
0 引言
隨著網(wǎng)絡(luò)流量的不斷增加和路由表容量的不斷增大,路由查找已經(jīng)成為制約因特網(wǎng)的主要瓶頸。盡管采用CIDR技術(shù)能產(chǎn)生聚集路由,但路由器的路由表項還是很大,使得路由查找成為高,速路由器的瓶頸。因此,提高路由查找速度已成為高速路由器的關(guān)鍵技術(shù)。
目前實現(xiàn)路由查表的方法主要有軟件和硬件兩類。其中基于軟件查表方法的查找次數(shù)最少為5次,這顯然已經(jīng)不能滿足高速鏈路的要求;而基于Cache的查找方法,其查找依賴于流量的模式,即IP數(shù)據(jù)流具有局部性,隨著網(wǎng)絡(luò)數(shù)據(jù)量的增大,命中率也會降低。而基于硬件的Stanford算法則結(jié)構(gòu)簡單,易于硬件實現(xiàn),而且查找速度快,其最少需要訪問一次存儲器,最多需要訪問2次存儲器。但其占用存儲空間大(為33 MB),表項更新單元數(shù)多。在最壞情況下,更新一個表項需要操作64 k個存儲單元。
本文采用多表結(jié)構(gòu),將查找過程分為4級。
因為采用串行查找實現(xiàn)時,查找一個IP數(shù)據(jù)包最少需要訪問一次存儲器,最多需要訪問4次。而根據(jù)四塊存儲器獨立工作的特性,采用流水線的方式進(jìn)行并行化設(shè)計,則可以保證訪問一次存儲器就能完成一次數(shù)據(jù)包的查找。為了保證占用較小的空間且四個存儲塊的容量相對均衡,本文用一個動態(tài)規(guī)劃算法來求解四個目標(biāo)層的值。此外,這種設(shè)計結(jié)構(gòu)也支持動態(tài)更新,并且更新單元數(shù)較少。
1 查找算法
本系統(tǒng)的基本算法采用分段查找及前綴擴(kuò)展技術(shù)來將IPv4的32位IP地址分成4段,假設(shè)i是其中一段(1≤i≤4),length i代表第i段所對應(yīng)的IP地址長度。每一段內(nèi)容存儲在一塊物理地址連續(xù)的內(nèi)存區(qū)域中,稱為TBLi。那么,在第一段區(qū)域TBL1中,使用前綴擴(kuò)展技術(shù),即可把所有長度小于等于length1的前綴擴(kuò)展成長度為length1的前綴。圖1所示是該四級路由算法的結(jié)構(gòu)框圖。
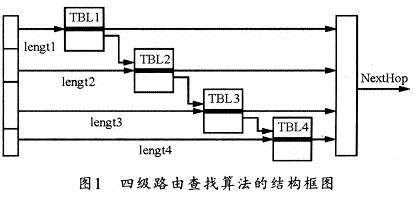
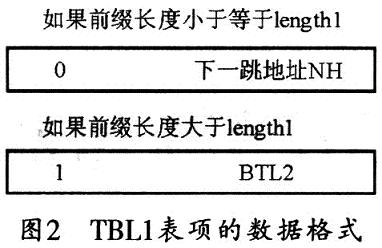
顯然,該結(jié)構(gòu)中的第一段有2length1個表項,析出IP地址的前l(fā)ength1位的值為第一塊內(nèi)存的偏移地址,其對應(yīng)表項的數(shù)據(jù)格式如圖2所示。若前綴長度小于等于length1,則表項的第一位標(biāo)識為0,其余bit位表示下一跳的轉(zhuǎn)發(fā)信息。若前綴長度大于length1,則表項的第一位標(biāo)識為1,其余位填寫擴(kuò)展表的索引值可以作為指向TBL2的指針。在其余的三個段中,可采用同樣的方法進(jìn)行前綴擴(kuò)展。
本算法的查找過程是在匹配一個IP地址時,從第一段開始進(jìn)行分段查找,每查找一段,則解析出對應(yīng)段長度的IP,并取相應(yīng)內(nèi)存區(qū)域的地址。例如進(jìn)行第二段查找時,可將其值作為偏移量,再加上相應(yīng)的基址,就可獲得該段對length1+1位開始,然后解析出length2長度的IP地址作為偏移量。之后再用TBL1表項里的索引,將其左移length2位作為基址,這樣就確定了第二塊連續(xù)存儲區(qū)域中的地址。依次類推,分段查找,直到找到下一跳地址為止。
本算法的插入過程與查找過程相似,先根據(jù)前綴對應(yīng)的分段和索引查找到對應(yīng)的子表,然后在其涉及的范圍內(nèi)讀取各個表項,再根據(jù)表項的值確定是否用新的路由前綴信息覆蓋該表項。如果在此過程中,該表沒有相應(yīng)的段空間,則需分配對應(yīng)的存儲空間。若該段空間為空,則收回該存儲空間。
2 目標(biāo)層的確定
在用NT(k,ω)表示前綴長度為w的情況下,還需要找出k個目標(biāo)層時對應(yīng)的最小前綴擴(kuò)展數(shù)。這樣,其最優(yōu)解就是NT(k,ω)。其遞推公式如下:
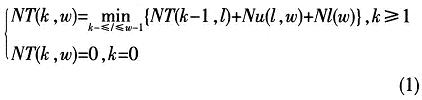
式中,Nu(l,ω)表示將l+1層至ω-1層擴(kuò)展到ω層的前綴數(shù)目,其中若某一層不存在,則將那一層直接忽略。另外,在擴(kuò)展時還要考慮前綴捕獲問題。Nl(ω)是ω層原有的前綴數(shù)目。
3 硬件結(jié)構(gòu)
依據(jù)該算法設(shè)計出的基于4級流水線的并行處理結(jié)構(gòu)如圖3所示,該結(jié)構(gòu)分為存儲器模塊、查找模塊和更新模塊三個部分。4個存儲模塊可存儲對應(yīng)表TBL中的數(shù)據(jù);查找模塊可通過讀取對應(yīng)存儲模塊中的數(shù)據(jù)實現(xiàn)查找;更新模塊則可將要更新的路由信息添加到對應(yīng)的存儲塊中。
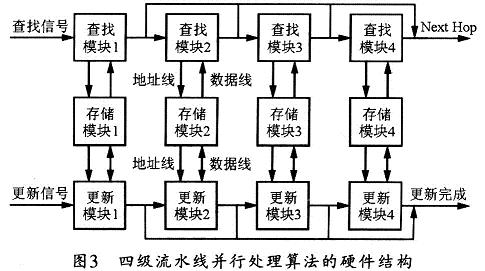
在FPGA設(shè)計時,每個查找模塊都是一個硬件邏輯塊,每兩個查找模塊間都有一個寄存器用以傳輸數(shù)據(jù),每個查找模塊都可從輸入端或寄存器中讀取信息,并解析出IP地址中的相應(yīng)位,然后計算存儲器的訪問地址,訪問存儲器獲取數(shù)據(jù),并將數(shù)據(jù)寫入寄存器或者輸出端。四個查找模塊按流水線的工作方式進(jìn)行處理,能夠達(dá)到訪問一次存儲器處理一個IP數(shù)據(jù)包。
4 實驗結(jié)果分析
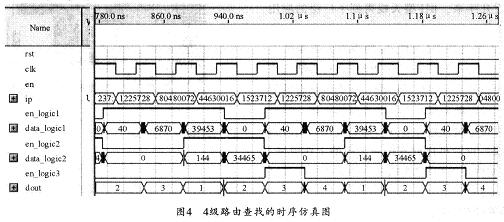
通過對BGP Table中前綴的長度進(jìn)行分析和統(tǒng)計,可模擬生成50,000條前綴。然后用動態(tài)規(guī)劃求出4個目標(biāo)層(20,22,24和32)來進(jìn)行實驗分析。實驗可采用Stratix系列芯片,并利用Ver-ilog硬件描述語言和QuartusII開發(fā)平臺進(jìn)行設(shè)計、綜合、布局布線,然后在靜態(tài)時序分析后進(jìn)行仿真,其時序仿真結(jié)果如圖4所示。由于查找需要一個時鐘周期,而時鐘頻率為100MHz,所以,每秒可以完成100M次查找。若IP分組為40B長,則可以滿足20Gbps的鏈路速率。
5 結(jié)束語
本文給出了一種基于前綴擴(kuò)展的分段快速路由查找算法。該算法可以結(jié)合硬件實現(xiàn)的優(yōu)點,并運用多級流水線處理方法,因而具有查找速度快、支持動態(tài)更新和實現(xiàn)簡單等優(yōu)點,十分適合于20 Gbps核心路由器環(huán)境下的查找機(jī)制。