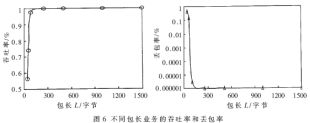
圖中表明,在單一包長測試條件下,在負(fù)荷為100%、包長大于等于109.5字節(jié)時的丟包率低于1.07×10-6%,吞吐率接近于1%,該轉(zhuǎn)發(fā)引擎可以實現(xiàn)40字節(jié)IPv6報文的10Gbps線速轉(zhuǎn)發(fā)。
在測試過程中,還做了模擬實際應(yīng)用的混合包傳輸(40字節(jié)包占25%,172字節(jié)包占20%,360字節(jié)包占15%,552字節(jié)包占20%,1500字節(jié)包占20%)測試。圖7表示在模擬實際包長分布條件下,不同負(fù)荷時的轉(zhuǎn)發(fā)引擎丟包率。
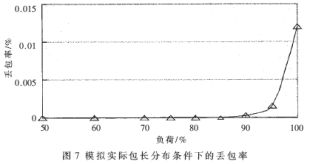
圖中所示的測試結(jié)果表明,端口負(fù)荷低于90%時,丟包率低于3.0×10-4%。以上結(jié)果表明,該轉(zhuǎn)發(fā)引擎能實現(xiàn)100%報文通過率的10Gbps線速轉(zhuǎn)發(fā)。
10Gbps線路接口的出現(xiàn),對轉(zhuǎn)發(fā)引擎的設(shè)計是個極大的挑戰(zhàn):在不到4個時鐘周期的時間內(nèi),需要實現(xiàn)各種協(xié)議類型的報文的線速轉(zhuǎn)發(fā)。本文提出的一種基于FPGA的并行流水線轉(zhuǎn)發(fā)引擎結(jié)構(gòu),很好地解決了10Gbps線速轉(zhuǎn)發(fā)的問題。該引擎結(jié)構(gòu)已經(jīng)應(yīng)用在863重大課題“可擴展到T比特的IPv4/v6 路由器基礎(chǔ)平臺及實驗系統(tǒng)”中,并通過了測試。
隨著線路傳輸技術(shù)的發(fā)展,鏈路接口速率即將突破40Gbps,這對轉(zhuǎn)發(fā)引擎的結(jié)構(gòu)設(shè)計又將是進一步的挑戰(zhàn),研究支持40Gbps的線速轉(zhuǎn)發(fā)引擎將是我們下一步的研究方向。
參考文獻
1 Howard Johnson and Martin Graham Prentice Hall. High-Speed Digital Design.ISBN 0-13-395724-1,1993[M]
2 P.Newman,G.Minshall and L.Huston.IP Switching and Giga-bit Routers. IEEE Communications Magazine, 1997;(1)[J]
3 Synopsys Design Analyzer. Manuals for SYNOPSYS Toolset[Z]. Synopsys Inc.,2000
4 Netlogic Microsystems.http://netlogicmicro.com
5 許恪,熊勇強,吳建平.寬帶IP路由器的體系結(jié)構(gòu)分析,軟件學(xué)報,2000;(3):1~8