
??? 摘 要: 3D" title="3D">3D圖形硬件加速中,紋理映射屬于像素處理階段,透視校正中的紋理地址計(jì)算的特點(diǎn)是計(jì)算量大,且有實(shí)時(shí)性要求。本文設(shè)計(jì)了一個(gè)流水線脈動陣列" title="脈動陣列">脈動陣列結(jié)構(gòu)來提高數(shù)據(jù)吞吐量。陣列的處理器單元(PE)為基于IEEE 754單精度" title="單精度">單精度的32位浮點(diǎn)乘累加器" title="累加器">累加器,同時(shí)計(jì)算紋理坐標(biāo)的除法電路也為單精度。
??? 關(guān)鍵詞: 脈動陣列? 處理單元? 紋理映射? FPGA
?
??? 3D圖形處理芯片的性能比任何一種計(jì)算芯片的發(fā)展都要快,幾乎所有的PC系統(tǒng)都包括了3D圖形硬件加速技術(shù),以實(shí)現(xiàn)游戲、CAD或可視化等應(yīng)用。隨著移動電子產(chǎn)品市場的發(fā)展,諸如PDA、手機(jī)等產(chǎn)品已開始具有3D游戲等功能,使3D圖形的硬件加速應(yīng)用領(lǐng)域更為廣泛。
??? 計(jì)算機(jī)圖形計(jì)算量都很大,人們尋求各種加速算法來提高運(yùn)算速度。傳統(tǒng)的方法是用更快的處理器,并行算法或?qū)S糜布kS著數(shù)字技術(shù)的發(fā)展,尤其是可編程邏輯門陣列(FPGAs)的發(fā)展,提供了一種新的加速方法。最近的FGGAs在密度和性能上都有突破性的發(fā)展,加上可重復(fù)編程的特點(diǎn),使得它在高性能、柔性應(yīng)用平臺上非常有吸引力[1][2][7]。
??? 在圖形加速運(yùn)算中,紋理貼圖屬于光柵化處理流水線進(jìn)程,這一進(jìn)程的主要特點(diǎn)是要處理大量的像素,數(shù)據(jù)吞吐量大。對實(shí)時(shí)處理系統(tǒng)來說,轉(zhuǎn)換速度是一個(gè)關(guān)鍵參數(shù),為獲得轉(zhuǎn)換速度,流水線結(jié)構(gòu)的選擇顯得很重要。
??? 脈動陣列在大吞吐量加速運(yùn)算中是個(gè)很好的方案,對特定的重復(fù)計(jì)算工作,以數(shù)據(jù)并行結(jié)構(gòu)方式,混合空間時(shí)間計(jì)算,流水線處理,局部通訊來獲得最大可能性能。有規(guī)則的脈動陣列結(jié)構(gòu)可以縮短設(shè)計(jì)時(shí)間,對特定目的能得到最優(yōu)化結(jié)果,相對于普通的結(jié)構(gòu),可以獲得較好的開銷與性能比。
??? 本文設(shè)計(jì)了一個(gè)用于3D紋理映射中的透視校正紋理地址計(jì)算的高性能、全并行浮點(diǎn)數(shù)運(yùn)算脈動陣列電路,包含32位單精度浮點(diǎn)乘累加器和除法器,并給出最終的實(shí)驗(yàn)結(jié)果和性能分析。
1 透視校正紋理映射
1.1 紋理映射技術(shù)
??? 紋理映射是給計(jì)算機(jī)產(chǎn)生的3D圖形表面貼上各種紋理圖像,以提高圖形的真實(shí)感。
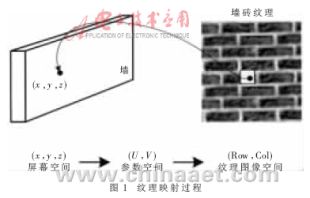
??? 在各種紋理映射方法中,一個(gè)主要的運(yùn)算就是找出屏幕空間像素(x,y,z)在紋理空間所對應(yīng)的紋理元素所在存儲空間的地址(Row,Col),然后將所選中的紋理元素顏色進(jìn)行濾波,并用這個(gè)值替換屏幕空間的像素顏色值,從而完成紋理映射。這個(gè)過程通常稱為兩步紋理映射方法。也就是說,先將屏幕空間的像素坐標(biāo)轉(zhuǎn)換到參數(shù)空間(U,V),再由參數(shù)空間轉(zhuǎn)換到紋理圖像空間。圖1就是一個(gè)給墻壁貼磚紋理的過程。
???????????????? 
1.2 紋理映射單元的矩陣運(yùn)算
??? 本文只考慮由屏幕空間到紋理空間的轉(zhuǎn)換,它是一個(gè)全浮點(diǎn)運(yùn)算,參數(shù)空間到紋理空間的轉(zhuǎn)換則是兩個(gè)定點(diǎn)乘運(yùn)算。
??? 最典型的紋理映射是透視映射,映射函數(shù)一般用式(1)表示[1]:
??? 
??? 式(1)中:(x,y)為二維屏幕像素坐標(biāo);(U,V)為二維紋理參數(shù)空間的坐標(biāo),一般也稱為紋理地址;A~I(xiàn)為轉(zhuǎn)換系數(shù),對于透視映射,I值為1。
??? 這種運(yùn)算通常是用像素矩陣與轉(zhuǎn)換矩陣相乘來計(jì)算紋理元素地址的。矩陣形式表示為式(2),式(3)為坐標(biāo)轉(zhuǎn)換。
??? 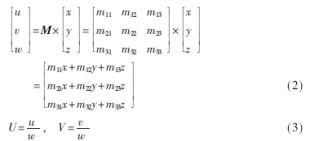
??? 式(2)中:(x,y,z)和(u,v,w)分別為屏幕像素地址和紋理空間地址的齊次坐標(biāo),透視映射時(shí),z值為1。矩陣M為3×3轉(zhuǎn)換矩陣,矩陣元素mij分別對應(yīng)參數(shù)A~I(xiàn)。各紋理地址的計(jì)算事實(shí)上是一個(gè)(A×B+C)的乘累加計(jì)算。
??? 紋理地址的計(jì)算是一個(gè)連續(xù)增量掃描屏幕空間像素的過程。設(shè)像素坐標(biāo)為(xi,yi,zi),對應(yīng)的紋理坐標(biāo)則為(ui,vi,wi)。
2 矩陣運(yùn)算的陣列結(jié)構(gòu)
??? 對于光柵化處理流水線進(jìn)程,為獲得大的數(shù)據(jù)吞吐量和滿足實(shí)時(shí)處理要求的轉(zhuǎn)換速度,基于流水線結(jié)構(gòu)的矩陣電路是一種極好的選擇。
2.1 陣列結(jié)構(gòu)
??? 正交脈動陣列能很好地完成正方形矩陣乘操作。一個(gè)M×N的矩陣A=[Aij](1
??? 
??? 如果矩陣的維數(shù)為n,需要n2個(gè)微處理器單元(PE)。對于紋理地址計(jì)算,相乘矩陣的維數(shù)分別是3×3和3×1,所以矩陣陣列為3×3,共9個(gè)PE單元,如圖2。處理器單元PEij是單精度浮點(diǎn)乘累加器,完成矩陣元素乘及與前一級輸出的累加。圖2中(xi,yi,zi)的輸入方式,事實(shí)上是通過FIFO堆棧,對應(yīng)周期依序輸入(x1,0,0),(x2,y1,0),(x3,y2,z1)……。
??????????????? 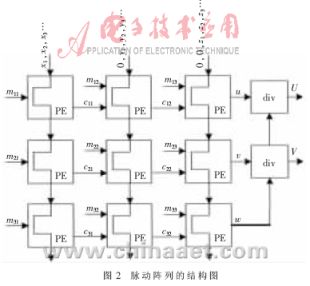
??? 3×3陣列完成齊次坐標(biāo)(u,v,w)計(jì)算后,還要再完成笛卡爾坐標(biāo)轉(zhuǎn)換(U,V)=(u/w,v/w),所以最后還要兩個(gè)單精度的浮點(diǎn)除法器(Div)。
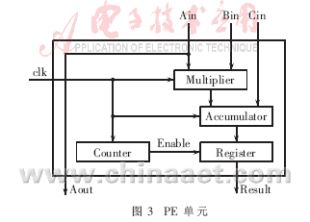
2.2 PE單元[2]
??? PE單元的結(jié)構(gòu)圖如圖3所示,主要單元是由兩個(gè)IEEE754 32位單精度浮點(diǎn)乘法器" title="乘法器">乘法器和累加器組成,乘法器完成A×B運(yùn)算,再由累加完成A×B+C運(yùn)算。用一個(gè)寄存器來控制各PE單元之間數(shù)據(jù)傳輸節(jié)奏。寄存器的數(shù)據(jù)是在Enable信號有效時(shí)輸出,以保證流水線的節(jié)奏。Enable信號的產(chǎn)生是通過對時(shí)鐘信號進(jìn)行計(jì)數(shù)得到的。這里乘法器和加法器同樣采用流水線結(jié)構(gòu),乘法器一個(gè)周期,累加器兩個(gè)周期,所以Enable信號在三個(gè)周期結(jié)束后發(fā)出有效信號,PE運(yùn)算結(jié)果輸出到下一級PE單元Cin。
???????????????????? 
??? 在圖2的陣列結(jié)構(gòu)中,PE單元的Ain、Bin和Cin分別與x(或y、z)、m及c對應(yīng)。圖4所示為PE單元的仿真波形。結(jié)果顯示,每個(gè)PE單元輸出結(jié)果要三個(gè)周期。表1為測試輸入輸出數(shù)據(jù),便于比較。
????????????????????????? 
????????????????????? 
3 結(jié)果及分析
??? 整個(gè)電路用VHDL設(shè)計(jì),設(shè)計(jì)仿真平臺為Xilinx的ISE 7.1i,使用VitrtexE xcv1000efg900-8器件,綜合工具用XST。數(shù)據(jù)采用IEEE 754的32位單精度浮點(diǎn)數(shù)標(biāo)準(zhǔn)。
3.1 性能分析
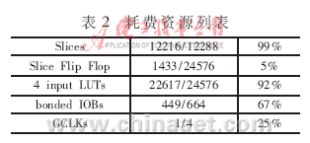
??? 表2為電路綜合后所耗資源,各單元的頻率綜合結(jié)果見表3,乘累加模塊的頻率最低,為41.145MHz,共有9個(gè)PE單元,則可以達(dá)到740.61MFlop/s及82.29MPixels/s數(shù)據(jù)吞吐量。脈動陣列每一行數(shù)據(jù)從輸入到輸出共需12個(gè)周期。如果一個(gè)屏幕分辨率為1280×720,每秒刷新60幀[6],則所需的運(yùn)算速度僅為55.296MPixels/s,因此最終的設(shè)計(jì)在速度上滿足實(shí)時(shí)性的要求。
???????????????????? 
?????????????????????? 
3.2 仿真結(jié)果
??? 圖5為整個(gè)電路的仿真結(jié)果,輸入輸出數(shù)據(jù)以32位浮點(diǎn)格式表示,mij為轉(zhuǎn)換矩陣的元素,x、y、z為像素坐標(biāo),U、V為紋理坐標(biāo)。從表3及圖5可以看出,每個(gè)PE單元需3個(gè)周期,每陣列行為3個(gè)PE單元,加上除法器3個(gè)周期,這樣整個(gè)流水線共需12個(gè)周期完成。輸入的驗(yàn)證矩陣為式(5),輸出結(jié)果U=0.0471,V=0.0391。
??? 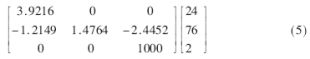
???????????? 
???? 本文設(shè)計(jì)了基于IEEE 754單精度32位浮點(diǎn)數(shù)運(yùn)算的脈動陣列,用于3D圖形硬件加速中的紋理透視校正的紋理地址計(jì)算,最后給出了FPGA的硬件實(shí)現(xiàn)方案。仿真綜合的結(jié)果表明電路可以在41.145MHz頻率下運(yùn)行,達(dá)到740.61MFlop/s及82.29MPixel/s數(shù)據(jù)吞吐量,流水線輸入輸出共12個(gè)周期。
參考文獻(xiàn)
[1] Tomas Akenine-Moller著,普建濤譯.實(shí)時(shí)計(jì)算機(jī)圖形學(xué)(第二版)[M].北京:北京大學(xué)出版社,2004.
[2] GEORGE M,PAPADOURAKIS,GEORGE N.B.The design?of a systolic architecture to implement graphic transformations[J],CompEuro′91.′Advanced Computer Technology,Reliable Systems and Applications′.5th Annual Europe?Computer Conference. Proceedings.13-16 1991(5).
[3] John P.Uyemurq著,周潤德譯.超大規(guī)模集成電路與系統(tǒng)導(dǎo)論[M].北京:電子工業(yè)出版社,2004.
[4] 吳金,應(yīng)征.高速浮點(diǎn)乘法器設(shè)計(jì)[J].電路與系統(tǒng)學(xué)報(bào),2005,10(6).
[5] SEIDEL P M,EVEN G,Delay-Optimized Implementation of IEEE Floating-Point Addition[J].IEEE Transactions on?Computers,2004,53(2).
[6] Fadi Chehim,Paul Coulton,Reuben Edwards,Evolution of?3D games on mobile phones[J].Proceedings of the international conference on mobile business(ICMB′05),2005(6),11-13.